
Abstract
Introduzione
Imparare a prevedere le ricompense è un notevole adattamento evolutivo che supporta un comportamento flessibile in ambienti complessi e instabili. Quando le circostanze cambiano, la conoscenza acquisita in precedenza può non essere più informativa e il comportamento deve essere adattato per beneficiare di nuove opportunità. Spesso, le alterazioni delle condizioni ambientali non sono segnalate da spunti esterni e possono essere dedotte solo da deviazioni dai risultati previsti, cioè da segnali di sorpresa.
Quando si prendono decisioni, gli esseri umani tipicamente cercano di massimizzare i benefici (cioè la quantità di ricompensa) ricevuti per ogni risorsa investita (cioè, denaro, tempo, sforzo fisico o cognitivo). Noi, come molti altri animali, calcoliamo il valore economico che tiene conto dei premi e dei costi associati alle opzioni comportamentali disponibili e scegliamo l’alternativa che ci si aspetta porti a risultati del valore più alto sulla base di esperienze precedenti in condizioni simili(Padoa-Schioppa e Schoenbaum, 2015; Sugrue et al., 2005). Quando i risultati delle scelte violano costantemente le aspettative, è necessario un nuovo apprendimento per massimizzare l’acquisizione di ricompense. Tuttavia, non tutti i risultati inaspettati sono causati da cambiamenti significativi dell’ambiente. Anche quando le condizioni sono complessivamente stabili, i risultati di una singola esperienza possono essere ancora imprevedibili a causa di piccole fluttuazioni (cioè l’incertezza attesa) nei premi e nei costi. Tali fluttuazioni complicano l’apprendimento guidato dalla sorpresa, poiché gli animali hanno bisogno di distinguere tra i veri cambiamenti dell’ambiente e il feedback stocastico in condizioni altrimenti stabili, noto come il problema della rilevazione dei punti di cambiamento(Courville et al., 2006; Dayan et al., 2000; Gallistel et al., 2001; Pearce e Hall, 1980; Yu e Dayan, 2005).
Sia l’amigdala basolaterale (BLA) che la corteccia orbito-frontale (OFC) partecipano a un comportamento flessibile e reindirizzato. Le rappresentazioni dei risultati attesi possono essere decodificate da entrambe le regioni cerebrali durante il processo decisionale basato sul valore(Conen e Padoa-Schioppa, 2015; Haruno et al., 2014; Padoa-Schioppa, 2007, 2009; Salzman et al., 2007; van Duuren et al., 2009). Le lesioni dell’amigdala rendono gli animali incapaci di seguire in modo adattivo i cambiamenti nella disponibilità di ricompense o di beneficiare di periodi redditizi nell’ambiente(Murray e Izquierdo, 2007; Salinas et al., 1996; Salzman et al., 2007). Inoltre, una recente valutazione della letteratura accumulata sul BLA nel comportamento appetitivo suggerisce che questa regione integra sia il valore attuale della ricompensa che le informazioni storiche a lungo termine(Wassum e Izquierdo, 2015), e quindi può essere particolarmente adatta a guidare il comportamento quando le condizioni cambiano. È importante notare che le risposte a una singola unità di risposta nel BLA tracciano segnali a sorpresa(Roesch et al., 2010) che possono guidare l’apprendimento.
Allo stesso modo, un OFC funzionalmente intatto è necessario per le risposte adattive ai cambiamenti dei valori di risultato(Elliott et al., 2000; Izquierdo e Murray, 2010; Murray e Izquierdo, 2007). I danni prodotti dalle lesioni da OFC sono stati ampiamente attribuiti a una ridotta flessibilità cognitiva o a deficit di controllo inibitorio(Bari e Robbins, 2013; Dalley et al., 2004; Elliott e Deakin, 2005; Winstanley, 2007). Tuttavia, questo punto di vista è stato recentemente messo in discussione dalle osservazioni che le lesioni mediali selettive di OFC causano un potenziale passaggio tra le diverse alternative di opzioni, piuttosto che il mancato disimpegno dal comportamento precedentemente acquisito(Walton et al., 2010, 2011). Infatti, vi è una crescente evidenza che alcuni settori di OFC potrebbero non esercitare un controllo canonico inibitorio sull’azione, ma potrebbero invece contribuire alle rappresentazioni dei risultati previsti da specifici segnali nell’ambiente e aggiornare le aspettative in risposta a feedback sorprendenti(Izquierdo et al., 2017; Marquardt et al., 2017; Riceberg e Shapiro, 2012, 2017; Rudebeck e Murray, 2014; Stalnaker et al., 2015).
Nonostante gli importanti contributi sia del BLA che dell’OFC a diverse forme di apprendimento di valore adattivo, alcuni compiti di apprendimento progrediscono normalmente senza il reclutamento di queste regioni cerebrali. Ad esempio, l’OFC non è richiesto per l’acquisizione di semplici associazioni di stimoli e risultati, sia nel contesto pavloviano che in quello strumentale, o per lo sblocco guidato da differenze di valore quando i risultati sono certi e prevedibili. Tuttavia, l’OFC è necessario per comportamenti adattativi che richiedono l’integrazione di informazioni provenienti da fonti diverse, in particolare quando i risultati attuali devono essere confrontati con una storia in un contesto (o stato) diverso come nei paradigmi di svalutazione(Izquierdo et al., 2004; McDannald et al., 2011, 2005; Stalnaker et al., 2015). Allo stesso modo, come è stato dimostrato nei ratti, il BLA ha un ruolo importante nell’apprendimento precoce o nel processo decisionale in presenza di risultati ambigui(Hart e Izquierdo, 2017; Ostrander et al., 2011), e sembra giocare un ruolo limitato nel comportamento di scelta quando questi risultati sono conosciuti o rafforzati attraverso una formazione estesa. Queste osservazioni accennano a ruoli importanti per BLA e OFC nell’apprendimento in condizioni di incertezza. Tuttavia si sa poco sui contributi unici di queste regioni cerebrali al valore dell’apprendimento quando i risultati sono fluttuanti anche in condizioni di stabilità (cioè quando c’è incertezza attesa nei valori dei risultati). Inoltre, la dissociazione funzionale tra le diverse sottoregioni OFC (ad esempio ventromediale vs. laterale) è attualmente oggetto di dibattito(Dalton et al., 2016; Elliott et al., 2000; Morris et al., 2016).
Modelli computazionali sviluppati di recente basati sull’apprendimento di rinforzo (RL)(Diederen e Schultz, 2015; Khamassi et al., 2011; Preuschoff e Bossaerts, 2007) e i principi dell’inferenza bayesiana(Behrens et al., 2007; Nassar et al., 2010) sono adatti a testare i contributi unici di diverse regioni cerebrali per valutare l’apprendimento sotto l’incertezza. Questi modelli si basano sull’apprendimento in risposta alla sorpresa, o sulla deviazione tra i risultati attesi e quelli osservati (ad esempio, errori di previsione dei premi, RPE); il tasso di apprendimento, a sua volta, determina il grado in cui gli errori di previsione influenzano le stime dei valori. È importante notare che i principi di LR non tengono conto solo del comportamento animale, ma si riflettono anche nell’attività neuronale sottostante(Lee et al., 2012; Niv et al., 2015).
Nel presente lavoro, abbiamo sviluppato per la prima volta un nuovo paradigma comportamentale basato sul ritardo per indagare gli effetti dell’incertezza dei risultati attesi sull’apprendimento nei ratti. Abbiamo dimostrato che i ratti sono in grado di rilevare i veri cambiamenti nei valori di esito anche quando si verificano su uno sfondo di feedback stocastico. Tale complessità comportamentale nei roditori ci ha permesso di valutare i contributi causali del BLA e dell’OFC al valore dell’apprendimento sotto l’incertezza degli esiti attesi. In particolare, abbiamo esaminato i neuroadattamenti che si verificano in queste regioni cerebrali in risposta all’esperienza con diversi livelli di incertezza ambientale e abbiamo impiegato analisi comportamentali a grana fine in collaborazione con la modellazione computazionale delle prestazioni prova per prova degli animali affetti da OFC e BLA nel nostro compito che incorpora sia fluttuazioni prevedibili che spostamenti direzionali nei valori di esito.
Risultati
I ratti possono rilevare cambiamenti reali nei valori nonostante la variabilità dei risultati
Il nostro compito, basato sul ritardo, è stato progettato per valutare la capacità degli animali di rilevare i veri cambiamenti nei valori di risultato (cioè i cambiamenti in salita e in discesa) anche quando si verificano sullo sfondo di un feedback stocastico in condizioni di base (incertezza prevista). Per sondare gli effetti dell’incertezza dell’esito atteso sull’apprendimento nei roditori, abbiamo prima presentato un gruppo di ratti ingenui (n = 8) con due opzioni di scelta identiche nel tempo di attesa medio ma diverse nella varianza della distribuzione dell’esito. Ogni opzione di risposta è stata associata alla consegna di un pellet di zucchero dopo un intervallo di ritardo. I ritardi sono stati messi in comune da distribuzioni identiche nella media, ma diverse nella variabilità (bassa vs alta): LV vs HV; ~N(µ, σ): μ = 10 s, σ HV=4s σ LV=1 s). Dopo aver stabilito una performance stabile (definita come nessuna differenza statistica in nessuno dei parametri comportamentali in tre sessioni di test consecutive, incluse le omissioni di scelta e di avvio, le latenze medie di risposta e la preferenza per le opzioni), i ratti hanno sperimentato incrementi di valore (la media del ritardo è stata ridotta a 5 s con la varianza mantenuta costante) e decrementi (la media del ritardo è stata aumentata a 20 s) su ogni opzione in modo indipendente, seguiti dal ritorno alle condizioni di base(Figura 1A,B; Video 1, Video 2). Ogni turno e fase di base è durata cinque sessioni di test di 60 prove; pertanto, la durata totale del compito principale è stata di 43 giorni di test per ogni animale. I cambiamenti massimi nella scelta di ciascuna opzione in risposta ai turni sono stati analizzati con omnibus all’interno del soggetto ANOVA con il tipo di turno (HV, LV; upshift, downshift) e la fase di turno (pre-shift baseline, shift, post-shift baseline) come fattori interni al soggetto. Queste analisi hanno identificato un significativo tipo di shift x interazione di fase [F(6, 42)=16.412, p<0.0001]. Le analisi post-hoc non hanno rivelato differenze nelle preferenze alle condizioni di base tra le valutazioni [F(3,08, 21,57)=0,98, p=0,422; Greenhouse-Geisser corretto], suggerendo che i ratti sono stati in grado di dedurre i valori medi delle opzioni (tempi di attesa) e mantenere le preferenze di scelta stabili nonostante la variabilità dei risultati.10.7554/eLife.27483.003Figure 1.Task design e le prestazioni degli animali intatti.Il nostro compito è stato progettato per indagare gli effetti dell’incertezza dei risultati previsti sull’apprendimento dei valori.(A) Ogni prova è iniziata con la presentazione degli stimoli nello scomparto centrale del touchscreen. Ai ratti (n = 8) sono stati dati 40 s per iniziare una prova. Se 40 s sono passati senza una risposta, la prova è stata segnata come una “omissione di inizio”. Dopo una puntura al compartimento centrale, lo stimolo centrale è scomparso e due stimoli di scelta sono stati presentati contemporaneamente in ciascuno dei compartimenti laterali dello schermo tattile permettendo ad un animale una libera scelta tra due opzioni di ricompensa. Ad un animale sono stati dati 40 s per fare una scelta; la mancata selezione di un’opzione entro questo intervallo di tempo ha fatto sì che la prova venisse valutata come “omissione di scelta” e l’inizio di un ITI. Ogni opzione di risposta è stata associata alla consegna di un pellet di zucchero dopo un intervallo di tempo.(B) I ritardi associati a ciascuna opzione sono stati messi in comune da distribuzioni che sono identiche nel valore medio, ma diverse nella variabilità: LV (bassa variabilità, mostrata in blu) vs. HV (alta variabilità, mostrata in rosso); ~N(µ, σ): μ = 10 s, σ HV=4s, σ LV=1s. Dopo aver stabilito una prestazione stabile, i ratti hanno sperimentato incrementi di valore (µ = 5 s; σ mantenuto costante) e decrementi (μ = 20 s) su ogni opzione in modo indipendente, seguiti da un ritorno alle condizioni di base. Ogni turno e ritorno alla fase di base è durato per cinque sessioni di 60 prove.(C) Indipendentemente dal tipo di turno, gli animali hanno cambiato significativamente la loro preferenza in risposta a tutti i turni (tutti i valori di p<0,05). Tuttavia, sono state osservate differenze significative tra HV e LV negli adattamenti di scelta sia per i turni in salita che per quelli in discesa: una maggiore varianza della distribuzione dei risultati alla linea di base ha facilitato l’adattamento comportamentale in risposta ai turni in salita (differenza HV vs LV, p=0,004), ma ha reso gli animali non ottimali durante i turni in discesa (p=0,027); al contrario, la bassa incertezza prevista alla linea di base ha portato a una diminuzione della ricompensa durante i turni in salita. I dati sono mostrati come mezzi di gruppo per la preferenza delle opzioni durante le condizioni pre-baseline, turno e post-baseline, ± SEM. Gli asterischi indicano differenze statistiche tra le condizioni HV e LV.(D) Il numero di omissioni di avvio è stato significativamente aumentato durante il downshift (p=0,004) e diminuito durante gli upshifts (p=0,017) in valore, indipendentemente dai livelli di incertezza previsti, dimostrando gli effetti delle condizioni generali di ricompensa ambientale sulla motivazione ad impegnarsi nel compito. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0,05, **p<0,01. Le statistiche di sintesi e i dati individuali degli animali sono forniti nella figura 1-source data 1.DOI:http://dx.doi.org/10.7554/eLife.27483.00310.7554/eLife.27483.004Figure1-source data 1.Summary statistics and individual data for naïve animals performing the task.DOI:http://dx.doi.org/10.7554/eLife.27483.004Video1.Un animale che esegue il compito durante l’upshift sull’opzione HV.Durante un upshift di valore su ogni opzione, la media dei ritardi da premiare è stata ridotta a 5 s con varianza mantenuta uguale a quella delle condizioni di base.DOI:http://dx.doi.org/10.7554/eLife.27483.00510.7554/eLife.27483.005Video2.Un animale che esegue il compito durante il downshift sull’opzione HV.Durante un downshift di valore su ogni opzione, la media dei ritardi da premiare è stata aumentata a 20 s con varianza mantenuta costante.DOI:http://dx.doi.org/10.7554/eLife.27483.00610.7554/eLife.27483.006
Tutti gli animali hanno cambiato significativamente la loro preferenza in risposta a tutti i turni(Figura 1, tutti i valori di p<0,05). Abbiamo poi valutato gli effetti delle condizioni generali di ricompensa ambientale sulla motivazione dei ratti ad impegnarsi nel compito. Il numero di omissioni di inizio (cioè, la mancata risposta alla stecca centrale presentata all’inizio di ogni prova entro 40 s) è stato analizzato con omnibus ANOVA con condizioni di ricompensa (stabile, upshift, e downshift crollato attraverso le opzioni HV e LV) come fattore all’interno del soggetto. L’effetto principale della condizione è stato significativo [F(1.09, 7.61)=16.772, p=0.03; Greenhouse-Geisser corretto]: il numero di omissioni è stato significativamente aumentato durante i turni inferiori (p=0.004) e diminuito durante i turni superiori (p=0.017) in valore, rivelando che l’impegno del compito era sensibile al tasso di ricompensa ambientale complessivo.
Pertanto, i roditori sono in grado di conoscere le fondamentali variazioni direzionali dei mezzi di valore nonostante le fluttuazioni stocastiche dei valori di risultato in condizioni di base (cioè l’incertezza attesa). Tuttavia, sono state osservate differenze significative tra HV e LV negli adattamenti di scelta sia per i turni in salita che per quelli in discesa: una maggiore varianza della distribuzione dei risultati alla linea di base ha facilitato l’adattamento comportamentale in risposta ai turni in salita (differenza HV vs LV, p=0,004), ma ha reso gli animali non ottimali durante i turni in discesa (p=0,027); al contrario, la bassa incertezza attesa alla linea di base ha portato a una diminuzione dell’acquisizione dei premi durante i turni in salita. Questi effetti possono essere spiegati da una natura iperbolica del conteggio dei ritardi tra le specie(Freeman et al., 2009; Green et al., 2013; Hwang et al., 2009; Mazur e Biondi, 2009; Mitchell et al., 2015; Rachlin et al., 1991).
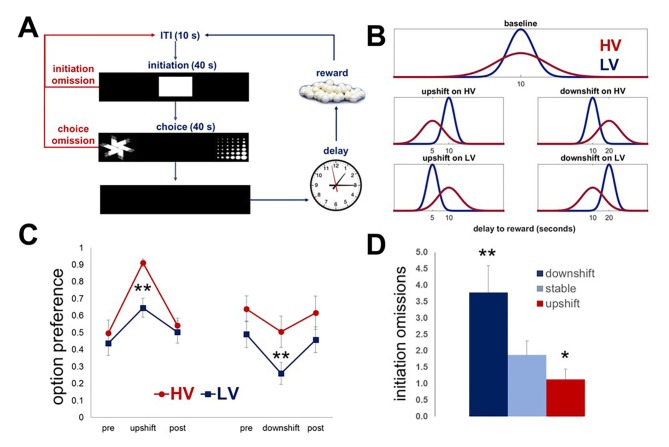
Figura 1 – Dati fonte 1.Figura 1—dati fonte 1. Progettazione del compito e prestazioni degli animali intatti.statistiche di sintesi e dati individuali per gli animali ingenui che eseguono il compito.statistiche di sintesi e dati individuali per gli animali ingenui che eseguono il compito.Il nostro compito è progettato per indagare gli effetti dell’incertezza dei risultati previsti sull’apprendimento dei valori.(A) Ogni prova è iniziata con la presentazione degli stimoli nello scomparto centrale del touchscreen. Ai ratti (n = 8) sono stati dati 40 s per avviare una prova. Se 40 s sono passati senza una risposta, la prova è stata segnata come una “omissione di inizio”. In seguito ad una puntura del naso al compartimento centrale, lo stimolo centrale è scomparso e due stimoli di scelta sono stati presentati contemporaneamente in ciascuno dei compartimenti laterali del touchscreen permettendo ad un animale una libera scelta tra due opzioni di ricompensa. Ad un animale sono stati dati 40 s per fare una scelta; la mancata selezione di un’opzione entro questo intervallo di tempo ha fatto sì che la prova venisse valutata come “omissione di scelta” e l’inizio di un ITI. Ogni opzione di risposta è stata associata alla consegna di un pellet di zucchero dopo un intervallo di tempo.(B) I ritardi associati a ciascuna opzione sono stati messi in comune da distribuzioni che sono identiche nel valore medio, ma diverse nella variabilità: LV (bassa variabilità, mostrata in blu) vs. HV (alta variabilità, mostrata in rosso); ~N(µ, σ): μ = 10 s, σ HV=4s, σ LV=1s. Dopo aver stabilito una prestazione stabile, i ratti hanno sperimentato incrementi di valore (µ = 5 s; σ mantenuto costante) e decrementi (μ = 20 s) su ogni opzione in modo indipendente, seguiti da un ritorno alle condizioni di base. Ogni turno e ritorno alla fase di base è durato per cinque sessioni di 60 prove.(C) Indipendentemente dal tipo di turno, gli animali hanno cambiato significativamente la loro preferenza in risposta a tutti i turni (tutti i valori di p<0,05). Tuttavia, sono state osservate differenze significative tra HV e LV negli adattamenti di scelta sia per i turni in salita che per quelli in discesa: una maggiore varianza della distribuzione dei risultati alla linea di base ha facilitato l’adattamento comportamentale in risposta ai turni in salita (differenza HV vs LV, p=0,004), ma ha reso gli animali non ottimali durante i turni in discesa (p=0,027); al contrario, la bassa incertezza prevista alla linea di base ha portato a una diminuzione della ricompensa durante i turni in salita. I dati sono mostrati come mezzi di gruppo per la preferenza delle opzioni durante le condizioni pre-baseline, turno e post-baseline, ± SEM. Gli asterischi indicano differenze statistiche tra le condizioni HV e LV.(D) Il numero di omissioni di avvio è stato significativamente aumentato durante il downshift (p=0,004) e diminuito durante gli upshifts (p=0,017) in valore, indipendentemente dai livelli di incertezza previsti, dimostrando gli effetti delle condizioni generali di ricompensa ambientale sulla motivazione ad impegnarsi nel compito. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0,05, **p<0,01. Le statistiche riassuntive e i dati dei singoli animali sono forniti nella Figura 1 – dati fonte 1.1. DOI:
http://dx.doi.org/10.7554/eLife.27483.00310.7554/eLife.27483.004Cifre dati a 1 fonte 1.Statistiche di sintesi e dati individuali per gli animali ingenui che svolgono il compito.DOI:http://dx.doi.org/10.7554/eLife.27483.004DOI:
http://dx.doi.org/10.7554/eLife.27483.004DOI:
http://dx.doi.org/10.7554/eLife.27483.004

Video 1.Un animale che esegue il compito durante l’upshift sull’opzione HV.Durante un upshift di valore su ogni opzione, la media dei ritardi da premiare è stata ridotta a 5 s con varianza mantenuta uguale a quella delle condizioni di base.DOI:
http://dx.doi.org/10.7554/eLife.27483.005
Video 2.Un animale che esegue il compito durante il turno di riposo su HV.Durante un downshift di valore su ogni opzione, la media dei ritardi da premiare è stata aumentata a 20 s con varianza mantenuta costante.3. DOI:
http://dx.doi.org/10.7554/eLife.27483.006
L’esperienza con l’incertezza induce modelli distinti di neuroadattamenti nel BLA e nell’OFC
Abbiamo ipotizzato che l’esperienza con diversi livelli di incertezza dell’esito indurrebbe neuroadattamenti a lungo termine, influenzando la risposta alla stessa ampiezza dei segnali di sorpresa. In particolare, abbiamo valutato l’espressione della gefirina (una proxy affidabile per i recettori GABAAA inseriti nella membrana che mediano la trasmissione inibitoria rapida;[Chhatwal et al., 2005; Tyagarajan et al., 2011]) e GluN1 (una sottounità obbligatoria dei recettori NMDA del glutammato;[Soares et al., 2013]) in BLA e OFC. Tre gruppi separati di animali sono stati addestrati a rispondere agli stimoli visivi su un touchscreen per ottenere una ricompensa dopo ritardi variabili. I valori dei risultati erano identici al nostro compito descritto sopra, ma non è stata data alcuna scelta. Un gruppo è stato addestrato in condizioni di BLA, il secondo in condizioni di HV (pari al numero totale di ricompense ricevute), e il terzo gruppo di controllo non ha ricevuto alcuna ricompensa (n = 8 in ogni gruppo, totale n = 24). Data la limitata quantità di tessuto, ci siamo concentrati sulla NMDA invece che sui recettori AMPA sulla base di precedenti prove che dimostravano effetti dissociabili dei recettori del glutammato ionotropo nel processo decisionale basato sul ritardo(Yates et al., 2015).
Le analisi dell’espressione delle proteine hanno rivelato adattamenti unici alla variabilità del risultato nel BLA, in particolare nella sensibilità allergica GABA. Le misure biochimiche sono state analizzate con ANOVA misto con la regione cerebrale come fattore all’interno del soggetto e l’esperienza di ricompensa (HV, LV o nessuna ricompensa) come fattore tra i soggetti. C’è stato un effetto significativo principale del gruppo [F (2,12)=6,002, p = 0,016] e regione cerebrale x interazione di gruppo[Figura 2A; F (2,12)=41,863, p<0,0001] per la gefirina. Un effetto principale significativo di gruppo [F(2,21)=4,084, p = 0,032] e gruppo x regione cerebrale [F(2,21)=5,291, p = 0,014] interazione sono stati trovati anche per l’espressione GluN1. Le analisi successive hanno identificato l’upregulation incertezza-dipendente di gefirina in BLA [tra i soggetti ANOVA: F(2,21)=45.448, p<0.0001), che è stato massimo dopo la formazione HV (tutti i valori post hoc p confronto post hoc p<0,05). Allo stesso modo, GluN1 ha mostrato una robusta upregulation in risposta al premio esperto in BLA[Figura 2B; F(2,21)=7,092, p=0,004; nessun premio vs LV p=0,045; nessun premio vs HV p=0,002], tuttavia le analisi post hoc non sono riuscite a rilevare una differenza significativa tra l’addestramento HV e LV (p=0,637). In OFC, la gefirina è stata invece downregulated in risposta alle esperienze con ricompensa in generale [F(2,12)=4,445, p=0,036; nessuna ricompensa vs LV p=0,045; nessuna ricompensa vs HV p=0.042] e non dipendeva dalla variabilità della distribuzione dei risultati (confronto post hoc: VH vs VL, p=1); non sono stati osservati cambiamenti in GluN1 [F(2,21)=2,359, p=0,119].10,7554/eLife.27483.007Figure 2.Region-specific alterations in gephyrin and GluN1 expression induced by experience with outcome uncertainty.three separate groups of animals were trained to respond to visual stimmuli on a touchscreen to get a reward after variable delays. I valori dei risultati erano identici al compito principale, ma non è stata data alcuna scelta. Un gruppo è stato addestrato in condizioni di VL, il secondo in condizioni di VH (pari al numero totale di ricompense ricevute) e il terzo gruppo di controllo non ha ricevuto alcuna ricompensa (n = 8 per gruppo). Abbiamo valutato l’espressione di A gefirina (una proxy affidabile per i recettori GABAAA inseriti nella membrana che mediano la trasmissione inibitoria veloce) e B GluN1 (una sottounità obbligatoria dei recettori NMDA del glutammato) in BLA e OFC ventrale. Le analisi biochimiche hanno rivelato l’upregulation incertezza-dipendente in gefirina in BLA, che è stato massimo dopo la formazione HV (p<0,0001). Allo stesso modo, GluN1 ha mostrato una robusta upregulation in risposta all’esperienza di ricompensa in BLA (nessuna ricompensa vs LV p=0,045; nessuna ricompensa vs HV p=0,002), tuttavia le analisi post hoc non sono riuscite a rilevare una differenza significativa tra l’addestramento HV e LV (p=0,637). Nell’OFC ventrale, la gefirina è stata downregolata in risposta alle esperienze con il reward in generale (nessun reward vs LV p=0,045; nessun reward vs HV p=0,042) e non dipendeva dalla variabilità nella distribuzione dei risultati; non sono stati osservati cambiamenti in GluN1. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0.05, **p<0.01 Le statistiche di riepilogo e i dati individuali degli animali sono forniti in Figura 2 dati fonte 1.DOI:http://dx.doi.org/10.7554/eLife.27483.00710.7554/eLife.27483.008Figure2 dati fonte 1.Statistiche di riepilogo e dati individuali per GluN1 e l’espressione della gefirina in BLA e OFC.DOI:http://dx.doi.org/10.7554/eLife.27483.008
Pertanto, sia il BLA che l’OFC subiscono modelli unici di neuroadattamenti in risposta all’esperienza con la variabilità, suggerendo che queste regioni cerebrali possono giocare ruoli complementari, ma dissociabili, nell’apprendimento dei valori sotto l’incertezza dei risultati. Data la complessità comportamentale che i roditori mostrano nel nostro compito, siamo stati in grado di testare direttamente i contributi causali del BLA e dell’OFC ventromediale per valutare l’apprendimento in condizioni di incertezza attesa nella distribuzione degli esiti.
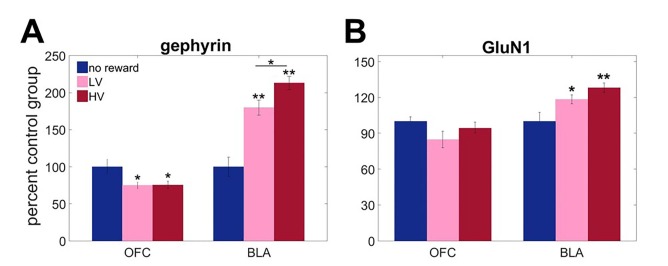
Figura 2 – Dati fonte 1.Figura 2—dati di fonte 1. Alterazioni specifiche della regione nell’espressione della gefirina e del GluN1 indotte dall’esperienza con l’incertezza dell’esito.statistiche di sintesi e dati individuali per il GluN1 e l’espressione della gefirina nel BLA e nell’OFC.statistiche di sintesi e dati individuali per il GluN1 e l’espressione della gefirina nel BLA e nell’OFC.Tre gruppi separati di animali sono stati addestrati a rispondere agli stimoli visivi su un touchscreen per ottenere una ricompensa dopo ritardi variabili. I valori dei risultati erano identici al compito principale, ma non è stata data alcuna scelta. Un gruppo è stato addestrato in condizioni di BLA, il secondo in condizioni di HV (pari al numero totale di ricompense ricevute), e il terzo gruppo di controllo non ha ricevuto alcuna ricompensa (n = 8 per gruppo). Abbiamo valutato l’espressione di A gefirina (una proxy affidabile per i recettori GABAAA inseriti nella membrana che mediano la trasmissione inibitoria veloce) e B GluN1 (una sottounità obbligatoria dei recettori NMDA del glutammato) in BLA e OFC ventrale. Le analisi biochimiche hanno rivelato l’upregulation incertezza-dipendente in gefirina in BLA, che è stato massimo dopo la formazione HV (p<0,0001). Allo stesso modo, GluN1 ha mostrato una robusta upregulation in risposta all’esperienza di ricompensa in BLA (nessuna ricompensa vs LV p=0,045; nessuna ricompensa vs HV p=0,002), tuttavia le analisi post hoc non sono riuscite a rilevare una differenza significativa tra l’addestramento HV e LV (p=0,637). Nell’OFC ventrale, la gefirina è stata downregolata in risposta alle esperienze con il reward in generale (nessun reward vs LV p=0,045; nessun reward vs HV p=0,042) e non dipendeva dalla variabilità nella distribuzione dei risultati; non sono stati osservati cambiamenti in GluN1. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0.05, **p<0.01 Le statistiche di sintesi e i dati dei singoli animali sono forniti in Figura 2 dati fonte 1.1. DOI:
http://dx.doi.org/10.7554/eLife.27483.00710.7554/eLife.27483.008Cifre dati a 2 fonti 1.Statistiche di sintesi e dati individuali per GluN1 e l’espressione della gefirina in BLA e OFC.DOI:http://dx.doi.org/10.7554/eLife.27483.008DOI:
http://dx.doi.org/10.7554/eLife.27483.008DOI:
http://dx.doi.org/10.7554/eLife.27483.008
Contributi causali del BLA e dell’OFC al valore dell’apprendimento sotto l’incertezza
I risultati degli studi sulle lesioni (i siti delle lesioni sono mostrati nella Figura 3) sono stati in linea con le previsioni suggerite dai dati sulle proteine. Poiché eravamo interessati principalmente ai contributi del BLA e dell’OFC all’apprendimento a sorpresa, abbiamo analizzato per la prima volta i cambiamenti massimi nella preferenza delle opzioni in risposta ai cambiamenti in salita e in discesa. Questa analisi ci ha permesso di controllare i potenziali effetti delle lesioni cerebrali sul comportamento di scelta in condizioni di base nel nostro compito. Un omnibus ANOVA con tipo di turno come all’interno del gruppo e sperimentale (finzione, BLA vs lesione OFC; n = 8 per gruppo; totale n = 24) come inter-fattori soggettivi rilevato un significativo effetto principale del gruppo [F(2,21)=11.193, p<0.0001] e gruppo x interazione tipo turno [F(6,63)=9.472, p<0.0001). Le analisi successive hanno mostrato significativi e semplici effetti principali del gruppo sperimentale su tutti i tipi di turno: upshift su HV [F(2,21)=14,723, p<0,0001], upshift su LV [F(2,21)=5,663, p=0,011], downshift su HV [F(2,21)=19,081, p<0,0001], e downshift su LV [F(2,21)=7,189, p=0,004]. I ratti OFC-sollevati erano meno ottimali nel nostro compito: hanno cambiato la loro preferenza di opzione in misura significativamente minore rispetto agli animali di controllo durante i turni in salita su HV (p=0,005) e LV (p=0,039), così come il downshift su LV opzione (p=0,015; Figura 4A). Mentre le lesioni OFC hanno prodotto un marcato deterioramento delle prestazioni, è stato meno chiaro se le alterazioni prodotte dalle lesioni BLA portano a un comportamento non ottimale. Gli animali affetti da BLA hanno modificato la loro preferenza per le opzioni in misura minore durante i turni in aumento dell’HV (p<0,0001), ma sono stati compensati da adattamenti esagerati ai turni in diminuzione dell’HV (p<0,0001; Figura 4A).10.7554/eLife.27483.009Figure 3.Location e l’estensione della lesione prevista (regioni colorate) su sezioni coronali standard attraverso OFC ventrale e BLA.l’estensione delle lesioni è stata valutata dopo il completamento del test comportamentale da colorazione per un marcatore di nuclei neuronali, NeuN.(A) In alto: fotomicrografia rappresentativa di una sezione coronale colorata NeuN che mostra la lesione ventrale OFC. In basso: rappresentazioni di sezioni coronali adattate da(Paxinos e Watson, 1997). I numeri in basso a sinistra di ogni sezione adattata rappresentano la distanza anteriore-posteriore (mm) da Bregma. Blu chiaro e blu scuro rappresentano l’area di lesione massima e minima tra gli animali, rispettivamente. Anche se le coordinate erano rivolte alla regione orbitale ventrale, l’estensione della lesione comprende anche la corteccia orbitale mediale anteriore.(B) In alto: fotomicrografia rappresentativa di una sezione coronale colorata NeuN che mostra la lesione BLA. In basso: rappresentazioni di sezioni coronali con numeri in basso a sinistra di ogni sezione corrispondente che rappresenta la distanza anteriore-posteriore (mm) da Bregma. Rosso chiaro e rosso scuro rappresentano l’area di lesione massima e minima tra gli animali, rispettivamente.DOI:http://dx.doi.org/10.7554/eLife.27483.00910.7554/eLife.27483.010Figure4.Cambiamenti nella preferenza di scelta in risposta ai cambiamenti di valore e le strategie di apprendimento nei gruppi sperimentali.(A) I ratti OFC-lesionati (n = 8) sono stati meno ottimali sul nostro compito: hanno cambiato la loro preferenza opzione in grado significativamente inferiore rispetto agli animali di controllo (n = 8) durante i turni in su su HV (p = 0,005) e LV (p = 0,039), così come il downshift su opzione LV (p = 0,015). Al contrario, gli animali con lesioni BLA (n = 8) hanno modificato la loro preferenza di opzione in misura minore durante i turni in salita (p<0,0001), ma compensati da adattamenti esagerati ai turni in discesa (p<0,0001). La figura 4 mostra la preferenza per l’opzione durante le condizioni pre-baseline, turno e post-baseline in Figura 4, supplemento 1. Abbiamo suddiviso le prove in due tipi: quando i ritardi rientravano nelle distribuzioni sperimentate per ciascuna opzione al baseline( risultatiattesi ) e quelli in cui il grado di sorpresa superava quello previsto per caso( risultati inaspettati). I punteggi di win-stay/lose-shift sono stati calcolati in base ai dati trial-by-trial: un punteggio di 1 è stato assegnato quando gli animali hanno ripetuto la scelta in seguito a risultati migliori della media(win-stay) o sono passati all’altra alternativa in seguito a risultati peggiori della media(lose-shift). Gli animali sham-lesionati hanno dimostrato una maggiore sensibilità a feedback inattesi (valori di p < 0,001). Analogamente, la capacità di distinguere tra risultati attesi e inaspettati è rimasta intatta negli animali con lesioni BLA (valori p < 0,001), sebbene la loro sensibilità al feedback sia complessivamente diminuita. Al contrario, gli animali colonizzati da OFC non sono riusciti a distinguere le fluttuazioni attese da quelle inattese.(C,D) Per esaminare la traiettoria di apprendimento abbiamo analizzato l’evoluzione della preferenza delle opzioni. Gli animali con lesioni BLA erano indistinguibili dai controlli durante i turni sull’opzione LV. Mentre, questo gruppo sperimentale ha dimostrato un apprendimento significativamente attenuato durante l’upshift su HV (p valori < 0,0001 per tutte le sessioni) e potenziato le prestazioni durante le sessioni da 3 a 5 su HV downshift (p valori < 0,05) rispetto al finto gruppo. Al contrario, l’apprendimento negli animali affetti da OFC è stato influenzato dalla maggior parte dei tipi di turno: questi animali hanno dimostrato un apprendimento significativamente più lento durante le sessioni da 3 a 5 durante l’upshift su HV (valori p < 0,05), tutte le sessioni durante l’upshift su LV (valori p < 0,05) e le sessioni da 3 a 5 durante il downshift su LV (valori p < 0,05). La sessione 0 si riferisce alla preferenza dell’opzione baseline/pre-shift. Nonostante queste differenze nelle risposte ai cambiamenti di valore in condizioni di incertezza, non abbiamo osservato alcun deficit nell’apprendimento delle ricompense di base negli animali affetti da BLA o OFC, come mostrato nella Figura 4, supplemento 2. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0.05, **p<0.01. Le statistiche di riepilogo e i dati individuali degli animali sono forniti in Figura 4 dati da fonte 1 e Figura 4 dati da fonte 2.DOI:http://dx.doi.org/10.7554/eLife.27483.01010.7554/eLife.27483.011Figuredati da 4 fonti 1.Statistiche di riepilogo e dati individuali per i cambiamenti nelle preferenze di scelta e nelle strategie di apprendimento.DOI:http://dx.doi.org/10.7554/eLife.27483.01110.7554/eLife.27483.012Figure4 dati fonte 2.Statistiche di sintesi e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai cambiamenti.DOI:http://dx.doi.org/10.7554/eLife.27483.01210.7554/eLife.27483.013FigureSupplemento a 4 cifre 1.Cambiamenti nel comportamento di scelta in risposta ai cambiamenti di valore.(A) Entrambi i gruppi di lesioni hanno dimostrato un ridotto adattamento ai cambiamenti di valore dell’opzione HV (p<0.01).(B). Gli animali con lesioni BLA hanno scelto l’opzione LV più frequentemente rispetto ai controlli quando il suo valore è stato aumentato (p<0,01).(C, D) Sia gli animali con lesioni BLA che quelli con lesioni OFC hanno anche mostrato una riduzione della preferenza per l’opzione HV (p<0,01) e un aumento della preferenza per l’opzione LV (p<0,05) durante i turni inferiori rispetto agli animali finti. Questo modello di risultati può essere spiegato da cambiamenti nel comportamento di scelta anche in condizioni di base in BLA- e OFC-lesionati animali che hanno interagito con la capacità dei ratti di conoscere i turni di valore. Infatti, ci sono state differenze significative di gruppo nelle preferenze di base prima del turno. I dati sono mostrati come mezzi di gruppo per le preferenze di opzione durante le condizioni pre-baseline, turno e post-baseline, ± SEM. *p<0,05, **p<0,01. Le statistiche di riepilogo e i dati dei singoli animali sono forniti in Figura 4 dati fonte 2.DOI:http://dx.doi.org/10.7554/eLife.27483.01310.7554/eLife.27483.014Figuresupplemento a 4 cifre 2.La mancanza di differenze di gruppo nell’apprendimento di base di ricompensa.I nostri interventi chirurgici hanno avuto luogo prima di qualsiasi esposizione all’apparato di prova o di formazione comportamentale. Entrambi i gruppi lesionati erano indistinguibili dai controlli nelle fasi iniziali del compito. Durante il pre-formazione, gli animali hanno imparato a rispondere agli stimoli visivi presentati nello scomparto centrale dello schermo entro un intervallo di tempo di 40 s per ricevere la ricompensa dello zucchero (risposta allo stimolo). Successivamente, i ratti hanno imparato ad avviare la prova puntando il naso sullo stimolo quadrato bianco brillante presentato nello scomparto centrale dello schermo tattile; questa risposta è stata seguita dalla scomparsa dello stimolo centrale e dalla presentazione di un’immagine target in uno scomparto laterale dello schermo tattile (avvio della prova). Le risposte all’immagine target hanno prodotto una ricompensa immediata. L’ultima fase dell’addestramento è stata somministrata per familiarizzare gli animali con i risultati ritardati. Il protocollo è stato identico a quello della fase precedente, ad eccezione del fatto che le risposte all’immagine target e la consegna della ricompensa sono state separate da un ritardo stabile di 5 s (certi ritardi di 5 s).(A, B). Gli animali di tutti i gruppi hanno impiegato un numero simile di giorni per imparare a ficcare il naso agli stimoli visivi sul touchscreen per ricevere i premi di zucchero (p=0,796) e per avviare una prova (p=0,821).(C, D). Non ci sono state differenze di gruppo nelle risposte all’introduzione di un intervallo di ritardo di 5 s durante il pre-formazione (p=0,518) o nel numero di sessioni per raggiungere una prestazione stabile durante la fase iniziale di base del nostro compito di incertezza (p=0,772). I dati sono mostrati come mezzi di gruppo ± SEM.DOI:http://dx.doi.org/10.7554/eLife.27483.014
Oltre ad esaminare i cambiamenti massimi nelle preferenze delle opzioni, abbiamo analizzato i dati comportamentali con un ANOVA omnibus con tipo di turno e fase di turno (baseline pre-movimento, performance del turno e baseline post-movimento) come all’interno del gruppo di soggetti e del gruppo sperimentale come fattori tra i soggetti. Questo test ha rilevato in modo simile un significativo tipo di spostamento x fase x interazione di gruppo [F(6.9,72.5)=7.41, p<0.0001; Greenhouse-Geisser corretto, Figura 4-figure supplement 1). Coerentemente con le analisi precedenti, i test post hoc hanno rivelato adattamenti ridotti per valutare gli uphifts sull’opzione HV in entrambi i gruppi di lesioni (p<0,01). Tuttavia, abbiamo anche osservato scelte più frequenti dell’opzione LV quando il suo valore è stato aumentato in animali con lesioni BLA (p<0,01) così come una ridotta preferenza per l’opzione HV (p<0,01) e una maggiore preferenza per l’opzione LV (p<0,05) durante i turni di lavoro in entrambi i gruppi di lesioni rispetto agli animali di controllo. Questo modello di risultati può essere spiegato da cambiamenti nel comportamento di scelta anche in condizioni di base in animali con lesioni BLA e OFC che hanno interagito con la capacità dei ratti di conoscere i turni di valore.
Il successo del nostro compito richiedeva agli animali di distinguere tra la varianza delle distribuzioni dei risultati in condizioni di stabilità e i sorprendenti spostamenti di valore, nonostante il fatto che le distribuzioni di ritardo alla linea di base e le distribuzioni durante il turno si sovrappongano parzialmente. Per valutare se gli animali nei gruppi lesionati hanno adottato una strategia diversa e hanno dimostrato un’alterata sensibilità a risultati sorprendenti, abbiamo esaminato le risposte del turno di vincita/perdita. I punteggi del win-stay e del lose-shift sono stati calcolati sulla base di dati prova per prova simili ai rapporti precedenti(Faraut et al., 2016; Imhof et al., 2007; Worthy et al., 2013): un punteggio di 1 è stato assegnato quando gli animali hanno ripetuto la scelta in seguito a risultati migliori della media(win-stay) o sono passati all’altra alternativa in seguito a risultati peggiori della media(lose-shift). Le prove win-shift e lose-stay sono state conteggiate come 0 s. Per valutare in particolare se i ratti distinguevano le fluttuazioni attese dai cambiamenti sorprendenti, abbiamo diviso le prove in due tipi: quando i ritardi rientravano nelle distribuzioni sperimentate per ogni opzione al baseline (risultati attesi) e quelle in cui il grado di sorpresa superava quello previsto per caso. L’algoritmo utilizzato per questa analisi ha tenuto traccia di tutti i ritardi sperimentati in condizioni di base prima della prova in corso per ogni singolo animale. Su ogni prova, abbiamo trovato il valore del ritardo minimo e massimo. Se il valore del ritardo attuale rientrava in questo intervallo, il risultato è stato classificato come previsto. Se il ritardo attuale non rientrava in questa distribuzione, il risultato di questa prova è stato classificato come inaspettato (sorprendente).
I punteggi win-stay e lose-shift sono stati calcolati separatamente per ogni tipo di trial e le loro probabilità (punteggio sommario diviso per il numero di trial) per entrambi i tipi di trial sono stati sottoposti ad ANOVA con strategia come all’interno del soggetto e gruppo sperimentale come fattori tra i soggetti. Le nostre analisi hanno indicato una significativa strategia x interazione del gruppo sperimentale [F(6,63)=9,912, p<0,0001]. Criticamente, gli animali sham-lesioned dimostrato una maggiore sensibilità a risultati inaspettati rispetto alle fluttuazioni prevedibili sia per le vittorie e le perdite(Figura 4B, p valori <0,0001). Allo stesso modo, la capacità di distinguere tra risultati attesi e inaspettati era intatta negli animali colonizzati con BLA (valori p < 0,001), anche se la loro sensibilità al feedback è diminuita nel complesso. Al contrario, gli animali affetti da OFC non sono riusciti a distinguere le fluttuazioni prevedibili da quelle sorprendenti. È interessante notare che gli animali con finto e BLA hanno dimostrato bassi punteggi di vincita e perdita di turno quando erano attesi risultati di prova; questi animali hanno avuto più probabilità di spostarsi dopo risultati migliori della media e di persistere con le loro scelte dopo risultati peggiori. Oltre all’insensibilità al feedback, tale comportamento può derivare da un aumento del comportamento esplorativo in risposta alle vittorie e all’inflessibilità comportamentale dopo le perdite. Inoltre, quando i risultati sono relativamente stabili e prevedibili, i ratti possono essere più sensibili alla storia delle ricompense a lungo termine e fare meno affidamento sull’esito di una data prova.
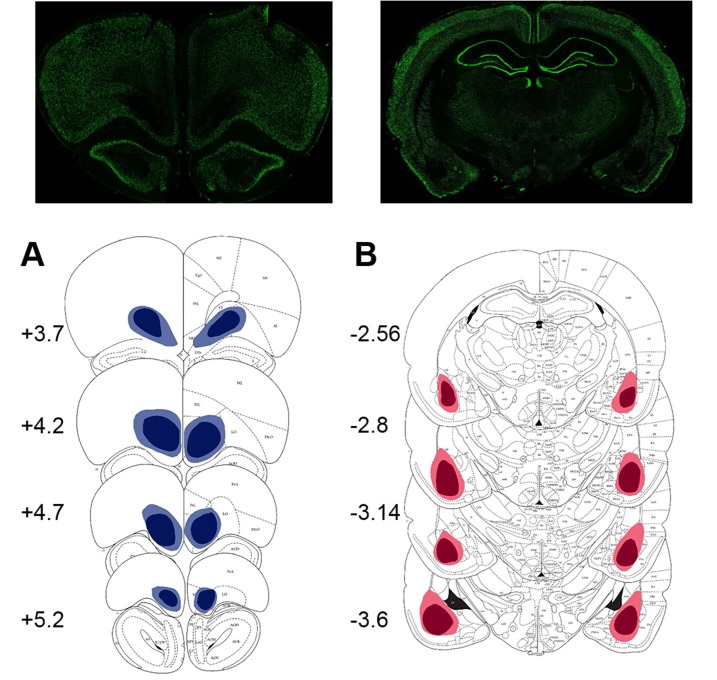
Figura 3.Posizione ed estensione della lesione prevista (regioni colorate) su sezioni coronali standard attraverso OFC ventrale e BLA.L’estensione delle lesioni è stata valutata dopo il completamento del test comportamentale mediante colorazione per un marker di nuclei neuronali, NeuN.(A) In alto: fotomicrografia rappresentativa di una sezione coronale colorata NeuN che mostra la lesione ventrale OFC. In basso: rappresentazioni di sezioni coronali adattate da(Paxinos e Watson, 1997). I numeri in basso a sinistra di ogni sezione adattata rappresentano la distanza anteriore-posteriore (mm) da Bregma. Blu chiaro e blu scuro rappresentano l’area di lesione massima e minima tra gli animali, rispettivamente. Anche se le coordinate erano rivolte alla regione orbitale ventrale, l’estensione della lesione comprende anche la corteccia orbitale mediale anteriore.(B) In alto: fotomicrografia rappresentativa di una sezione coronale colorata NeuN che mostra la lesione BLA. In basso: rappresentazioni di sezioni coronali con numeri in basso a sinistra di ogni sezione corrispondente che rappresenta la distanza anteriore-posteriore (mm) da Bregma. Rosso chiaro e rosso scuro rappresentano l’area di lesione massima e minima tra gli animali, rispettivamente.DOI:
http://dx.doi.org/10.7554/eLife.27483.009
Figura 4-figure supplement 2.Statistiche di riepilogo e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai cambiamenti delle preferenze di scelta e delle strategie di apprendimento.statistiche di riepilogo e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai cambiamenti delle preferenze di scelta e delle strategie di apprendimento.statistiche di riepilogo e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai cambiamenti delle preferenze di scelta e delle strategie di apprendimento.statistiche di riepilogo e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai cambiamenti di valore.cambiamenti del comportamento di scelta in risposta ai cambiamenti di valore.la mancanza di differenze di gruppo nell’apprendimento di base dei premi.(A) I ratti OFC-conservati (n = 8) sono stati meno ottimali nel nostro compito: hanno cambiato la loro preferenza di opzione in misura significativamente minore rispetto agli animali di controllo (n = 8) durante i turni in salita su HV (p=0.005) e LV (p=0.039), così come il turno in discesa su LV opzione (p=0.015). Al contrario, gli animali con lesioni BLA (n = 8) hanno modificato la loro preferenza di opzione in misura minore durante i turni in salita (p<0,0001), ma compensati da adattamenti esagerati ai turni in discesa (p<0,0001). I gruppi indicano la preferenza per l’opzione durante le condizioni pre-baseline, turno e post-baseline sono mostrati in Figura 4-figure supplement 1. Abbiamo suddiviso le prove in due tipi: quando i ritardi rientravano nelle distribuzioni sperimentate per ciascuna opzione al baseline( risultatiattesi ) e quelli in cui il grado di sorpresa superava quello previsto per caso( risultati inaspettati). I punteggi di win-stay/lose-shift sono stati calcolati in base ai dati trial-by-trial: un punteggio di 1 è stato assegnato quando gli animali hanno ripetuto la scelta in seguito a risultati migliori della media(win-stay) o sono passati all’altra alternativa in seguito a risultati peggiori della media(lose-shift). Gli animali sham-lesionati hanno dimostrato una maggiore sensibilità a feedback inattesi (valori di p < 0,001). Analogamente, la capacità di distinguere tra esiti attesi e inaspettati era intatta negli animali con lesioni BLA (valori p < 0,001), anche se la loro sensibilità al feedback è complessivamente diminuita. Al contrario, gli animali colonizzati da OFC non sono riusciti a distinguere le fluttuazioni attese da quelle inattese.(C,D) Per esaminare la traiettoria di apprendimento abbiamo analizzato l’evoluzione della preferenza delle opzioni. Gli animali con lesioni BLA erano indistinguibili dai controlli durante i turni sull’opzione LV. Mentre, questo gruppo sperimentale ha dimostrato un apprendimento significativamente attenuato durante l’upshift su HV (p valori < 0,0001 per tutte le sessioni) e potenziato le prestazioni durante le sessioni da 3 a 5 su HV downshift (p valori < 0,05) rispetto al finto gruppo. Al contrario, l’apprendimento negli animali affetti da OFC è stato influenzato dalla maggior parte dei tipi di turno: questi animali hanno dimostrato un apprendimento significativamente più lento durante le sessioni da 3 a 5 durante l’upshift su HV (valori p < 0,05), tutte le sessioni durante l’upshift su LV (valori p < 0,05) e le sessioni da 3 a 5 durante il downshift su LV (valori p < 0,05). La sessione 0 si riferisce alla preferenza dell’opzione baseline/pre-shift. Nonostante queste differenze nelle risposte ai cambiamenti di valore in condizioni di incertezza, non abbiamo osservato alcun deficit nell’apprendimento delle ricompense di base negli animali affetti da BLA o OFC, come mostrato nella Figura 4, supplemento 2. I dati sono mostrati come mezzi di gruppo per condizione +SEM. *p<0.05, **p<0.01. Le statistiche riassuntive e i dati dei singoli animali sono forniti nella Figura 4 dati 1 e nella Figura 4 dati 2.DOI:
http://dx.doi.org/10.7554/eLife.27483.01010.7554/eLife.27483.011Cifre dati a 4 fonti 1.Statistiche di sintesi e dati individuali per i cambiamenti nelle preferenze di scelta e nelle strategie di apprendimento.DOI:http://dx.doi.org/10.7554/eLife.27483.011DOI:
http://dx.doi.org/10.7554/eLife.27483.01110.7554/eLife.27483.012Cifre dati a 4 fonti 2.Statistiche di sintesi e dati individuali che dimostrano le differenze di gruppo sperimentali in risposta ai turni.DOI:http://dx.doi.org/10.7554/eLife.27483.012DOI:
http://dx.doi.org/10.7554/eLife.27483.012DOI:
http://dx.doi.org/10.7554/eLife.27483.011DOI:
http://dx.doi.org/10.7554/eLife.27483.012(A) Entrambi i gruppi di lesioni hanno dimostrato adattamenti ridotti per valutare gli upshifts sull’opzione HV (p<0,01).(B). Gli animali affetti da BLA hanno scelto l’opzione LV più frequentemente rispetto ai controlli quando il suo valore è stato aumentato (p<0,01).(C, D) Sia gli animali con lesioni BLA che quelli con lesioni OFC hanno anche mostrato una riduzione della preferenza per l’opzione HV (p<0,01) e un aumento della preferenza per l’opzione LV (p<0,05) durante i turni inferiori rispetto agli animali finti. Questo modello di risultati può essere spiegato da cambiamenti nel comportamento di scelta anche in condizioni di base in BLA- e OFC-lesionati animali che hanno interagito con la capacità dei ratti di conoscere i turni di valore. Infatti, ci sono state differenze significative di gruppo nelle preferenze di base prima del turno. I dati sono mostrati come mezzi di gruppo per le preferenze di opzione durante le condizioni pre-baseline, turno e post-baseline, ± SEM. *p<0,05, **p<0,01. Le statistiche di riepilogo e i dati dei singoli animali sono forniti nella figura 4 dati fonte 2.DOI:
http://dx.doi.org/10.7554/eLife.27483.013I nostri interventi chirurgici hanno avuto luogo prima di qualsiasi esposizione all’apparato di prova o di addestramento comportamentale. Entrambi i gruppi lesionati erano indistinguibili dai controlli nelle fasi iniziali del compito. Durante il pre-formazione, gli animali hanno imparato a rispondere agli stimoli visivi presentati nello scomparto centrale dello schermo entro un intervallo di tempo di 40 s per ricevere la ricompensa dello zucchero (risposta allo stimolo). Successivamente, i ratti hanno imparato ad avviare la prova puntando il naso sullo stimolo quadrato bianco brillante presentato nello scomparto centrale dello schermo tattile; questa risposta è stata seguita dalla scomparsa dello stimolo centrale e dalla presentazione di un’immagine target in uno scomparto laterale dello schermo tattile (avvio della prova). Le risposte all’immagine target hanno prodotto una ricompensa immediata. L’ultima fase dell’addestramento è stata somministrata per familiarizzare gli animali con i risultati ritardati. Il protocollo è stato identico a quello della fase precedente, ad eccezione del fatto che le risposte all’immagine target e la consegna della ricompensa sono state separate da un ritardo stabile di 5 s (certi ritardi di 5 s).(A, B). Gli animali di tutti i gruppi hanno impiegato un numero simile di giorni per imparare a ficcare il naso agli stimoli visivi sul touchscreen per ricevere i premi di zucchero (p=0,796) e per avviare una prova (p=0,821).(C, D). Non ci sono state differenze di gruppo nelle risposte all’introduzione di un intervallo di ritardo di 5 s durante il pre-formazione (p=0,518) o nel numero di sessioni per raggiungere una prestazione stabile durante la fase iniziale di base del nostro compito di incertezza (p=0,772). I dati sono mostrati come mezzi di gruppo ± SEM.DOI:
http://dx.doi.org/10.7554/eLife.27483.014
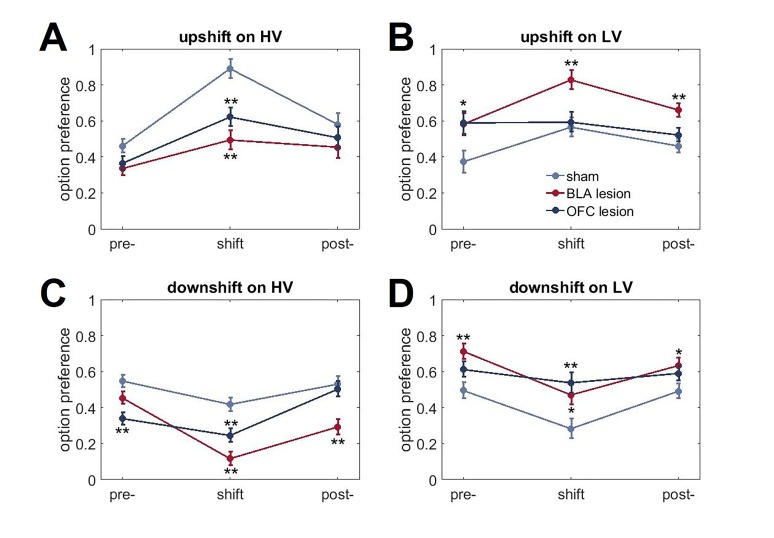
Figura 4-figure supplement 1.Cambiamenti nel comportamento di scelta in risposta a spostamenti di valore.(A) Entrambi i gruppi di lesioni hanno dimostrato una riduzione degli adattamenti per gli upshifts di valore sull’opzione HV (p<0,01).(B). Gli animali con lesioni BLA hanno scelto l’opzione LV più frequentemente rispetto ai controlli quando il suo valore è stato aumentato (p<0,01).(C, D) Sia gli animali con lesioni BLA che quelli con lesioni OFC hanno anche mostrato una riduzione della preferenza per l’opzione HV (p<0,01) e un aumento della preferenza per l’opzione LV (p<0,05) durante i turni inferiori rispetto agli animali finti. Questo modello di risultati può essere spiegato da cambiamenti nel comportamento di scelta anche in condizioni di base in BLA- e OFC-lesionati animali che hanno interagito con la capacità dei ratti di conoscere i turni di valore. Infatti, ci sono state significative differenze di gruppo nelle preferenze di base prima del turno. I dati sono mostrati come mezzi di gruppo per le preferenze di opzione durante le condizioni pre-baseline, turno e post-baseline, ± SEM. *p<0,05, **p<0,01. Le statistiche di riepilogo e i dati dei singoli animali sono forniti nella figura 4 dati fonte 2.DOI:
http://dx.doi.org/10.7554/eLife.27483.013
Figura 4-figure supplement 2.La mancanza di differenze di gruppo nell’apprendimento premiante di base.I nostri interventi chirurgici hanno avuto luogo prima di qualsiasi esposizione all’apparato di prova o all’addestramento comportamentale. Entrambi i gruppi lesionati erano indistinguibili dai controlli nelle fasi iniziali del compito. Durante il pre-formazione, gli animali hanno imparato a rispondere agli stimoli visivi presentati nello scomparto centrale dello schermo entro un intervallo di tempo di 40 s per ricevere la ricompensa di zucchero (risposta allo stimolo). Successivamente, i ratti hanno imparato ad avviare la prova puntando il naso sullo stimolo quadrato bianco brillante presentato nello scomparto centrale dello schermo tattile; questa risposta è stata seguita dalla scomparsa dello stimolo centrale e dalla presentazione di un’immagine target in uno scomparto laterale dello schermo tattile (avvio della prova). Le risposte all’immagine target hanno prodotto una ricompensa immediata. L’ultima fase dell’addestramento è stata somministrata per familiarizzare gli animali con i risultati ritardati. Il protocollo è stato identico a quello della fase precedente, ad eccezione del fatto che le risposte all’immagine target e la consegna della ricompensa sono state separate da un ritardo stabile di 5 s (certi ritardi di 5 s).(A, B). Gli animali di tutti i gruppi hanno impiegato un numero simile di giorni per imparare a ficcare il naso agli stimoli visivi sul touchscreen per ricevere i premi di zucchero (p=0,796) e per avviare una prova (p=0,821).(C, D). Non ci sono state differenze di gruppo nelle risposte all’introduzione di un intervallo di ritardo di 5 s durante il pre-formazione (p=0,518) o nel numero di sessioni per raggiungere una prestazione stabile durante la fase iniziale di base del nostro compito di incertezza (p=0,772). I dati sono mostrati come mezzi di gruppo ± SEM.DOI:
http://dx.doi.org/10.7554/eLife.27483.014
Le lesioni al BLA e all’OFC alterano la traiettoria di apprendimento
Per esaminare la traiettoria di apprendimento abbiamo analizzato l’evoluzione della preferenza delle opzioni durante i turni di lavoro. In particolare, abbiamo sottoposto i dati sessione per sessione durante ogni swift ad un ANOVA omnibus con sessione di test (da 1 a 5; la sessione 0 nella Figura 4C,D corrisponde alla preferenza dell’opzione pre-shift) e il tipo di turno come all’interno del gruppo e il gruppo sperimentale tra i fattori del soggetto. Questa analisi ha rivelato una sessione a tre vie x tipo di turno x interazione di gruppo [F(8.73, 91.71)=8.418, p=0.002; Greenhouse-Geisser corretto, Figura 4C,D]. Le analisi successive hanno identificato significative interazioni a due vie sessione x interazioni di gruppo per ogni tipo di turno [upshift su HV: F(5.24, 55.04)=3.585, p=0.006; downshift su HV: F(4.14, 43.452)=25.646, p<0.0001; salita su BT: F(2.59,27.14) = 4.378, p=0.016; discesa su BT: F(3.69, 38.767)=6.768, p<0.0001; tutti i Greenhouse-Geisser corretti]. Gli animali con lesioni BLA erano indistinguibili dai controlli durante i turni sull’opzione BT. Tuttavia, questo gruppo sperimentale ha dimostrato l’apprendimento significativamente attenuato durante il turno in salita su HV (p valori < 0,0001 per tutte le sessioni) e potenziato le prestazioni durante le sessioni da 3 a cinque durante i turni in discesa su HV (p valori < 0,05) rispetto al gruppo finto. Al contrario, l’apprendimento negli animali affetti da OFC è stato influenzato dalla maggior parte dei tipi di turno: questi animali hanno dimostrato un apprendimento significativamente più lento durante le sessioni da 3 a 5 durante il turno superiore su HV (valori p < 0,05), tutte le sessioni durante il turno superiore su LV (valori p < 0,05) e le sessioni da 3 a 5 durante il turno inferiore su LV (valori p < 0,05).
Nonostante queste differenze nelle risposte ai cambiamenti di valore, non abbiamo osservato alcun deficit nell’apprendimento delle ricompense di base sia negli animali affetti da BLA che da OFC. I nostri interventi chirurgici hanno avuto luogo prima di qualsiasi esposizione all’apparato di prova o di formazione comportamentale, ma entrambi i gruppi lesionati erano indistinguibili dai controlli nelle prime fasi del compito. Tutti gli animali hanno impiegato un numero simile di giorni per imparare a ficcare il naso negli stimoli visivi sul touchscreen per ricevere premi di zucchero [F(2,21)=0,231, p=0,796] e per avviare una prova [F(2,21)=0,199, p=0,821]. Allo stesso modo, non ci sono state differenze di gruppo nelle risposte all’introduzione di un intervallo di ritardo di 5 s durante il pre-formazione [F(2,21)=0,679, p=0,518] o nel numero di sessioni per raggiungere una performance stabile durante la fase iniziale di base del nostro compito di incertezza [F92,21)=0,262, p=0,772; Figura 4-figure supplement 2].
Contributi complementari del BLA e dell’OFC al valore dell’apprendimento sotto l’incertezza rivelato dalla modellazione computazionale
Abbiamo adattato diverse versioni dei modelli RL alle scelte di prova per ogni animale separatamente. In particolare, abbiamo considerato il modello standard Rescorla-Wagner (RW) e un modello dinamico del tasso di apprendimento (Pearce-Hall, PH). Il modello RW aggiorna i valori delle opzioni in risposta agli RPE (cioè il grado di sorpresa) con un tasso di apprendimento costante, al contrario il modello PH permette di facilitare l’apprendimento con un feedback sorprendente (cioè, il tasso di apprendimento è scalato secondo gli errori di previsione assoluta). Abbiamo anche confrontato modelli in cui l’incertezza del risultato atteso viene appresa contemporaneamente al valore e scala l’impatto degli errori di previsione sul valore (RW+incertezza attesa) e sull’aggiornamento del tasso di apprendimento (modello completo). Il numero totale di parametri liberi, il BIC e i valori dei parametri per ogni modello e gruppo sperimentale sono forniti nella Tabella 1. Il comportamento del gruppo di controllo è stato meglio catturato dal modello dinamico del tasso di apprendimento con la scala RPE proporzionale all’incertezza attesa del risultato e la facilitazione dell’apprendimento in risposta ad un feedback sorprendente (modello completo; Tabella 1, i valori BIC più bassi indicano un migliore adattamento). Pertanto, i ratti nel nostro esperimento hanno aumentato i tassi di apprendimento in risposta alla sorpresa per massimizzare il tasso di acquisizione di ricompense, ma solo se i risultati inaspettati non erano probabilmente dovuti a fluttuazioni di valore in condizioni altrimenti stabili. Coerentemente con l’apprendimento attenuato osservato in animali con lesioni BLA, la performance prova per prova in questi animali è stata meglio adattata dal modello di incertezza RW + attesa, dimostrando la perdita selettiva del potenziamento dell’apprendimento in risposta alla sorpresa e preservando la scala RPE con incertezza attesa in questi animali, portando ad un apprendimento più lento rispetto agli animali intatti durante i turni sull’opzione HV. Al contrario, le prestazioni degli animali affetti da OFC sono state meglio considerate dal modello PH, suggerendo che, mentre questi animali aumentavano ancora i tassi di apprendimento in risposta alla sorpresa, essi erano insensibili all’incertezza attesa del risultato. Inoltre, i tassi di apprendimento complessivi sono stati ridotti negli animali con lesioni da OFC (p=0,01 rispetto al finto gruppo). Infine, abbiamo osservato valori significativamente più bassi di β (parametro della temperatura inversa nella regola di scelta softmax) sia negli animali con BLA che in quelli con OFC [F(2,21)=4,88, p=0,018; sham vs BLA: p<0,0001; sham vs OFC: p<0,0001], suggerendo che il loro comportamento è meno stabile, più esplorativo e meno dipendente dalla differenza dei valori di risultato appresi rispetto al gruppo di controllo.10.7554/eLife.27483.015Tabella 1.Confronto tra modelli. I valori BIC più bassi indicano un migliore adattamento del modello (in grassetto); il numero di parametri liberi e i valori dei parametri ± SEM del modello di migliore adattamento sono forniti per ogni gruppo. Le scelte di prova per prova degli animali intatti sono state meglio catturate dal modello dinamico del tasso di apprendimento che incorpora la scala RPE proporzionale all’incertezza attesa e la facilitazione dell’apprendimento in risposta a risultati sorprendenti (modello completo). Le lesioni BLA hanno eliminato selettivamente la scalatura del tasso di apprendimento in risposta alla sorpresa (il modello RW+incertezza attesa ha fornito il miglior adattamento). Mentre gli animali con lesioni da OFC continuavano ad aumentare i tassi di apprendimento in risposta ad eventi sorprendenti (modello PH), in questo gruppo si è persa la scala RPE proporzionale all’incertezza attesa dell’esito. Inoltre, i tassi di apprendimento complessivi sono stati ridotti negli animali con lesioni da OFC (p=0,01). Infine, abbiamo osservato valori significativamente più bassi di β (parametro della temperatura inversa nella regola di scelta softmax) in entrambi gli animali affetti da BLA e OFC (p<0.0001), suggerendo che il loro comportamento è meno stabile, più esplorativo e meno dipendente dalla differenza dei valori di risultato appresi. Gli asterischi indicano valori dei parametri che erano significativamente diversi dal gruppo di controllo (in grassetto).DOI:http://dx.doi.org/10.7554/eLife.27483.015ModelRWPHRW+incertezza attesaFull#parametri3456BICparametro ± SEMkα, valueβηα, riskω sham26519.3926900.6626384.1825681.70,29 ± 0,030,09 ± 0,0114,1 ± 0,990,33 ± 0,040,56 ± 0,083,04 ± 0,11 Lesione da BLA26201.8926864,7425153.8227162.820.32 ± 0.020.07 ± 0.017.4 ± 0.6*n/a0,58 ± 0,063,40 ± 0,4OFC lesione24292,5423171.4624630.9223994.50.3 ± 0.050.05 ± 0.01*5.5 ± 0.68*0/32 ± 0.05n/dn/d
Gli animali con lesioni ventrali OFC non rappresentano l’incertezza prevista nelle distribuzioni dei tempi di attesa
Per ottenere ulteriori approfondimenti sulle rappresentazioni dei risultati nei nostri gruppi sperimentali, abbiamo analizzato la microstruttura del comportamento di scelta dei ratti. In particolare, abbiamo affrontato se BLA e lesioni ventrali OFC ventrali alterato la capacità degli animali di formare aspettative circa i tempi di consegna dei premi. In ogni prova durante tutte le condizioni di base, in cui i valori complessivi delle opzioni LV e HV erano equivalenti, le entrate del porto di ricompensa sono state registrate in contenitori da 1 s durante il periodo di attesa (dopo che un ratto aveva indicato la sua scelta e fino alla consegna della ricompensa; gli istogrammi delle vere distribuzioni dei ritardi e delle azioni di ricerca di ricompensa degli animali normalizzati al numero totale di entrate del porto di ricompensa sono mostrati nella Figura 5). Questi dati sono stati analizzati con un ANOVA con il contenitore di tempo come all’interno di un gruppo di lesioni e tra i fattori soggettivi. Non ci sono state differenze significative nella media dei tempi di consegna dei premi previsti tra i gruppi [F(5,42)=1,064, p=0,394]. Allo stesso modo, tutti i gruppi sono stati abbinati nel numero totale di voci di porta di ricompensa [F(2,21)=0,462, p=0,636; Figura 5-figure supplement 1]. Tuttavia, è stata rilevata una differenza significativa nelle variazioni delle distribuzioni delle entrate dei porti di ricompensa [χ 2(209)=4004.054, p<0,0001]. Mentre le distribuzioni dei tempi di ricerca dei premi nei ratti colonizzati dal BLA erano indistinguibili da quelle degli animali di controllo e dai ritardi reali, gli animali colonizzati dall’OFC concentravano le loro entrate dei porti di ricompensa nell’intervallo di tempo corrispondente ai ritardi medi, suggerendo che mentre questi animali possono dedurre i risultati medi, non riescono a rappresentare la varianza (ad es, 10.7554/eLife.27483.016Cifra 5.Gli animali con lesioni ventrali OFC non rappresentano l’incertezza prevista nei ritardi di ricompensa.Abbiamo valutato se le lesioni BLA e le lesioni ventrali OFC alterano la capacità degli animali di formare aspettative sui tempi di consegna della ricompensa. In ogni prova durante tutte le condizioni di base in cui il valore complessivo delle opzioni LV e HV era equivalente, le entrate del porto di ricompensa sono state registrate in contenitori da 1 s durante il periodo di attesa. Non ci sono state differenze significative nelle modalità dei tempi di consegna dei premi previsti per i vari gruppi (p=0,394). Allo stesso modo, i gruppi sono stati uguagliati nel numero totale di entrate del porto a pagamento (p=0,636), come mostrato nella figura 5-figure supplement 1. Mentre le distribuzioni dei tempi di ricerca dei premi negli animali con lesioni BLA erano indistinguibili da quelle degli animali di controllo e dai ritardi reali (A-F), gli animalicon lesioni OFC hanno concentrato le loro registrazioni dei porti di ricompensa nell’intervallo di tempo corrispondente ai ritardi medi (G,H), suggerendo che mentre questi animali possono dedurre il risultato medio, non riescono a rappresentare la varianza (cioè l’incertezza attesa). Abbiamo anche considerato le variazioni dei tempi di attesa nel corso del nostro compito; questi dati sono mostrati nella Figura 5-figure supplement 1. Ogni barra nei grafici dell’istogramma rappresenta la frequenza media normalizzata al numero totale di ingressi della porta di ricompensa ±SEM.DOI:http://dx.doi.org/10.7554/eLife.27483.01610.7554/eLife.27483.017FigureSupplemento a 5 cifre 1.Numero totale di voci del porto di ricompensa e cambiamenti nelle variazioni dei tempi di attesa nelle varie fasi dell’attività. In ogni prova durante tutte le condizioni di base in cui il valore complessivo delle opzioni BT e AT erano equivalenti, le voci del porto di ricompensa sono state registrate in contenitori da 1 s durante il periodo di attesa.(A) Tutti i gruppi di animali sono stati abbinati nel numero totale di entrate del porto di ricompensa (p=0,636).(B) Abbiamo anche considerato i cambiamenti nei tempi di attesa durante il nostro compito. Abbiamo calcolato la variazione dei tempi di entrata nel porto di ricompensa durante ogni linea di base (fase iniziale del compito e quattro linee di base che separano i turni) separatamente per ogni animale. C’è stato un effetto principale significativo del gruppo di lesioni sulle variazioni dei tempi di attesa per l’opzione HV (p<0,0001) con animali con lesioni OFC che hanno dimostrato una variabilità costantemente inferiore nel loro comportamento di attesa, nonostante l’esperienza con i turni. I dati sono mostrati come mezzi di gruppo ± SEM, **p<0.01.DOI:http://dx.doi.org/10.7554/eLife.27483.017
Abbiamo anche considerato i cambiamenti nei tempi di attesa in tutto il nostro compito. Abbiamo calcolato la variazione dei tempi di ingresso al porto di ricompensa durante ogni linea di base (fase iniziale del compito e quattro linee di base che separano i turni) per ogni animale. Abbiamo poi sottoposto le varianze stimate alle ANOVA con ordine di base (dal 1 ° al 5 °) come all’interno del gruppo di lesioni e come fattori tra i soggetti. Analogamente alla nostra precedente analisi delle linee di base combinate, non abbiamo rilevato alcuna differenza di gruppo nei tempi di attesa per l’opzione LV (tutti i valori p>0,2). Tuttavia, c’è stato un effetto principale significativo del gruppo di lesioni sulle variazioni dei tempi di attesa per l’opzione HV [F(2,21)=117.074, p<0.0001; Figura 5-figure supplement 1] con animali con lesioni OFC che dimostrano una variabilità costantemente inferiore nel loro comportamento di attesa, nonostante l’esperienza con i turni. È importante notare che, poiché le nostre analisi includevano solo il tempo di attesa prima della consegna del premio, questi risultati suggeriscono che gli animali colonizzati da OFC mantengono la capacità di formare semplici aspettative di risultato basate su un’esperienza a lungo termine, ma la loro capacità di rappresentare le distribuzioni di risultato più complesse è compromessa.
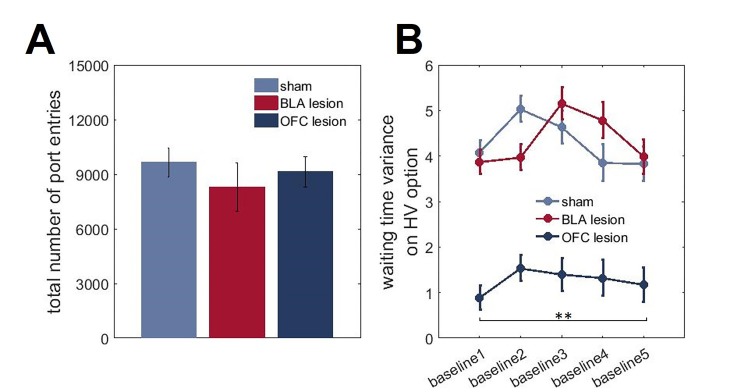
Figura 5-figure supplement 1.Gli animali con lesioni ventrali da OFC non riescono a rappresentare l’incertezza prevista nei ritardi di ricompensa.Abbiamo valutato se le lesioni BLA e le lesioni ventrali OFC alterano la capacità degli animali di formare aspettative sui tempi di consegna dei premi. In ogni prova durante tutte le condizioni di base in cui il valore complessivo delle opzioni BLA e HV era equivalente, le entrate del porto di ricompensa sono state registrate in contenitori da 1 s durante il periodo di attesa. Non ci sono state differenze significative nelle modalità dei tempi di consegna dei premi previsti per i vari gruppi (p=0,394). Allo stesso modo, i gruppi sono stati uguagliati nel numero totale di entrate del porto a pagamento (p=0,636), come mostrato nella figura 5-figure supplement 1. Mentre le distribuzioni dei tempi di ricerca dei premi negli animali con lesioni BLA erano indistinguibili da quelle degli animali di controllo e dai ritardi reali (A-F), gli animalicon lesioni OFC hanno concentrato le loro registrazioni dei porti di ricompensa nell’intervallo di tempo corrispondente ai ritardi medi (G,H), suggerendo che mentre questi animali possono dedurre il risultato medio, non riescono a rappresentare la varianza (cioè l’incertezza attesa). Abbiamo anche considerato le variazioni dei tempi di attesa nel corso del nostro compito; questi dati sono mostrati nella Figura 5-figure supplement 1. Ogni barra nei grafici dell’istogramma rappresenta la frequenza media normalizzata al numero totale di ingressi della porta di ricompensa ±SEM.DOI:
http://dx.doi.org/10.7554/eLife.27483.016In ogni prova, durante tutte le condizioni di base in cui il valore complessivo delle opzioni BT e AT era equivalente, le entrate dei porti a premio sono state registrate in contenitori da 1 s durante il periodo di attesa.(A) Tutti i gruppi di animali sono stati abbinati nel numero totale di entrate del porto di ricompensa (p=0,636).(B) Abbiamo anche considerato i cambiamenti nei tempi di attesa durante il nostro compito. Abbiamo calcolato la variazione dei tempi di entrata nel porto di ricompensa durante ogni linea di base (fase iniziale del compito e quattro linee di base che separano i turni) separatamente per ogni animale. C’è stato un effetto principale significativo del gruppo di lesioni sulle variazioni dei tempi di attesa per l’opzione HV (p<0,0001) con animali con lesioni OFC che hanno dimostrato una variabilità costantemente inferiore nel loro comportamento di attesa, nonostante l’esperienza con i turni. I dati sono mostrati come mezzi di gruppo ± SEM, **p<0,01.DOI:
http://dx.doi.org/10.7554/eLife.27483.017
Figura 5-figure supplement 1.Numero totale delle entrate del porto di ricompensa e delle variazioni dei tempi di attesa nelle varie fasi dell’attività.In ogni prova durante tutte le condizioni di base in cui il valore complessivo delle opzioni BT e AT erano equivalenti, le entrate dei porti di ricompensa sono state registrate in contenitori da 1 s durante il periodo di attesa.(A) Tutti i gruppi di animali sono stati abbinati nel numero totale di entrate del porto di ricompensa (p=0,636).(B) Abbiamo anche considerato i cambiamenti nei tempi di attesa durante il nostro compito. Abbiamo calcolato la variazione dei tempi di entrata nel porto di ricompensa durante ogni linea di base (fase iniziale del compito e quattro linee di base che separano i turni) separatamente per ogni animale. C’è stato un effetto principale significativo del gruppo di lesioni sulle variazioni dei tempi di attesa per l’opzione HV (p<0,0001) con animali con lesioni OFC che hanno dimostrato una variabilità costantemente inferiore nel loro comportamento di attesa, nonostante l’esperienza con i turni. I dati sono mostrati come mezzi di gruppo ± SEM, **p<0,01.DOI:
http://dx.doi.org/10.7554/eLife.27483.017
Le lesioni al BLA e all’OFC ventrale inducono un fenotipo che evita l’incertezza in condizioni di base
Per valutare le differenze di gruppo nella ricerca dell’incertezza o nell’evitare, abbiamo sottoposto i dati di preferenza dell’opzione HV in condizioni di base ad un ANOVA con il tempo (cinque test di base ripetuti che separano gli spostamenti di valore) come gruppo di appartenenza e di lesione come fattori tra i soggetti. Oltre ai loro effetti sull’apprendimento del valore, le lesioni sia al BLA che all’OFC ventrale hanno indotto un fenotipo evitante l’incertezza con animali in entrambi i gruppi sperimentali che hanno dimostrato una preferenza ridotta per l’opzione HV in condizioni di base rispetto al gruppo di controllo all’inizio del test [tempo x interazione del gruppo]: F(4.37,45.87) = 8.484, p<0.0001; post hoc sham vs BLA: p=0.002; sham vs OFC: p=0.002, Figura 6]. BLA-animali assediati hanno continuato ad evitare l’opzione incerta per tutta la durata del nostro esperimento (tutti i valori di p < 0,05, ad eccezione della valutazione di base tre quando questo gruppo non era diverso dagli animali di controllo). Tuttavia, gli animali con OFC hanno aumentato le loro scelte dell’opzione HV durante le condizioni di base con test ripetuti: erano indistinguibili dai controlli durante le linee di base 3 e 4 e hanno persino dimostrato una tendenza a una preferenza più elevata rispetto al gruppo di controllo durante l’ultima linea di base [test post hoc, OFC vs finto: p=0,059].10.7554/eLife.27483Abbiamo osservato una significativa riduzione della preferenza per l’opzione HV in condizioni di base in entrambi i gruppi sperimentali rispetto agli animali di controllo all’inizio dei test (sham vs BLA: p=0.002; sham vs OFC: p=0.002). Gli animali con BLA hanno continuato ad evitare l’opzione rischiosa per la maggior parte dell’esperimento (tutti i valori di p < 0,05, ad eccezione della valutazione della linea di base tre quando questo gruppo non era diverso dagli animali di controllo). Gli animali con OFC hanno progressivamente aumentato le loro scelte dell’opzione HV durante le condizioni di base con test ripetuti: erano indistinguibili dai controlli durante le linee di base 3 e 4 e hanno persino dimostrato una tendenza a una preferenza più elevata rispetto al gruppo di controllo durante l’ultima linea di base [test post hoc, OFC vs finto: p=0,059]. I dati sono mostrati come mezzi di gruppo per condizione ±SEM, *p<0.05, **p<0.01. Le statistiche di riepilogo e i dati individuali degli animali sono forniti nella figura 6-source data 1.DOI:http://dx.doi.org/10.7554/eLife.27483.01810.7554/eLife.27483.019Figure6-source data 1.Summary statistics and individual data for HV option preference following lesions.DOI:http://dx.doi.org/10.7554/eLife.27483.019
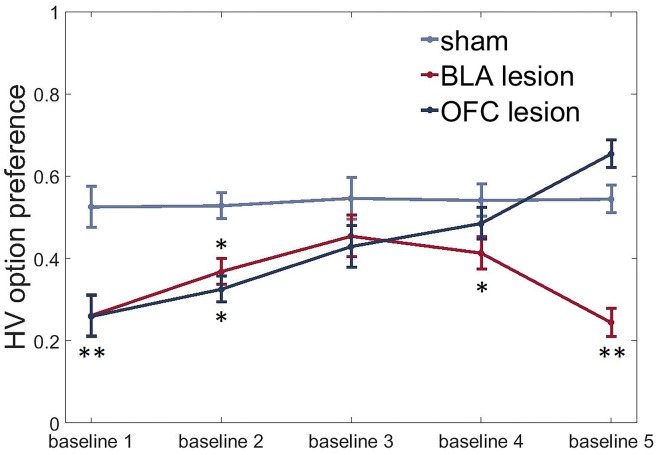
Figura 6 – Dati sorgente 1.Statistiche di riepilogo e dati individuali per la preferenza dell’opzione HV a seguito di lesioni.statistiche di riepilogo e dati individuali per la preferenza dell’opzione HV a seguito di lesioni.Abbiamo osservato una significativa riduzione della preferenza per l’opzione HV in condizioni di base in entrambi i gruppi sperimentali rispetto agli animali di controllo all’inizio del test (sham vs BLA: p=0,002; sham vs OFC: p=0,002). Gli animali con BLA hanno continuato ad evitare l’opzione rischiosa per la maggior parte dell’esperimento (tutti i valori di p < 0,05, ad eccezione della valutazione della linea di base tre quando questo gruppo non era diverso dagli animali di controllo). Gli animali con OFC hanno progressivamente aumentato le loro scelte dell’opzione HV durante le condizioni di base con test ripetuti: erano indistinguibili dai controlli durante le linee di base 3 e 4 e hanno persino dimostrato una tendenza a una preferenza più elevata rispetto al gruppo di controllo durante l’ultima linea di base [test post hoc, OFC vs finto: p=0,059]. I dati sono mostrati come mezzi di gruppo per condizione ±SEM, *p<0.05, **p<0.01. Le statistiche riassuntive e i dati dei singoli animali sono forniti nella Figura 6 – dati fonte 1.1. DOI:
http://dx.doi.org/10.7554/eLife.27483.01810.7554/eLife.27483.019Cifre dati a 6 fonti 1.Statistiche di sintesi e dati individuali per la preferenza dell’opzione HV in seguito a lesioni.DOI:http://dx.doi.org/10.7554/eLife.27483.019DOI:
http://dx.doi.org/10.7554/eLife.27483.019DOI:
http://dx.doi.org/10.7554/eLife.27483.019
Discussione
Le statistiche di ricompensa volatile sono state una delle caratteristiche centrali degli habitat ancestrali, favorendo la selezione di fenotipi comportamentali in grado di far fronte all’incertezza(Emery, 2006; Potts, 2004; Steppan et al., 2004). La maggior parte dei mammiferi è in grado di apprendere statistiche ambientali di ordine superiore(Cikara e Gershman, 2016; Gershman e Niv, 2010; Niv et al., 2015) e di ottimizzare i tassi di apprendimento in base al grado di incertezza(Behrens et al., 2007; Nassar et al., 2010; Payzan-LeNestour e Bossaerts, 2011). Fino a poco tempo fa, la maggior parte degli studi sono stati condotti nel contesto del feedback probabilistico, dove la stocasticità dei risultati è guidata dall’omissione della ricompensa in un sottoinsieme di prove. A differenza dei compiti di laboratorio, l’incertezza in contesti naturalistici non si limita ai risultati binari probabilistici, ma include anche la variabilità dei ritardi e dei costi di sforzo necessari per ottenere i premi desiderati. Nel presente lavoro, abbiamo sviluppato un compito basato sui ritardi per i ratti per indagare gli effetti dell’incertezza dei risultati attesi sull’apprendimento dei valori. I nostri risultati forniscono la prima prova che i ratti possono rilevare e conoscere i veri cambiamenti nei valori dei risultati anche quando si verificano in un contesto di costi stocastici di ritardo. Nel nostro compito, gli animali hanno modificato con successo il loro comportamento di scelta in risposta ai cambiamenti direzionali nelle distribuzioni di ritardo (cioè, i turni di valore su e giù) per massimizzare il tasso di acquisizione di ricompensa, mantenendo le preferenze di scelta stabili nonostante la variabilità dei risultati in condizioni di base.
Notiamo che i cambiamenti nelle preferenze delle opzioni in risposta agli spostamenti sulle opzioni HV e LV sono stati asimmetrici: la maggiore varianza della distribuzione dei risultati ha facilitato gli adattamenti comportamentali in risposta ai rialzi di valore; al contrario, la bassa incertezza dei risultati attesi ha portato a risposte potenziate ai rialzi di valore. Questo effetto può essere spiegato dalla natura iperbolica del conteggio dei ritardi tra le specie(Freeman et al., 2009; Green et al., 2013; Hwang et al., 2009; Mazur e Biondi, 2009; Mitchell et al., 2015; Rachlin et al., 1991). In particolare, i ritardi nel nostro compito sono stati normalmente distribuiti, ma le distribuzioni di valore percepite possono essere distorte. Poiché l’opzione HV produce una maggiore proporzione di premi immediati o a breve termine, e quindi risultati più preziosi, può essere generalmente più facile per gli animali rilevare i turni di lavoro in aumento su questa opzione. Queste ricompense più immediate possono essere più salienti e/o più preferite. Al contrario, durante i turni inferiori, man mano che i ritardi si allungano, le differenze nei tempi di attesa diventano meno significative e l’opzione LV che produce più ritardi di valore simile potrebbe promuovere un apprendimento più rapido sul peggioramento delle condizioni di ricompensa.
Nonostante questi effetti dei ritardi sulla valutazione dei risultati, i nostri risultati hanno dimostrato che i ratti possono imparare a conoscere i cambiamenti di valore anche quando i risultati sono incerti. Abbiamo quindi valutato direttamente gli adattamenti neurali indotti dall’incertezza all’interno del BLA e dell’OFC e abbiamo indagato i contributi causali di queste regioni cerebrali per valutare l’apprendimento e il processo decisionale in base all’incertezza dei risultati attesi.
Il BLA e l’OFC ventrale subiscono modelli distinti di neuroadattamenti in risposta all’incertezza dell’esito
Una delle sfide più difficili affrontate da un animale che impara in un habitat instabile è la corretta distinzione tra i veri cambiamenti dell’ambiente che richiedono un nuovo apprendimento dal feedback stocastico in condizioni per lo più stabili. Infatti, il problema del rilevamento dei punti di cambiamento è stato a lungo studiato in relazione alla modulazione dei tassi di apprendimento nella teoria dell’apprendimento RL e Bayesiana(Behrens et al., 2007; Courville et al., 2006; Dayan et al., 2000; Gallistel et al., 2001; Pearce e Hall, 1980; Pearson e Platt, 2013; Yu e Dayan, 2005). Gli adattamenti neurologici a lungo termine in risposta all’esperienza con l’incertezza dell’esito possono favorire l’apprendimento modificando l’elaborazione del segnale-rumore(Hoshino, 2014; Liguz-Lecznar et al., 2015; Rössert et al., 2011), in modo tale che solo quegli eventi sorprendenti che superano i livelli di variabilità previsti nell’ambiente producono risposte neuronali e influenzano il comportamento.
Abbiamo valutato direttamente i cambiamenti nell’espressione della gefirina (un proxy affidabile per i recettori GABAAA inseriti nella membrana che mediano una rapida trasmissione inibitoria;[Chhatwal et al., 2005; Tyagarajan et al., 2011]) e GluN1 (una sottounità obbligatoria dei recettori NMDA del glutammato;[Soares et al., 2013]) in BLA e OFC ventrale in tre gruppi separati di animali a seguito di una lunga esperienza con bassi ed alti livelli di incertezza attesa nella distribuzione dei risultati. Sia la gefirina che il GluN1 hanno mostrato una robusta upregolazione dipendente dall’incertezza nel BLA che è stata massima dopo l’esperienza con condizioni altamente incerte. Al contrario, all’interno dell’OFC ventrale, la gefirina è stata downregolamentata in seguito all’esperienza di ricompensa in generale e non dipendeva dal grado di incertezza negli esiti. Tuttavia, i nostri esperimenti non includevano un certo gruppo di controllo (cioè gli animali che ricevevano ricompense a seguito di un ritardo prevedibile su tutti gli esperimenti). Pertanto, non possiamo escludere la possibilità che i cambiamenti nell’espressione della proteina nell’OFC in risposta all’esperienza di ricompensa abbiano richiesto alcuni, anche se piccoli, livelli di incertezza dell’esito.
Gli adattamenti all’incertezza prevista a livello proteico sono suscettibili di diminuire le risposte ai successivi segnali di sorpresa prova per prova nel BLA. Gli aumenti simultanei della sensibilità all’eccitazione e all’inibizione favoriscono l’elaborazione segnale-rumore, fornendo ulteriori prove a sostegno di questa visione(Hoshino, 2014; Liguz-Lecznar et al., 2015; Rössert et al., 2011). Per rilevare i cambiamenti ambientali, gli animali devono confrontare gli errori di previsione attuali con i livelli di incertezza dei risultati attesi. I lavori precedenti hanno dimostrato che gli interneuroni GABA-ergici in BLA gate il flusso di informazioni e determinare l’intensità del segnale che viene passato alle strutture postsinaptiche(Wolff et al., 2014). L’eccitabilità intrinseca dei neuroni piramidali(Motanis et al., 2014; Paton et al., 2006) e l’attività degli interneuroni nel BLA sono modellati da esperienze di ricompensa, possibilmente attraverso un meccanismo dipendente dalla dopamina(Chu et al., 2012; Merlo et al., 2015). L’interpretazione dei recettori funzionali GABAA come suggerito dai nostri dati può diminuire la sensibilità agli eventi sorprendenti quando la variabilità del risultato è elevata anche in condizioni per lo più stabili, mentre l’aumento del GluN1 potrebbe supportare la facilitazione dell’apprendimento quando l’ambiente cambia. Diverse condizioni psichiatriche come ansia, schizofrenia, disturbi dello spettro ossessivo compulsivo e autistico, condividono l’elaborazione dell’incertezza patologica come deficit di base, manifestandosi come una preferenza per esiti stabili e certi(Winstanley e Clark, 2016a, 2016b). È interessante notare che studi recenti hanno analogamente implicato mutazioni nel gene della gefirina come rischio per l’autismo e la schizofrenia(Chen et al., 2014; Lionel et al., 2013). La ricerca futura potrebbe affrontare il ruolo di questo organizzatore sinaptico nell’apprendimento guidato dalla sorpresa e nel processo decisionale sotto l’incertezza dei modelli animali di questi disturbi.
Contrariamente al modello di neuroadattamenti osservato nel BLA, la gefirina nell’OFC è stata ridimensionata in risposta alla media di ricompensa, ma non all’incertezza prevista. Questi cambiamenti nell’espressione della proteina possono lasciare la responsività dell’OFC a segnali di valore rumoroso intatti o addirittura amplificati, suggerendo che una delle sue funzioni normali è quella di codificare la ricchezza della distribuzione del risultato o del segnale di incertezza previsto. Infatti, i rapporti precedenti hanno dimostrato che almeno alcune sottopopolazioni di neuroni OFC sono portatori di rappresentazioni dell’incertezza attesa durante la valutazione delle opzioni e la ricezione dei risultati(Li et al., 2016; van Duuren et al., 2009). Sulla base di questi risultati abbiamo ipotizzato che il BLA e l’OFC ventrale possano giocare ruoli complementari, ma dissociabili, nel processo decisionale e nell’apprendimento in condizioni di incertezza.
L’OFC ventrale contribuisce in modo causale all’apprendimento nell’incertezza dei risultati attesi
Le lesioni all’OFC ventrale hanno prodotto una pronunciata compromissione comportamentale del nostro compito. Questi animali non sono riusciti a cambiare la loro preferenza di scelta in risposta alla maggior parte dei turni. Paradossalmente, i risultati della modellazione computazionale hanno rivelato che la risposta a risultati sorprendenti è stata facilitata in questi ratti. In particolare, le prestazioni degli animali affetti da OFC erano meglio rappresentate dal modello PH, suggerendo che mentre questi animali aumentavano ancora i tassi di apprendimento in risposta alla sorpresa (cioè, errori di previsione assoluti), erano insensibili all’incertezza dei risultati attesi. A causa della mancanza di una scalatura degli errori di previsione basata sulla variabilità dei risultati sperimentati, gli animali colonizzati da OFC hanno trattato ogni evento sorprendente come indicativo di un cambiamento fondamentale nella distribuzione del valore e hanno aggiornato le loro aspettative, rendendo più rumorose le rappresentazioni dei valori prova per prova, impedendo cambiamenti coerenti nelle preferenze. Poiché le distribuzioni di ritardo incontrate durante la linea di base e le condizioni di spostamento nel nostro compito si sono parzialmente sovrapposte, l’incapacità di ignorare le fluttuazioni senza senso dei risultati porterebbe a un comportamento di scelta instabile e a un apprendimento attenuato.
Le analisi complementari della strategia win-stay/shift-shift forniscono un ulteriore supporto per una maggiore sensibilità a feedback sorprendenti in questi animali: una maggiore responsività sia alle vittorie che alle perdite è emersa a seguito di lesioni ventrali OFC. Si noti che una maggiore dipendenza da questa strategia è altamente subottimale in condizioni di ricompensa ambientale stocastica(Faraut et al., 2016; Imhof et al., 2007; Worthy et al., 2013). Inoltre, abbiamo osservato una significativa riduzione dei valori β (parametro della temperatura inversa nella regola di decisione softmax) nel gruppo OFC-lesionato, indicando un processo di scelta più rumoroso e una diminuzione dell’affidamento sui valori di risultato appresi in questi animali. Questi risultati sono in accordo con i risultati precedenti che dimostrano una maggiore commutazione e preferenze economiche incoerenti a seguito di lesioni ventrali OFC nelle scimmie(Walton et al., 2010, 2011). Allo stesso modo, le lesioni alla corteccia prefrontale ventromediale, che comprende l’OFC ventrale, negli esseri umani rendono i soggetti incapaci di esprimere giudizi di preferenza coerenti(Fellows e Farah, 2003, 2007). È importante notare che i soggetti umani con danni da OFC non sono in grado di distinguere tra i gradi di incertezza(Hsu et al., 2005). Allo stesso modo, il lavoro precedente ha coinvolto questa regione cerebrale nella previsione dei tempi di ricompensa(Bakhurin et al., 2017). Abbiamo affrontato direttamente se le lesioni BLA e le lesioni ventrali OFC alterano la capacità degli animali di formare aspettative circa l’incertezza prevista nei tempi di consegna dei premi sul nostro compito. Mentre le distribuzioni dei tempi di consegna dei premi negli animali con lesioni BLA erano indistinguibili da quelle degli animali di controllo e dai ritardi reali, gli animali con lesioni OFC hanno concentrato le loro entrate nel porto di ricompensa nell’intervallo di tempo corrispondente ai ritardi medi, suggerendo che mentre questi animali possono dedurre i risultati medi, non riescono a rappresentare la varianza (cioè l’incertezza attesa). Questi risultati sono coerenti con l’evidenza emergente che più regioni ventromediali, a differenza di quelle laterali, gli OFC possono essere critici per il processo decisionale che coinvolge l’incertezza dell’esito, ma non l’inibizione della risposta o il comportamento di scelta impulsiva come suggerito in precedenza(Stopper et al., 2014).
Anche se spesso inquadrato come un deficit nel controllo inibitorio(Bari e Robbins, 2013; Dalley et al., 2004; Elliott e Deakin, 2005), le lesioni o le inattivazioni mediali di OFC inducono effetti analoghi nelle attività di apprendimento probabilistiche di inversione dove si verificano cambiamenti sorprendenti nella distribuzione dei premi sullo sfondo degli esiti stocastici durante le condizioni di base. Ad esempio, un recente studio sui roditori ha confrontato sistematicamente i contributi di cinque diverse regioni della corteccia frontale all’apprendimento dell’inversione(Dalton et al., 2016). I risultati hanno rivelato contributi unici dell’OFC a prestazioni di successo in condizioni probabilistiche, ma non deterministiche. Intrigante, le inattivazioni dell’OFC mediale hanno compromesso sia la fase di acquisizione che quella di inversione, suggerendo che questa sottoregione potrebbe essere critica per molti tipi di apprendimento di ricompensa in condizioni di incertezza del risultato atteso. Dal momento che le nostre lesioni si sono intromesse anche sull’OFC mediale, le nostre attuali osservazioni sono in accordo con questi risultati e suggeriscono che una delle normali funzioni di più settori ventromediali di OFC potrebbe essere quella di stabilizzare le rappresentazioni di valore aggiustando le risposte ai risultati sorprendenti sulla base dell’incertezza di esito previsto.
Analogamente al lavoro precedente, che dimostrava che l’OFC non è necessario per l’acquisizione di semplici associazioni di stimolo-risultato o per lo sblocco guidato da differenze di valore quando i risultati sono certi e prevedibili(Izquierdo et al., 2004; McDannald et al., 2011, 2005; Stalnaker et al., 2015), abbiamo osservato prestazioni intatte negli animali affetti da OFC durante l’addestramento per rispondere alle ricompense. È stato precedentemente proposto che l’OFC possa fornire aspettative di valore che possono essere utilizzate per calcolare i RPE per guidare l’apprendimento in condizioni di compiti più complessi(Schoenbaum et al., 2011a, Schoenbaum et al., 2011b). Anche se questa proposta iniziale si basava sui risultati ottenuti dopo aver preso di mira più sottoregioni laterali dell’OFC, le nostre osservazioni sono generalmente coerenti con questa visione e aggiungono una prospettiva sfumata. In particolare, se l’OFC è necessario per fornire aspettative sul valore a cui vengono poi confrontati i risultati osservati, le lesioni di questa regione cerebrale possono risultare in un apprendimento attenuato guidato dalla violazione delle aspettative. I risultati della modellazione computazionale nel nostro lavoro hanno rivelato una riduzione dei tassi di apprendimento negli animali affetti da OFC coerente con questo conto. Tuttavia i nostri dati forniscono un’ulteriore prova del fatto che le rappresentazioni dei risultati attesi negli OFC ventrali non si limitano a una stima del valore in un unico punto, ma includono anche informazioni sull’incertezza attesa della variabilità dei risultati. Ciò consentirebbe a un animale non solo di rilevare se gli esiti violano le aspettative, ma anche di valutare se tali eventi sorprendenti sono significativi e informativi per lo stato attuale del mondo. Se tali eventi sono importanti, un animale modificherà il suo comportamento, ma se si sono verificati per caso, le scelte dovrebbero rimanere invariate.
Infine, più recentemente è stato anche suggerito che l’OFC rappresenta la posizione attuale di un animale all’interno di una mappa cognitiva astratta del compito che sta affrontando (Chanet al., 2016; Schuck et al., 2016; Wilson et al., 2014), in particolare quando gli stati del compito non sono segnalati da informazioni sensoriali esterne, ma devono essere dedotti dall’esperienza. Nel nostro compito, gli animali possono rappresentare in modo simile condizioni diverse, ambiente stabile contro valore spostato, come stati separati. L’apprendimento attenuato può risultare da rappresentazioni errate dello stato, in cui un animale erroneamente afferma di essere attualmente in un ambiente stabile e persiste con la politica di scelta precedente, nonostante lo spostamento di valore. Come è stato riportato di recente, l’attività neuronale nell’OFC laterale organizza lo spazio di lavoro secondo la sequenza di eventi comportamentali significativi, o epoche di prova. Al contrario, gli insiemi neuronali nell’OFC più mediale non seguono la sequenza degli eventi, ma si separano tra gli stati a seconda del valore di prova(Lopatina et al., 2017). Nel nostro studio, l’OFC ventromediale può essere particolarmente ben posizionato per codificare gli upshifts e downshifts in valore su lunghi intervalli di tempo, e la perdita di questa funzione potrebbe causare l’incapacità di recuperare le rappresentazioni appropriate dello stato al momento della scelta dell’opzione.
Considerati insieme ai risultati precedenti, i nostri risultati implicano l’OFC nella rappresentazione di distribuzioni di valore a grana fine, inclusa l’incertezza attesa nei risultati (che può essere dipendente dallo stato del compito). Di conseguenza, non avendo accesso alla complessa distribuzione dei risultati, gli animali con lesioni OFC si basano in misura eccessiva sul valore medio memorizzato.
Il BLA funzionalmente intatto è necessario per facilitare l’apprendimento in risposta alla sorpresa
Mentre le lesioni da OFC hanno prodotto un marcato deterioramento delle prestazioni nel nostro compito di incertezza, se le alterazioni indotte dalle lesioni da BLA portano a un comportamento non ottimale è meno chiaro. Questi animali hanno cambiato la loro preferenza di opzione in misura minore durante i turni di lavoro in alta tensione, ma sono stati compensati da adattamenti esagerati ai turni di lavoro in bassa tensione. Analisi più dettagliate dei dati sessione per sessione hanno rivelato un’alterazione specifica nelle risposte ai sorprendenti spostamenti di valore in HV, ma non in LV, condizioni in questo gruppo. Coerentemente con l’apprendimento attenuato osservato negli animali con lesioni BLA, le prestazioni prova per prova in questo gruppo si sono adattate meglio con un modello di incertezza RW+previsto, dimostrando una perdita selettiva della scala del tasso di apprendimento in risposta alla sorpresa e preservando la scala RPE con l’incertezza attesa del risultato, portando a un apprendimento del valore più lento rispetto agli animali intatti durante l’upshift HV. Si noti che una performance non ottimale anche durante due o tre sessioni nel nostro compito (ogni sessione dura 60 prove) significa che gli animali affetti da BLA sono meno efficienti nel premiare l’acquisizione di 120-180 esperienze. In contesti naturalistici, un tale deficit di apprendimento precoce può avere conseguenze dannose. In accordo con i risultati della modellazione computazionale, gli animali colonizzati con il BLA hanno avuto meno probabilità di adottare la strategia “vinci-stai/perdite” rispetto al gruppo di controllo, dimostrando una minore sensibilità a risultati sorprendenti.
Mentre la mancanza di facilitazione dell’apprendimento può spiegare la riduzione dei cambiamenti di preferenza in risposta ai cambiamenti di HV upshift negli animali con assuefazione al BLA, può sembrare in contrasto con le risposte potenziate ai cambiamenti al ribasso di questa opzione. I nostri risultati della modellazione computazionale suggeriscono che gli animali di controllo potenziano il loro apprendimento in risposta a risultati altamente sorprendenti, il che porta a maggiori adattamenti comportamentali nelle prime sessioni durante i turni. Negli animali affetti da BLA, questa funzione viene persa, e l’apprendimento procede allo stesso ritmo. Questo si traduce in adattamenti di scelta significativamente ridotti durante le sessioni di upshift HV. Tuttavia, gli animali asserviti al BLA si adattano molto di più all’opzione HV con il downshift. Questa differenza sembra essere nell’asintoto delle prestazioni, dato che l’apprendimento continua a progredire linearmente nel gruppo di persone affette da BLA. Un paio di fattori possono guidare questo effetto. In primo luogo, come discusso in precedenza, lo sconto iperbolico porta a un maggiore impatto di brevi ritardi sul comportamento. I premi immediati o a breve ritardo che si incontrano durante l’upshift sull’opzione HV potenzieranno l’apprendimento negli animali di controllo all’inizio del turno, ma non riescono a farlo negli animali con lesioni BLA. Durante il downshift sull’opzione HV, man mano che i ritardi si allungano, le differenze nei tempi di attesa diventano meno significative in quanto vi è un effetto minore di ritardi maggiori sui valori di risultato percepiti. Pertanto, l’apprendimento sarà potenziato, ma solo brevemente negli animali di controllo, ma procederà comunque in modo lineare nei ratti affetti da BLA. Inoltre, le risposte potenziate ai rallentamenti sull’opzione HV in questo gruppo possono derivare dall’evitare l’incertezza che interagisce con l’apprendimento guidato dalla sorpresa. Infatti, abbiamo osservato un consistente aumento dell’avversione all’incertezza negli animali affetti da BLA. I nostri modelli computazionali non hanno incluso un parametro esplicito di prevenzione dell’incertezza, poiché eravamo interessati principalmente ad esplorare le alterazioni nell’apprendimento.
I risultati precedenti hanno implicato il BLA nell’aggiornamento delle aspettative di ricompensa quando le previsioni e i risultati sono incongruenti e facilitano l’apprendimento in risposta ad eventi sorprendenti(Ramirez e Savage, 2007; Savage et al., 2007; Wassum e Izquierdo, 2015). In effetti, l’apprendimento del valore predittivo nell’amigdala comporta una firma neuronale che si accorda con un algoritmo RL(Dolan, 2007). In particolare, le risposte di una singola unità nel BLA corrispondono ai segnali di errore predittivo non firmati(Roesch et al., 2010) che sono necessari per la scalatura del tasso di apprendimento sia nei modelli di aggiornamento RL che in quelli Bayesiani. Il BLA utilizza gli errori di previsione positivi e negativi per aumentare l’elaborazione degli stimoli, indirizzando potenzialmente l’attenzione agli stimoli rilevanti e potenziando l’apprendimento(Chang et al., 2012; Esber e Holland, 2014), come dimostrato nelle procedure di downshift con riduzioni dell’importo della ricompensa. Questi effetti sono spesso interpretati come un miglioramento della associabilità delle stecche indotta dalla sorpresa. In particolare, un ruolo computazionale simile per l’amigdala è stato proposto sulla base del condizionamento della paura pavloviana negli esseri umani, dove le associazioni di cue-shock erano anche probabilistiche, evidenziando il ruolo generale per l’amigdala nel perfezionamento dell’apprendimento secondo il grado di sorpresa(Li et al., 2011). Presi insieme, la letteratura accumulata suggerisce che questo contributo del BLA è evidente sia per gli esiti appetitivi che per quelli avversivi, per gli spunti in diverse modalità sensoriali, e come dimostriamo qui, il ruolo non si limita ai cambiamenti nelle contingenze di esito, ma supporta anche l’apprendimento sui sorprendenti cambiamenti nei costi del ritardo.
Le lesioni da BLA e OFC inducono l’incertezza-elusione
Oltre ai loro effetti sull’apprendimento del valore, le lesioni sia al BLA che all’OFC ventrale hanno indotto un fenotipo evitante l’incertezza con animali in entrambi i gruppi sperimentali che hanno dimostrato una ridotta preferenza per l’opzione HV in condizioni di base rispetto al gruppo di controllo all’inizio del test. Allo stesso modo, i risultati precedenti hanno dimostrato che le lesioni o le inattivazioni del BLA spostano il comportamento lontano da opzioni incerte e promuovono scelte di risultati più sicuri(Ghods-Sharifi et al., 2009; Zeeb e Winstanley, 2011). Tuttavia, le inattivazioni dell’OFC mediale hanno dimostrato di produrre spostamenti consistenti verso l’opzione incerta(Winstanley e Floresco, 2016b). Nonostante la marcata avversione al rischio all’inizio del compito, gli animali asserviti agli OFC nei nostri esperimenti hanno progressivamente aumentato la loro preferenza per l’opzione HV con l’esperienza, suggerendo che gli effetti sulla preferenza per la scelta stabile dipendono in modo critico dai tempi delle manipolazioni degli OFC.
In sintesi, dimostriamo che sia il BLA che l’OFC ventrale sono coinvolti in modo causale nel processo decisionale e nell’apprendimento del valore in condizioni di incertezza dell’esito. Il BLA funzionalmente intatto è necessario per facilitare l’apprendimento in risposta alla sorpresa, mentre l’OFC ventrale è necessario per una rappresentazione accurata delle distribuzioni dei risultati per stabilizzare le aspettative di valore e mantenere le preferenze di scelta.
Materiali e metodi
I soggetti erano 56 ratti maschi ingenui di razza Long Evans (Charles River Laboratories, Crl:LE, codice ceppo: 006). Tutti gli animali sono arrivati alla nostra struttura al PND 70 (range di peso 300-350 all’arrivo). Vivaria sono stati mantenuti sotto un ciclo invertito di 12/12 ore luce/buio a 22°C. I ratti sono stati lasciati indisturbati per 3 giorni dopo l’arrivo nella nostra struttura per acclimatarsi al vivarium. Ogni ratto è stato poi maneggiato per un minimo di 10 minuti una volta al giorno per 5 giorni. Gli animali sono stati sottoposti a restrizioni alimentari per garantire la motivazione a lavorare per il cibo per una settimana prima e durante il test comportamentale, mentre l’acqua era disponibile ad libitum, tranne che durante il test comportamentale. Tutti gli animali sono stati alloggiati in coppia all’arrivo e separati l’ultimo giorno di manipolazione per ridurre al minimo l’aggressività durante la restrizione alimentare. Ci siamo assicurati che gli animali non scendessero al di sotto dell’85% del loro peso corporeo ad alimentazione libera. Negli ultimi due ultimi giorni di restrizione alimentare prima dell’addestramento comportamentale, i ratti sono stati alimentati con 20 pellet di zucchero nella loro gabbia di casa per abituarli alle ricompense alimentari. Tutte le procedure comportamentali ha avuto luogo 5 giorni alla settimana tra le 8:00 e le 18:00 durante il periodo attivo dei ratti. Poiché abbiamo utilizzato un nuovo compito decisionale, non abbiamo utilizzato un’analisi di potenza a priori per determinare la dimensione del campione per la coorte iniziale di animali ingenui. La dimensione del gruppo scelto (n = 8) è coerente con i rapporti precedenti nel nostro laboratorio. Per i successivi esperimenti comportamentali con lesioni finte, OFC, o BLA abbiamo determinato i numeri degli animali utilizzando una stima a priori della dimensione del campione per la famiglia di test F in G*Power 3.1(http://www.gpower.hhu.de/en.html). Le analisi si sono basate sui parametri di varianza ottenuti negli esperimenti pilota (riportati in Figura 1 e associati Figura 1-dati sorgente 1) e il numero di variabili indipendenti così come le interazioni di interesse nelle analisi pianificate. L’analisi ha prodotto un minimo previsto di 7-8 animali per gruppo quando non sono necessarie procedure chirurgiche. Tuttavia, considerando la possibilità di logorio chirurgico, abbiamo impostato n = 8 per gruppo. I protocolli di ricerca sono stati approvati dal Comitato per la ricerca sugli animali del Cancelliere dell’Università della California, Los Angeles.
Formazione comportamentale
L’addestramento comportamentale è stato condotto in camere di condizionamento operante (Modello 80604, Lafayette Instrument Co., Lafayette, IN) che sono state alloggiate all’interno di cabine di attenuazione del suono e della luce. Ogni camera era dotata di una luce della casa, di un generatore di toni, di una videocamera e di uno schermo tattile LCD che si opponeva al distributore di pellet. Il distributore di pellet erogava 45 mg di saccarosio di precisione senza polvere. Il software (ABET II TOUCH; Lafayette Instrument Co., modello 89505) controllava l’hardware. Tutti i programmi di test sono stati programmati dal nostro gruppo e possono essere richiesti all’autore corrispondente. Durante l’assuefazione, ai ratti è stato richiesto di mangiare cinque pellet di zucchero dal dispenser all’interno delle camere entro 15 minuti prima dell’esposizione a qualsiasi stimolo sul touchscreen. Sono stati poi addestrati a rispondere agli stimoli visivi presentati nello scomparto centrale dello schermo entro un intervallo di tempo di 40 s per ricevere la ricompensa dello zucchero. Durante la fase successiva dell’addestramento, gli animali hanno imparato ad avviare la prova puntando il naso sullo stimolo quadrato bianco brillante presentato nello scomparto centrale dello schermo tattile entro 40 s; questa risposta è stata seguita dalla scomparsa dello stimolo centrale e dalla presentazione di un’immagine target in uno degli scomparti laterali dello schermo tattile (immediatamente a sinistra o a destra dello stimolo di avvio). Ai ratti sono stati dati 40 s per rispondere all’immagine target, a cui è seguita una ricompensa immediata. L’ultima fase dell’addestramento è stata somministrata per familiarizzare gli animali con i risultati ritardati. Il protocollo è stato identico alla fase precedente, tranne il nosepoke all’immagine di destinazione e la consegna ricompensa sono stati separati da un ritardo stabile 5 s. In tutte le fasi di pre-formazione, la mancata risposta ad uno stimolo visivo entro il tempo assegnato ha fatto sì che la prova sia stata valutata come un’omissione e l’inizio di un ITI di 10 s. Tutte le immagini utilizzate nel pre-formazione sono state estratte dalla libreria di oltre 100 stimoli visivi e non sono mai state le stesse immagini utilizzate nei test comportamentali descritti di seguito. Ciò è stato fatto per garantire che nessuno degli stimoli visivi acquisisse un valore di incentivo che potesse influenzare le prestazioni successive. Il criterio per l’avanzamento nella fase successiva è stato fissato a 60 premi raccolti in 45 minuti.
Test comportamentali
La progettazione dei compiti e il comportamento degli animali intatti sono illustrati nella Figura 1, Video 1 e Video 2. Il nostro compito è progettato per valutare gli effetti dell’incertezza dei risultati previsti sull’apprendimento. Abbiamo scelto di concentrarci sul tasso di ricompensa (il valore del risultato è stato determinato dal ritardo nella ricezione della ricompensa) piuttosto che sull’entità della ricompensa per evitare il problema della sazietà durante tutta la sessione di test. Ogni prova è iniziata con la presentazione dello stimolo (quadrato bianco brillante) nello scomparto centrale del touchscreen. Ai ratti sono stati dati 40 s per iniziare una prova. Se 40 s passavano senza una risposta, la prova veniva valutata come una “omissione di inizio”. A seguito di un nosepoke al compartimento centrale, la stecca centrale è scomparsa e due stimoli di scelta sono stati presentati contemporaneamente in ciascuno dei compartimenti laterali del touchscreen permettendo ad un animale una libera scelta tra due opzioni di ricompensa. Nel nostro compito le assegnazioni laterali stimolo-risposta sono state tenute costanti per ogni animale per facilitare l’apprendimento. I compiti di stimolo laterale sono stati controbilanciati tra gli animali e tenuti costanti tra una sessione e l’altra. Ogni opzione di risposta è stata associata alla consegna di un pellet di zucchero dopo un intervallo di ritardo. I ritardi associati a ciascuna opzione sono stati messi in comune da distribuzioni che sono identiche nel valore medio, ma diverse nella variabilità (LV vs HV; ~N(µ, σ): μ = 10 s, σ HV=4s σ LV=1s). Ad un animale sono stati dati 40 s per fare una scelta; la mancata selezione di un’opzione entro questo intervallo di tempo ha fatto sì che la prova venisse valutata come “omissione di scelta” e l’inizio di un ITI.
Pertanto, i ratti sono stati presentati con due opzioni identiche in media (10 s) ma diverse nella varianza della distribuzione del ritardo (cioè, l’incertezza del risultato atteso). Dopo aver stabilito una performance stabile (definita come nessuna differenza statistica in uno qualsiasi dei parametri comportamentali in tre sessioni di test consecutivi), i ratti hanno sperimentato upshifts di ricompensa (la media del ritardo è stata ridotta a 5 s con varianza mantenuta costante) e downshifts (20 s) su ogni opzione in modo indipendente, seguiti da un ritorno alle condizioni di base. Così, nei turni in salita i ratti sono stati tenuti ad aspettare meno in media per un singolo pellet di zucchero, mentre nei turni in discesa, i ratti sono stati tenuti ad aspettare più a lungo, in media. L’ordine delle esperienze di turno è stato controbilanciato tra gli animali. Agli animali è stata data una sessione di test al giorno che è stata terminata quando un animale aveva raccolto 60 ricompense o quando erano trascorsi 45 minuti. Ogni turno e ritorno alla fase di base durava per cinque sessioni. Pertanto, i ratti hanno sperimentato un numero totale di 43 sessioni con ritardi variabili. Abbiamo prima addestrato un gruppo di ratti ingenui (n = 8) su questo compito per sondare la capacità di distinguere i veri cambiamenti nell’ambiente dalle fluttuazioni stocastiche dei risultati in condizioni di base nei roditori. Gli animali negli esperimenti sulle lesioni (n = 24: n finto = 8, n lesione BLA = 8, n lesione BLA = 8; n lesione OFC = 8) sono stati testati in condizioni identiche. Ogni animale ha partecipato a un singolo esperimento. Per ogni esperimento, i ratti sono stati assegnati in modo casuale in gruppi.
Analisi dell’espressione delle proteine
Tre gruppi separati di animali sono stati addestrati a rispondere agli stimoli visivi su un touchscreen per ottenere una ricompensa dopo ritardi variabili. I valori dei risultati erano identici al nostro compito descritto sopra, ma non è stata data alcuna scelta. Un gruppo è stato addestrato in condizioni di VL, il secondo in condizioni di VH (pari al numero totale di ricompense ricevute), e il terzo gruppo di controllo non ha ricevuto alcuna ricompensa (n = 8 in ogni gruppo; totale n = 24). Il criterio di formazione è stato fissato a 60 pellet di zucchero per tre giorni consecutivi per imitare la durata dei test di base in animali addestrati sul nostro compito principale. I ratti sono stati eutanasia 1d dopo l’ultimo giorno di esperienza ricompensa con un sovradosaggio di pentobarbital di sodio (250 mg / kg, i.p.) e decapitato. Il cervello è stato immediatamente estratto e due mm di spessore sezioni coronali di OFC ventrale e BLA sono stati ulteriormente sezionato rapidamente, utilizzando una matrice cerebrale, su ghiaccio umido a 4 ° C. Per preparare i tessuti per i saggi 0,2 mL di PBS (0,01 mol / L, pH 7,2) contenente un cocktail di proteasi e inibitore della fosfatasi (aprotinina, bestatina, E-64; leupeptina, NaF, ortovanadato di sodio, pirofosfato di sodio, β-glicerofosfato; EDTA-free; Thermo Scientific, Rockford, IL; Prodotto # 78441) è stato aggiunto ad ogni campione. Ogni tessuto è stato tritato, omogeneizzato, sonicato con un disgregatore cellulare ad ultrasuoni, e centrifugato a 5000 g a 4 ° C per 10 min. Supernatanti sono stati rimossi e conservati a +4 ° C fino a quando i saggi ELISA sono stati eseguiti (entro 24 ore). Bradford proteina saggi sono stati eseguiti anche per determinare le concentrazioni proteiche totali in ogni campione. I saggi sono stati eseguiti secondo le istruzioni del produttore. La sensibilità dei saggi è di 0,1 ng/ml per la gefirina (Cat# MBS9324933) e GluN1 (Cat# MBS724735, MyBioSource, Inc, San Diego, CA) e l’intervallo di rilevamento è di 0,625 ng/ml – 20 ng/ml. La concentrazione di ogni proteina è stata quantificata come ng/mg di proteina totale che tiene conto del fattore di diluizione e presentata come percentuale del gruppo senza ricompensa.
Chirurgia
Lesioni eccitotossiche di BLA (n = 8) e OFC ventrale (n = 8) sono state eseguite utilizzando tecniche stereotassiche asettiche sotto gas isoflurano (1-5% in O2) in anestesia prima del test comportamentale e di formazione. Prima degli interventi chirurgici, tutti gli animali sono stati somministrati 5 mg / kg s.c. carprofen (NADA #141-199, Pfizer, Inc., Codice Etichettatore di farmaci: 000069) e 1cc salina. Dopo essere stato inserito in un apparecchio stereotassico (David Kopf; modello 306041), il cuoio capelluto è stato inciso e retratto. Il cranio è stato poi livellato per garantire che il bregma e il lambda si trovassero sullo stesso piano orizzontale. Nel cranio sono stati praticati piccoli fori di bava per consentire alle cannule con un ago da iniezione di essere abbassate nel BLA (AP: -2,5; ML: ± 5.0; DV: -7,8 (0,1 μl) e -8,1 (0,2 μl) dalla superficie del cranio) o OFC (0,2 μl, AP =+3,7; ML = ±2,0; DV = -4,6). L’ago di iniezione è stato collegato a un tubo di polietilene collegato a una siringa Hamilton montata su una pompa a siringa. N-Metil-D-acido aspartico (NMDA, Sigma-Aldrich; 20 mg/ml in 0,1 m PBS, pH 7,4; Prodotto # M3262) è stato infuso bilateralmente ad una velocità di 0,1 μl/min per distruggere i neuroni intrinseci. Dopo ogni iniezione, l’ago è stato lasciato in posizione per 3-5 min per consentire la diffusione del farmaco. Sham-lesionato gruppo (n = 8) è stato sottoposto a procedure chirurgiche identiche, tranne che non è stato infuso NMDA. Tutti gli animali sono stati dati una settimana di recupero prima della restrizione alimentare e successivi test comportamentali. Durante questa settimana, i ratti sono stati somministrati 5 mg / kg s.c. carprofen (NADA #141-199, Pfizer, Inc., Codice Etichettatrice di farmaci: 000069) e le loro condizioni di salute è stato monitorato ogni giorno.
Istologia
L’entità delle lesioni è stata valutata mediante colorazione per NeuN, un marker per i nuclei neuronali. Dopo la fine della formazione, gli animali sono stati sacrificati da overdose pentobarbital (Euthasol, 0,8 mL, 390 mg/mL pentobarbital, 50 mg/mL fenitoina; Virbic, Fort Worth, TX) e perfusione transcardica. I cervelli sono stati post-fissati in acetato di formalina tamponata al 10% per 24 ore, seguito dal 30% di saccarosio per 5 giorni. Quaranta µm sezioni coronali contenenti l’OFC e BLA sono stati prima incubati per 24 ore a 4 ° C in soluzione contenente l’anticorpo primario NeuN (Anti-NeuN (coniglio), 1:1000, EMD. Millipore, Cat. # ABN78), 10% di siero di capra normale (Abcam, Cambridge, MA, Cat. # ab7481), e 0,5% Triton-X (Sigma, St. Louis, MO, Cat. # T8787) in 1X PBS, seguito da tre lavaggi di 10 minuti in PBS. Il tessuto è stato poi incubato per 4 ore in soluzione contenente 1X PBS, Triton-X e un anticorpo secondario (Capra anti-coniglio IgG (H + L), Alexa Fluor 488 coniugato, 1:400, Fisher Scientific, catalogo # A-11034), seguito da tre lavaggi di 10 minuti in PBS. I vetrini sono stati successivamente montati e coperti, visualizzati con un microscopio BZ-X710 (Keyence, Itasca, IL) e analizzati con il software BZ-X Viewer. Le lesioni sono state determinate per confronto con un atlante cerebrale standard per ratti(Paxinos e Watson, 1997).
Analisi computazionali
Adattiamo diverse versioni di modelli di apprendimento di rinforzo a scelte di prova per ogni animale separatamente. In particolare, abbiamo considerato il modello standard Rescorla-Wagner (RW) e un modello di apprendimento dinamico (Pearce-Hall, PH). Le prove di tutte le sessioni sono state trattate come contigue. I valori delle opzioni sono stati aggiornati in risposta a RPE, δ t, ponderato dal tasso di apprendimento, α (vincolato all’intervallo [0 1]). Il valore atteso per ogni opzione è stato aggiornato secondo la regola delta:Qt+1←Qt+α∗∗δt.
La δ t è la differenza tra il risultato corrente Vt e il valore atteso Qt. Dato che il valore di ogni risultato è stato determinato dal ritardo per ricompensa di una grandezza costante, Vt è stato specificato come 1/(1-kD), dove D è la durata del ritardo e k [0, +∞] è un parametro libero che imposta la ripidità della curva di attualizzazione. Nei modelli dinamici dei tassi di apprendimento (PH e PH+incertezza attesa descritta di seguito), α è stato aggiornato in risposta al grado di sorpresa (δ t assoluta) secondo:αt+1←|δt|∗η+(1-η)∗αt.
Abbiamo impostato l’iniziale α per le opzioni HV e LV allo stesso valore, ma abbiamo permesso un aggiornamento indipendente con l’esperienza. Abbiamo anche considerato modelli in cui l’incertezza del risultato atteso viene appresa contemporaneamente al valore e scala l’impatto degli errori di previsione sul valore (RW+incertezza attesa) e sul tasso di apprendimento (modello completo). Gli errori di previsione dell’incertezza sono la differenza tra gli RPE al quadrato attesi e quelli realizzati. Le aspettative di incertezza previste sono successivamente aggiornate secondo la regola delta. Pertanto, nel modello completo:Qt+1←Qt+αt+αt∗δt/ω∗exp(σt′);
dove ω [1, +∞] è un parametro libero che determina la sensibilità individuale all’incertezza attesa.αt+1←η∗|δt|/ω∗exp(σt′)+(1-η)∗αt.αt+1′←σt′+αrischio∗δrischio,t;δrischio,t=δt2-δt′
La probabilità di scelta dell’opzione per ogni studio è stata determinata secondo una regola di softmax con un parametro di temperatura inversa β; ∝ exp(β*Qt).
I parametri del modello sono stati stimati per massimizzare la probabilità di ottenere il vettore di scelta osservato dato il modello e i suoi parametri (minimizzando la probabilità di log negativo calcolata sulla base della differenza tra la probabilità di scelta prevista e la scelta effettiva su ogni prova utilizzando fmincon in MatLab). Abbiamo usato il criterio di informazione bayesiano (BIC) invece di AIC come misura più conservativa per determinare il modello migliore. Il numero totale di parametri liberi, BIC e i valori dei parametri per ogni modello e gruppo sperimentale sono forniti nella Tabella 1.
Analisi comportamentali e statistiche
Per le analisi statistiche sono stati utilizzati i pacchetti software SPSS (SAS Institute, Inc., versione 24) e MatLab (MathWorks, Natick, Massachusetts; versione R2016b). La significatività statistica è stata rilevata quando i valori p erano inferiori a 0,05. Per caratterizzare la struttura dei dati sono stati utilizzati i test di Shapiro Wilk sulla normalità, i test di Levene sull’uguaglianza delle varianze di errore, i test di Box sull’uguaglianza delle matrici di covarianza e i test di Mauchly sulla sfericità.
I dati di espressione delle proteine sono stati analizzati con ANOVA univariata con il gruppo di esperienze di ricompensa (HV, LV, o nessuna ricompensa) come fattore tra i soggetti. I cambiamenti massimi nella scelta di ogni opzione in risposta ai turni sono stati analizzati con ANOVA omnibus con tipo di turno (HV, LV; upshift, downshift) e fase di turno (pre-baseline, shift, post-baseline) come fattori all’interno del soggetto (numero totale di animali, n, in questa analisi = 8). Analisi simili sono state effettuate su dati ottenuti da esperimenti sulle lesioni con un ulteriore fattore tra i soggetti del gruppo sperimentale (finto, BLA vs OFC lesioni; totale n = 24, n = 8 per gruppo). Inoltre, abbiamo sottoposto i dati sessione per sessione durante ogni swift ad un omnibus ANOVA con sessione di test (da 1 a 5) e tipo di turno come all’interno del gruppo e del gruppo sperimentale tra i fattori del soggetto.
Turno di vincita e di perdita
Per valutare se gli animali nei gruppi lesionati hanno adottato una strategia diversa e hanno dimostrato un’alterata sensibilità a risultati sorprendenti, abbiamo esaminato la strategia di risposta win-stay/lose-shift. Il punteggio del win-stay/lose-shift è stato calcolato sulla base di dati prova per prova simili ai rapporti precedenti(Faraut et al., 2016; Imhof et al., 2007; Worthy et al., 2013). L’algoritmo utilizzato per questa analisi ha tenuto traccia di tutti i ritardi subiti prima della prova in corso in condizioni di base per ogni singolo animale. Su ogni prova, abbiamo calcolato la media della distribuzione del ritardo di base sperimentato e abbiamo trovato il valore del ritardo minimo e massimo. Se il valore del ritardo attuale rientrava in questo intervallo (cioè, ritardo minimo precedente ≤ ritardo attuale ≥ ritardo massimo precedente), il risultato è stato classificato come previsto. Se il ritardo di corrente è caduto al di fuori di questa distribuzione (ritardo di corrente ≤ min ritardo precedente o ritardo di corrente ≥ max ritardo precedente), l’esito di questa prova è stato classificato come inatteso ( sorprendente). Le prove in cui il ritardo attuale superava la media della distribuzione del ritardo sperimentata sono state conteggiate come vittorie e i ritardi inferiori alla media sono stati classificati come perdite. Abbiamo contato le decisioni dei ratti come soggiorni quando hanno scelto la stessa opzione nella prova successiva e come turni quando gli animali sono passati all’altra alternativa. Pertanto, ogni prova poteva essere classificata come soggiorno vincente, turno vincente, soggiorno perdente o turno perdente. Le prove win-stay e lose-shift hanno ottenuto un punteggio di 1 e le prove win-shift e lose-shift sono state contate come 0 s. Abbiamo considerato tutte le prove baseline e value-shift; tuttavia, sono state escluse da questa analisi le prove con ritardi pari alla media delle distribuzioni sperimentate in precedenza o le prove seguite da omissioni di scelta. I punteggi win-stay e lose-shift che abbiamo calcolato separatamente per ogni tipo di trial e le loro probabilità (punteggio sommario diviso per il numero di trial) per entrambi i tipi di trial sono stati sottoposti ad ANOVA con strategia come all’interno del soggetto e del gruppo sperimentale come fattori tra i soggetti.
Voci del porto di ricompensa
Per ottenere ulteriori informazioni sulle rappresentazioni dei risultati nei nostri gruppi sperimentali, abbiamo esaminato se le lesioni BLA e le lesioni ventrali OFC hanno alterato la capacità degli animali di formare aspettative sui tempi di consegna dei premi. Su ogni prova durante tutte le condizioni di base, in cui i valori complessivi delle opzioni LV e HV erano equivalenti, sono state registrate le entrate del porto di ricompensa durante il periodo di attesa. Questa analisi ha incluso tutte le prove in condizioni di base iniziali e le linee di base che separano i turni. Poiché la consegna dei premi nel nostro compito è stata segnalata agli animali dall’illuminazione del caricatore e dai suoni emessi dal dosatore e dalla goccia del pellet, i ratti generalmente hanno raccolto i premi immediatamente (tempo di reazione mediano dalla consegna dei premi al consumo = 0,84 s). Poiché il nostro obiettivo era quello di valutare le aspettative di risultato, piuttosto che le reazioni all’erogazione dei premi, abbiamo analizzato solo l’intervallo di tempo che inizia a partire dalla scomparsa degli stimoli visivi a seguito della scelta e termina alla fine del periodo di ritardo (le voci del caricatore dopo l’erogazione del pellet sono state escluse da questa analisi). Il periodo di attesa è stato suddiviso in contenitori da 1 s e tutte le entrate del caricatore sono state registrate in ogni intervallo. Abbiamo poi diviso il numero di inserimenti in ogni cestino per il numero totale di inserimenti per ottenere le probabilità. Questi dati sono stati analizzati con ANOVA multivariata con opzione (LV, HV) e bidone del tempo come gruppo interno e gruppo sperimentale come fattori tra i soggetti. I test di sfericità di Mauchly sono stati utilizzati per confrontare le varianze tra i gruppi.
Quando sono state trovate interazioni significative, sono stati riportati semplici effetti principali post hoc. Dunnett t (a due facce) confronti sono stati applicati quando si valutano le differenze tra i gruppi sperimentali e un singolo gruppo di controllo, mentre la correzione Bonferroni è stata applicata a confronti multipli. Dove le ipotesi di sfericità sono state violate, sono state applicate correzioni del valore p di Greenhouse-Geisser (Epsilon <0,75). I valori medi del gruppo e il SEM associato sono riportati in cifre (i dati individuali sono forniti nei file Source_Data).
References
- Bakhurin KI, Goudar V, Shobe JL, Claar LD, Buonomano DV, Masmanidis SC. Differential encoding of Time by Prefrontal and Striatal Network Dynamics. The Journal of Neuroscience. 2017; 37:854-870. DOI | PubMed
- Bari A, Robbins TW. Inhibition and impulsivity: behavioral and neural basis of response control. Progress in Neurobiology. 2013; 108:44-79. DOI | PubMed
- Behrens TE, Woolrich MW, Walton ME, Rushworth MF. Learning the value of information in an uncertain world. Nature Neuroscience. 2007; 10:1214-1221. DOI | PubMed
- Chan SC, Niv Y, Norman KA. A Probability distribution over latent causes, in the Orbitofrontal Cortex. The Journal of Neuroscience. 2016; 36:7817-7828. DOI | PubMed
- Chang SE, McDannald MA, Wheeler DS, Holland PC. The effects of basolateral amygdala lesions on unblocking. Behavioral Neuroscience. 2012; 126:279-289. DOI | PubMed
- Chen J, Yu S, Fu Y, Li X. Synaptic proteins and receptors defects in autism spectrum disorders. Frontiers in Cellular Neuroscience. 2014; 8DOI | PubMed
- Chhatwal JP, Myers KM, Ressler KJ, Davis M. Regulation of gephyrin and GABAA receptor binding within the amygdala after fear acquisition and extinction. Journal of Neuroscience. 2005; 25:502-506. DOI | PubMed
- Chu HY, Ito W, Li J, Morozov A. Target-specific suppression of GABA release from parvalbumin interneurons in the basolateral amygdala by dopamine. Journal of Neuroscience. 2012; 32:14815-14820. DOI | PubMed
- Cikara M, Gershman SJ. Medial prefrontal cortex updates its Status. Neuron. 2016; 92:937-939. DOI | PubMed
- Conen KE, Padoa-Schioppa C. Neuronal variability in orbitofrontal cortex during economic decisions. Journal of Neurophysiology. 2015; 114:1367-1381. DOI | PubMed
- Courville AC, Daw ND, Touretzky DS. Bayesian theories of conditioning in a changing world. Trends in Cognitive Sciences. 2006; 10:294-300. DOI | PubMed
- Dalley JW, Cardinal RN, Robbins TW. Prefrontal executive and cognitive functions in rodents: neural and neurochemical substrates. Neuroscience & Biobehavioral Reviews. 2004; 28:771-784. DOI | PubMed
- Dalton GL, Wang NY, Phillips AG, Floresco SB. Multifaceted contributions by different regions of the Orbitofrontal and medial prefrontal cortex to Probabilistic reversal Learning. Journal of Neuroscience. 2016; 36:1996-2006. DOI | PubMed
- Dayan P, Kakade S, Montague PR. Learning and selective attention. Nature Neuroscience. 2000; 3 Suppl:1218-1223. DOI | PubMed
- Diederen KM, Schultz W. Scaling prediction errors to reward variability benefits error-driven learning in humans. Journal of Neurophysiology. 2015; 114:1628-1640. DOI | PubMed
- Dolan RJ. The human amygdala and orbital prefrontal cortex in behavioural regulation. Philosophical Transactions of the Royal Society B: Biological Sciences. 2007; 362:787-799. DOI | PubMed
- Elliott R, Deakin B. Role of the orbitofrontal cortex in reinforcement processing and inhibitory control: evidence from functional magnetic resonance imaging studies in healthy human subjects. International Review of Neurobiology. 2005; 65:89-116. DOI | PubMed
- Elliott R, Dolan RJ, Frith CD. Dissociable functions in the medial and lateral orbitofrontal cortex: evidence from human neuroimaging studies. Cerebral Cortex. 2000; 10:308-317. DOI | PubMed
- Emery NJ. Cognitive ornithology: the evolution of avian intelligence. Philosophical Transactions of the Royal Society B: Biological Sciences. 2006; 361:23-43. DOI | PubMed
- Esber GR, Holland PC. The basolateral amygdala is necessary for negative prediction errors to enhance cue salience, but not to produce conditioned inhibition. European Journal of Neuroscience. 2014; 40:3328-3337. DOI | PubMed
- Faraut MC, Procyk E, Wilson CR. Learning to learn about uncertain feedback. Learning & Memory. 2016; 23:90-98. DOI | PubMed
- Fellows LK, Farah MJ. Ventromedial frontal cortex mediates affective shifting in humans: evidence from a reversal learning paradigm. Brain. 2003; 126:1830-1837. DOI | PubMed
- Fellows LK, Farah MJ. The role of ventromedial prefrontal cortex in decision making: judgment under uncertainty or judgment per se?. Cerebral Cortex. 2007; 17:2669-2674. DOI | PubMed
- Freeman KB, Green L, Myerson J, Woolverton WL. Delay discounting of saccharin in rhesus monkeys. Behavioural Processes. 2009; 82:214-218. DOI | PubMed
- Gallistel CR, Mark TA, King AP, Latham PE. The rat approximates an ideal detector of changes in rates of reward: implications for the law of effect. Journal of Experimental Psychology: Animal Behavior Processes. 2001; 27:354-372. DOI | PubMed
- Gershman SJ, Niv Y. Learning latent structure: carving nature at its joints. Current Opinion in Neurobiology. 2010; 20:251-256. DOI | PubMed
- Ghods-Sharifi S, St Onge JR, Floresco SB. Fundamental contribution by the basolateral amygdala to different forms of decision making. Journal of Neuroscience. 2009; 29:5251-5259. DOI | PubMed
- Green L, Myerson J, Oliveira L, Chang SE. Delay discounting of monetary rewards over a wide range of amounts. Journal of the Experimental Analysis of Behavior. 2013; 100:269-281. DOI | PubMed
- Hart EE, Izquierdo A. Basolateral amygdala supports the maintenance of value and effortful choice of a preferred option. European Journal of Neuroscience. 2017; 45:388-397. DOI | PubMed
- Haruno M, Kimura M, Frith CD. Activity in the nucleus accumbens and amygdala underlies individual differences in prosocial and individualistic economic choices. Journal of Cognitive Neuroscience. 2014; 26:1861-1870. DOI | PubMed
- Hoshino O. Balanced crossmodal excitation and inhibition essential for maximizing multisensory gain. Neural Computation. 2014; 26:1362-1385. DOI | PubMed
- Hsu M, Bhatt M, Adolphs R, Tranel D, Camerer CF. Neural systems responding to degrees of uncertainty in human decision-making. Science. 2005; 310:1680-1683. DOI | PubMed
- Hwang J, Kim S, Lee D. Temporal discounting and inter-temporal choice in rhesus monkeys. Frontiers in Behavioral Neuroscience. 2009; 3DOI | PubMed
- Imhof LA, Fudenberg D, Nowak MA. Tit-for-tat or win-stay, lose-shift?. Journal of Theoretical Biology. 2007; 247:574-580. DOI | PubMed
- Izquierdo A, Brigman JL, Radke AK, Rudebeck PH, Holmes A. The neural basis of reversal learning: An updated perspective. Neuroscience. 2017; 345:12-26. DOI | PubMed
- Izquierdo A, Murray EA. Functional interaction of medial mediodorsal thalamic nucleus but not nucleus accumbens with amygdala and orbital prefrontal cortex is essential for adaptive response selection after reinforcer devaluation. Journal of Neuroscience. 2010; 30:661-669. DOI | PubMed
- Izquierdo A, Suda RK, Murray EA. Bilateral orbital prefrontal cortex lesions in rhesus monkeys disrupt choices guided by both reward value and reward contingency. Journal of Neuroscience. 2004; 24:7540-7548. DOI | PubMed
- Khamassi M, Lallée S, Enel P, Procyk E, Dominey PF. Robot cognitive control with a neurophysiologically inspired reinforcement learning model. Frontiers in Neurorobotics. 2011; 5DOI | PubMed
- Lee D, Seo H, Jung MW. Neural basis of reinforcement learning and decision making. Annual Review of Neuroscience. 2012; 35:287-308. DOI | PubMed
- Li J, Schiller D, Schoenbaum G, Phelps EA, Daw ND. Differential roles of human striatum and amygdala in associative learning. Nature Neuroscience. 2011; 14:1250-1252. DOI | PubMed
- Li Y, Vanni-Mercier G, Isnard J, Mauguière F, Dreher JC. The neural dynamics of reward value and risk coding in the human orbitofrontal cortex. Brain. 2016; 139:1295-1309. DOI | PubMed
- Liguz-Lecznar M, Lehner M, Kaliszewska A, Zakrzewska R, Sobolewska A, Kossut M. Altered glutamate/GABA equilibrium in aged mice cortex influences cortical plasticity. Brain Structure and Function. 2015; 220:1681-1693. DOI | PubMed
- Lionel AC, Vaags AK, Sato D, Gazzellone MJ, Mitchell EB, Chen HY, Costain G, Walker S, Egger G, Thiruvahindrapuram B, Merico D, Prasad A, Anagnostou E, Fombonne E, Zwaigenbaum L, Roberts W, Szatmari P, Fernandez BA, Georgieva L, Brzustowicz LM, Roetzer K, Kaschnitz W, Vincent JB, Windpassinger C, Marshall CR, Trifiletti RR, Kirmani S, Kirov G, Petek E, Hodge JC, Bassett AS, Scherer SW. Rare exonic deletions implicate the synaptic organizer gephyrin (GPHN) in risk for autism, schizophrenia and seizures. Human Molecular Genetics. 2013; 22:2055-2066. DOI | PubMed
- Lopatina N, Sadacca BF, McDannald MA, Styer CV, Peterson JF, Cheer JF, Schoenbaum G. Ensembles in medial and lateral orbitofrontal cortex construct cognitive maps emphasizing different features of the behavioral landscape. Behavioral Neuroscience. 2017; 131:201-212. DOI | PubMed
- Marquardt K, Sigdel R, Brigman JL. Touch-screen visual reversal learning is mediated by value encoding and signal propagation in the orbitofrontal cortex. Neurobiology of Learning and Memory. 2017; 139:179-188. DOI | PubMed
- Mazur JE, Biondi DR. Delay-amount tradeoffs in choices by pigeons and rats: hyperbolic versus exponential discounting. Journal of the Experimental Analysis of Behavior. 2009; 91:197-211. DOI | PubMed
- McDannald MA, Lucantonio F, Burke KA, Niv Y, Schoenbaum G. Ventral striatum and orbitofrontal cortex are both required for model-based, but not model-free, reinforcement learning. Journal of Neuroscience. 2011; 31:2700-2705. DOI | PubMed
- McDannald MA, Saddoris MP, Gallagher M, Holland PC. Lesions of orbitofrontal cortex impair rats’ differential outcome expectancy learning but not conditioned stimulus-potentiated feeding. Journal of Neuroscience. 2005; 25:4626-4632. DOI | PubMed
- Merlo E, Ratano P, Ilioi EC, Robbins MA, Everitt BJ, Milton AL. Amygdala dopamine receptors are required for the destabilization of a reconsolidating appetitive memory(1,2). eNeuro. 2015; 2DOI | PubMed
- Mitchell SH, Wilson VB, Karalunas SL. Comparing hyperbolic, delay-amount sensitivity and present-bias models of delay discounting. Behavioural Processes. 2015; 114:52-62. DOI | PubMed
- Morris LS, Kundu P, Dowell N, Mechelmans DJ, Favre P, Irvine MA, Robbins TW, Daw N, Bullmore ET, Harrison NA, Voon V. Fronto-striatal organization: defining functional and microstructural substrates of behavioural flexibility. Cortex. 2016; 74:118-133. DOI | PubMed
- Motanis H, Maroun M, Barkai E. Learning-induced bidirectional plasticity of intrinsic neuronal excitability reflects the valence of the outcome. Cerebral Cortex. 2014; 24:1075-1087. DOI | PubMed
- Murray EA, Izquierdo A. Orbitofrontal cortex and amygdala contributions to affect and action in primates. Annals of the New York Academy of Sciences. 2007; 1121:273-296. DOI | PubMed
- Nassar MR, Wilson RC, Heasly B, Gold JI. An approximately bayesian delta-rule model explains the dynamics of belief updating in a changing environment. Journal of Neuroscience. 2010; 30:12366-12378. DOI | PubMed
- Niv Y, Daniel R, Geana A, Gershman SJ, Leong YC, Radulescu A, Wilson RC. Reinforcement learning in multidimensional environments relies on attention mechanisms. Journal of Neuroscience. 2015; 35:8145-8157. DOI | PubMed
- Ostrander S, Cazares VA, Kim C, Cheung S, Gonzalez I, Izquierdo A. Orbitofrontal cortex and basolateral amygdala lesions result in suboptimal and dissociable reward choices on cue-guided effort in rats. Behavioral Neuroscience. 2011; 125:350-359. DOI | PubMed
- Padoa-Schioppa C, Schoenbaum G. Dialogue on economic choice, learning theory, and neuronal representations. Current Opinion in Behavioral Sciences. 2015; 5:16-23. DOI | PubMed
- Padoa-Schioppa C. Orbitofrontal cortex and the computation of economic value. Annals of the New York Academy of Sciences. 2007; 1121:232-253. DOI | PubMed
- Padoa-Schioppa C. Range-adapting representation of economic value in the orbitofrontal cortex. Journal of Neuroscience. 2009; 29:14004-14014. DOI | PubMed
- Paton JJ, Belova MA, Morrison SE, Salzman CD. The primate amygdala represents the positive and negative value of visual stimuli during learning. Nature. 2006; 439:865-870. DOI | PubMed
- Paxinos G, Watson C. The Rat Brainin Stereotaxic Coordinates. Academic Press: Cambridge; 1997.
- Payzan-LeNestour E, Bossaerts P. Risk, unexpected uncertainty, and estimation uncertainty: bayesian learning in unstable settings. PLoS Computational Biology. 2011; 7DOI | PubMed
- Pearce JM, Hall G. A model for pavlovian learning: variations in the effectiveness of conditioned but not of unconditioned stimuli. Psychological Review. 1980; 87:532-552. DOI | PubMed
- Pearson JM, Platt ML. Change detection, multiple controllers, and dynamic environments: insights from the brain. Journal of the Experimental Analysis of Behavior. 2013; 99:74-84. DOI | PubMed
- Potts R. Paleoenvironmental basis of cognitive evolution in great apes. American Journal of Primatology. 2004; 62:209-228. DOI | PubMed
- Preuschoff K, Bossaerts P. Adding prediction risk to the theory of reward learning. Annals of the New York Academy of Sciences. 2007; 1104:135-146. DOI | PubMed
- Rachlin H, Raineri A, Cross D. Subjective probability and delay. Journal of the Experimental Analysis of Behavior. 1991; 55:233-244. DOI | PubMed
- Ramirez DR, Savage LM. Differential involvement of the basolateral amygdala, orbitofrontal cortex, and nucleus accumbens core in the acquisition and use of reward expectancies. Behavioral Neuroscience. 2007; 121:896-906. DOI | PubMed
- Riceberg JS, Shapiro ML. Reward stability determines the contribution of orbitofrontal cortex to adaptive behavior. Journal of Neuroscience. 2012; 32:16402-16409. DOI | PubMed
- Riceberg JS, Shapiro ML. Orbitofrontal Cortex signals expected outcomes with predictive codes when stable contingencies promote the integration of reward history. The Journal of Neuroscience. 2017; 37:2010-2021. DOI | PubMed
- Roesch MR, Calu DJ, Esber GR, Schoenbaum G. Neural correlates of variations in event processing during learning in basolateral amygdala. Journal of Neuroscience. 2010; 30:2464-2471. DOI | PubMed
- Rössert C, Moore LE, Straka H, Glasauer S. Cellular and network contributions to vestibular signal processing: impact of ion conductances, synaptic inhibition, and noise. Journal of Neuroscience. 2011; 31:8359-8372. DOI | PubMed
- Rudebeck PH, Murray EA. The orbitofrontal oracle: cortical mechanisms for the prediction and evaluation of specific behavioral outcomes. Neuron. 2014; 84:1143-1156. DOI | PubMed
- Salinas JA, Parent MB, McGaugh JL. Ibotenic acid lesions of the amygdala basolateral complex or central nucleus differentially effect the response to reductions in reward. Brain Research. 1996; 742:283-293. DOI | PubMed
- Salzman CD, Paton JJ, Belova MA, Morrison SE. Flexible neural representations of value in the primate brain. Annals of the New York Academy of Sciences. 2007; 1121:336-354. DOI | PubMed
- Savage LM, Koch AD, Ramirez DR. Basolateral amygdala inactivation by muscimol, but not ERK/MAPK inhibition, impairs the use of reward expectancies during working memory. European Journal of Neuroscience. 2007; 26:3645-3651. DOI | PubMed
- Schoenbaum G, Roesch MR, Stalnaker TA, Takahashi YK. Neurobiology of Sensation and Reward. CRC Press/Taylor & Francis: Boca Raton; 2011a.
- Schoenbaum G, Takahashi Y, Liu TL, McDannald MA. Does the orbitofrontal cortex signal value?. Annals of the New York Academy of Sciences. 2011b; 1239:87-99. DOI | PubMed
- Schuck NW, Cai MB, Wilson RC, Niv Y. Human Orbitofrontal Cortex represents a cognitive map of State Space. Neuron. 2016; 91:1402-1412. DOI | PubMed
- Soares C, Lee KF, Nassrallah W, Béïque JC. Differential subcellular targeting of glutamate receptor subtypes during homeostatic synaptic plasticity. Journal of Neuroscience. 2013; 33:13547-13559. DOI | PubMed
- Stalnaker TA, Cooch NK, Schoenbaum G. What the orbitofrontal cortex does not do. Nature Neuroscience. 2015; 18:620-627. DOI | PubMed
- Steppan SJ, Storz BL, Hoffmann RS. Nuclear DNA phylogeny of the squirrels (Mammalia: rodentia) and the evolution of arboreality from c-myc and RAG1. Molecular Phylogenetics and Evolution. 2004; 30:703-719. DOI | PubMed
- Stopper CM, Green EB, Floresco SB. Selective involvement by the medial orbitofrontal cortex in biasing risky, but not impulsive, choice. Cerebral Cortex. 2014; 24:154-162. DOI | PubMed
- Sugrue LP, Corrado GS, Newsome WT. Choosing the greater of two goods: neural currencies for valuation and decision making. Nature Reviews Neuroscience. 2005; 6:363-375. DOI | PubMed
- Tyagarajan SK, Ghosh H, Yévenes GE, Nikonenko I, Ebeling C, Schwerdel C, Sidler C, Zeilhofer HU, Gerrits B, Muller D, Fritschy JM. Regulation of GABAergic synapse formation and plasticity by GSK3beta-dependent phosphorylation of gephyrin. PNAS. 2011; 108:379-384. DOI | PubMed
- van Duuren E, van der Plasse G, Lankelma J, Joosten RN, Feenstra MG, Pennartz CM. Single-cell and population coding of expected reward probability in the orbitofrontal cortex of the rat. Journal of Neuroscience. 2009; 29:8965-8976. DOI | PubMed
- Walton ME, Behrens TE, Buckley MJ, Rudebeck PH, Rushworth MF. Separable learning systems in the macaque brain and the role of orbitofrontal cortex in contingent learning. Neuron. 2010; 65:927-939. DOI | PubMed
- Walton ME, Behrens TE, Noonan MP, Rushworth MF. Giving credit where credit is due: orbitofrontal cortex and valuation in an uncertain world. Annals of the New York Academy of Sciences. 2011; 1239:14-24. DOI | PubMed
- Wassum KM, Izquierdo A. The basolateral amygdala in reward learning and addiction. Neuroscience & Biobehavioral Reviews. 2015; 57:271-283. DOI | PubMed
- Wilson RC, Takahashi YK, Schoenbaum G, Niv Y. Orbitofrontal cortex as a cognitive map of task space. Neuron. 2014; 81:267-279. DOI | PubMed
- Winstanley CA, Clark L. Translational models of Gambling-Related Decision-Making. Current Topics in Behavioral Neurosciences. 2016a; 28:93-120. DOI | PubMed
- Winstanley CA, Floresco SB. Deciphering decision making: variation in Animal models of effort- and Uncertainty-Based choice reveals distinct neural circuitries underlying Core Cognitive Processes. Journal of Neuroscience. 2016b; 36:12069-12079. DOI | PubMed
- Winstanley CA. The orbitofrontal cortex, impulsivity, and addiction: probing orbitofrontal dysfunction at the neural, neurochemical, and molecular level. Annals of the New York Academy of Sciences. 2007; 1121:639-655. DOI | PubMed
- Wolff SB, Gründemann J, Tovote P, Krabbe S, Jacobson GA, Müller C, Herry C, Ehrlich I, Friedrich RW, Letzkus JJ, Lüthi A. Amygdala interneuron subtypes control fear learning through disinhibition. Nature. 2014; 509:453-458. DOI | PubMed
- Worthy DA, Hawthorne MJ, Otto AR. Heterogeneity of strategy use in the Iowa gambling task: a comparison of win-stay/lose-shift and reinforcement learning models. Psychonomic Bulletin & Review. 2013; 20:364-371. DOI | PubMed
- Yates JR, Batten SR, Bardo MT, Beckmann JS. Role of ionotropic glutamate receptors in delay and probability discounting in the rat. Psychopharmacology. 2015; 232:1187-1196. DOI | PubMed
- Yu AJ, Dayan P. Uncertainty, neuromodulation, and attention. Neuron. 2005; 46:681-692. DOI | PubMed
- Zeeb FD, Winstanley CA. Lesions of the basolateral amygdala and orbitofrontal cortex differentially affect acquisition and performance of a rodent gambling task. Journal of Neuroscience. 2011; 31:2197-2204. DOI | PubMed
Fonte
Stolyarova A, Izquierdo A, Schoenbaum G () Complementary contributions of basolateral amygdala and orbitofrontal cortex to value learning under uncertainty. eLife 6e27483. https://doi.org/10.7554/eLife.27483




