
Introduzione
La ricerca verso la fine del XX secolo ha mostrato l’incidenza degli eventi avversi e dei decessi non necessari nei pazienti ospedalieri. 1234 I punteggi di allarme precoce (EWS) sono stati proposti come potenziale soluzione. 5 Questi strumenti sono modelli di previsione clinica che generalmente utilizzano i segni vitali misurati per monitorare la salute dei pazienti durante la loro degenza ospedaliera. I modelli identificano la probabilità di deterioramento dei pazienti, spesso definita come morte o ricovero in terapia intensiva. Quando un paziente mostra segni di deterioramento, l’EWS fa scattare un allarme in modo che le cure possano essere intensificate. Storicamente gli EWS sono stati implementati su carte di osservazione cartacee, ma ora stanno diventando sempre più parte dei sistemi di cartelle cliniche elettroniche.
Gli EWS basati sui segni vitali sono ampiamente utilizzati ogni giorno negli ospedali per identificare i pazienti che si stanno deteriorando clinicamente. Queste misure sono usate abitualmente in diversi paesi, tra cui i Paesi Bassi, gli Stati Uniti, l’Australia e la Repubblica d’Irlanda. 6789 Negli ospedali del Regno Unito l’uso del SAR è imposto come standard di cura dal National Institute for Health and Care Excellence. 10 Poiché i pazienti ricoverati negli ospedali vengono solitamente valutati ogni poche ore utilizzando un EWS, questi punteggi vengono utilizzati centinaia di milioni di volte all’anno. 11 Sono state anche presentate richieste per aumentare l’uso dell’EWS nei servizi di ambulanza, nell’assistenza primaria e nelle case di cura della comunità. 12
13
14
15
16
Gli articoli che descrivono lo sviluppo di modelli di previsione clinica abbondano in molti settori della medicina. 1718 Le revisioni sistematiche hanno dimostrato che i metodi utilizzati in questi articoli sono spesso scadenti. 19202122 Sebbene molti modelli di predizione pubblicati non siano messi in pratica, gli EWS sono ampiamente utilizzati, probabilmente più di qualsiasi altro tipo di modello di predizione clinica. Nonostante l’ampio sviluppo e la crescente diffusione, nell’ultimo decennio sono mancate revisioni complete degli articoli sugli EWS. Sono necessarie revisioni sistematiche che valutino la qualità metodologica e di reporting dei documenti che descrivono lo sviluppo e la validazione degli EWS. Gli studi di validazione esterni, che sono vitali per valutare la generalizzabilità dei SAR, devono essere valutati sistematicamente. Le revisioni sistematiche esistenti dei SAR si sono concentrate per lo più sulle prestazioni predittive, ma hanno accennato a difetti metodologici. 23
24
I pazienti ospedalieri avranno probabilmente i loro segni vitali e altri parametri misurati più volte durante la loro permanenza in ospedale, quindi i set di dati disponibili potrebbero includere misurazioni multiple (o set di osservazione) per ogni paziente. Il modo più appropriato per analizzare tali dati non è chiaro, il che aumenta la complessità della ricerca EWS rispetto ad altre aree di modellizzazione delle previsioni cliniche. 2526 Esiste anche un dibattito sulla migliore scelta della misura di esito e dell’orizzonte temporale; per esempio, il decesso o il ricovero in terapia intensiva entro un periodo di tempo specifico (per esempio, 24 ore) o l’intera degenza ospedaliera. 27 Approcci diversi a questi problemi potrebbero dare risultati diversi quando si sviluppano e si convalidano le SGA, e potrebbero portare all’utilizzo di modelli che non funzionano.
Il grande potenziale dell’EWS di assistere nel processo decisionale clinico potrebbe essere vanificato da metodi scadenti e da un’inadeguata reportistica. L’uso diffuso delle EWS significa che le EWS poco sviluppate e segnalate potrebbero avere un effetto altamente dannoso sull’assistenza ai pazienti. Abbiamo effettuato una revisione sistematica per valutare i metodi e la segnalazione degli studi che hanno sviluppato o convalidato esternamente le EWS per i pazienti adulti in generale.
Metodi
I dettagli del disegno dello studio e delle motivazioni sono stati pubblicati in precedenza. 11 In sintesi, abbiamo individuato articoli che descrivono lo sviluppo o la convalida dei SAR. I database Medline (Ovidio), CINAHL (EBSCOHost), PsycInfo (Ovidio) e Embase (Ovidio) sono stati oggetto di ricerca dall’inizio al 30 agosto 2017. Il 19 giugno 2019 è stata condotta una ricerca di aggiornamento per identificare gli articoli pubblicati dalla data della ricerca originale. Le strategie di ricerca sono state sviluppate da uno specialista dell’informazione (SK) per ogni banca dati e sono riportate nell’appendice supplementare. I termini di ricerca comprendevano termini rilevanti del vocabolario controllato (ad es. MeSH, EMTREE) e variazioni di testo libero per i punteggi o i sistemi di allerta precoce o di monitoraggio e trigger (compresi gli acronimi comuni), il monitoraggio fisiologico o gli indicatori dello stato di salute, combinati con i termini di sviluppo e di convalida. Non abbiamo applicato alcuna restrizione di data o di lingua alla ricerca. Ulteriori articoli sono stati trovati cercando i riferimenti nei documenti identificati dalla strategia di ricerca, le nostre liste di riferimento personali e una ricerca Google Scholar.
Criteri di ammissibilità
Abbiamo incluso tutti gli articoli di ricerca primaria che descrivevano lo sviluppo o la convalida di uno o più EWS, definiti come un punteggio (con almeno due predittori) utilizzato per identificare i pazienti generici ricoverati in ospedale che sono a rischio di deterioramento clinico. Gli studi di validazione esterni sono stati inclusi solo se era disponibile anche un articolo che descriveva lo sviluppo di quell’EWS.
Gli articoli non erano ammissibili se il punteggio era stato sviluppato per l’uso in un sottoinsieme di pazienti con una specifica malattia o gruppo di malattie, per l’uso nei bambini (<16 anni), o nelle donne in gravidanza; quando il punteggio è destinato ad essere usato per i pazienti ambulatoriali o per i pazienti in terapia intensiva; quando non sono stati inclusi segni vitali nel modello finale; o quando l’articolo era una recensione, lettera, corrispondenza personale o abstract, o l’articolo è stato pubblicato in una lingua non inglese.
Selezione dello studio ed estrazione dei dati
Un autore (SG) ha vagliato i titoli e gli abstract di tutti gli articoli identificati dalla stringa di ricerca. Due revisori (di SG, PSV e JB) hanno estratto i dati in modo indipendente utilizzando un modulo di estrazione dati standardizzato e pilotato. I conflitti sono stati risolti con una discussione tra i due revisori. Il modulo è stato amministrato utilizzando il REDCap (research electronic data capture), lo strumento elettronico per l’acquisizione dei dati. 28 Gli elementi per l’estrazione si basavano sulla checklist CHARMS (valutazione critica ed estrazione dei dati per la revisione sistematica degli studi di modellizzazione predittiva)29 , integrata da domande specifiche per argomento e da una guida metodologica. Questi elementi comprendevano le caratteristiche di progettazione dello studio, le caratteristiche del paziente, le dimensioni del campione, i risultati, i metodi di analisi statistica e i metodi di prestazione del modello.
Tra gli elementi estratti da studi che descrivono lo sviluppo dei sistemi di allarme elettromagnetico vi sono i seguenti (per una spiegazione di alcuni termini tecnici, si veda il riquadro 1): progettazione dello studio (retrospettiva, prospettica), dettagli della popolazione (ad esempio, quando e dove sono stati raccolti i dati, età, sesso), metodo di sviluppo (ad esempio, consenso clinico, approccio statistico), esito previsto e orizzonte temporale, numero e tipo di predittori, dimensione del campione, numero di eventi, approccio dei dati mancanti, approccio modellistico (ad esempio, tipo di modello di regressione, metodo utilizzato per selezionare le variabili, gestione delle variabili continue, esame dei termini di interazione), presentazione del modello (ad esempio, segnalazione dei coefficienti del modello, intercettazione o rischio di base, modello semplificato), metodo di validazione interna (ad esempio, campione diviso, bootstrapping, validazione incrociata), e valutazione delle prestazioni del modello (ad esempio, discriminazione, calibrazione). Gli elementi estratti dagli studi che descrivono la validazione esterna dei sistemi EWS comprendono il disegno dello studio (retrospettivo, prospettico), i dettagli della popolazione (ad esempio, quando e dove sono stati raccolti i dati, età, sesso), l’esito previsto e l’orizzonte temporale, la dimensione del campione, il numero di eventi, l’approccio ai dati mancanti e la valutazione delle prestazioni del modello (ad esempio, discriminazione, calibrazione). Definiamo i pazienti dell’evento come il numero di pazienti registrati come aventi l’esito di interesse (ad esempio, che muoiono o che vengono ricoverati in terapia intensiva in qualsiasi momento durante la loro permanenza in ospedale). Le osservazioni di eventi si riferiscono al numero di gruppi di osservazione che si trovano in un periodo definito prima che l’esito si verifichi.
Valutazione del pregiudizio
Abbiamo valutato il rischio di bias per ogni articolo utilizzando PROBAST (strumento di valutazione del rischio di bias del modello di previsione), sviluppato dal Cochrane Prognosis Methods Group. 30 PROBAST consiste in 23 domande di segnalazione all’interno di quattro domini (selezione dei partecipanti, predittori, risultati e analisi). Gli articoli sono stati classificati come a basso, alto o poco chiaro rischio di bias per ogni dominio. Uno studio è stato classificato come a basso rischio di distorsione solo se era a basso rischio di distorsione all’interno di ogni dominio.
Sintesi delle prove
Abbiamo riassunto i risultati utilizzando statistiche descrittive, trame grafiche e una sintesi narrativa. Non abbiamo effettuato una sintesi quantitativa dei modelli perché questo non era l’obiettivo principale della revisione e gli studi erano troppo eterogenei per essere combinati.
Coinvolgimento del paziente e del pubblico
I pazienti e il pubblico sono stati coinvolti nell’impostazione della domanda di ricerca e nello sviluppo dello studio, attraverso incontri faccia a faccia e revisioni del protocollo. I pazienti e il pubblico hanno letto e rivisto il manoscritto. Non ci sono piani per diffondere i risultati della ricerca ai pazienti o al pubblico.
Risultati
La strategia di ricerca ha individuato 13 171 articoli unici, di cui 12 794 sono stati esclusi in base al titolo e alla selezione astratta. Abbiamo vagliato 377 testi completi, 93 dei quali rispondevano ai criteri di ammissibilità e sono stati inclusi nella revisione (fig. 1). Abbiamo identificato altri due articoli ricercando i riferimenti degli articoli, che sono stati inclusi, per un totale di 95 articoli. Undici articoli hanno descritto lo sviluppo di soli SAR, 23 hanno descritto lo sviluppo e la convalida esterna e 61 hanno descritto solo la convalida esterna. Gli articoli sono stati pubblicati tra il 2001 e il 2019 su 51 riviste. Una rivista, Resuscitation, ha pubblicato 21 degli articoli. Nessun’altra rivista ha incluso più di quattro degli articoli. Novantatre articoli hanno utilizzato un set di dati dei pazienti (due hanno utilizzato solo il consenso clinico), la maggior parte dei quali ha utilizzato dati provenienti dal Regno Unito (n=28) o dagli Stati Uniti (n=25). Gli articoli rappresentavano dati provenienti da 22 paesi di quattro continenti.
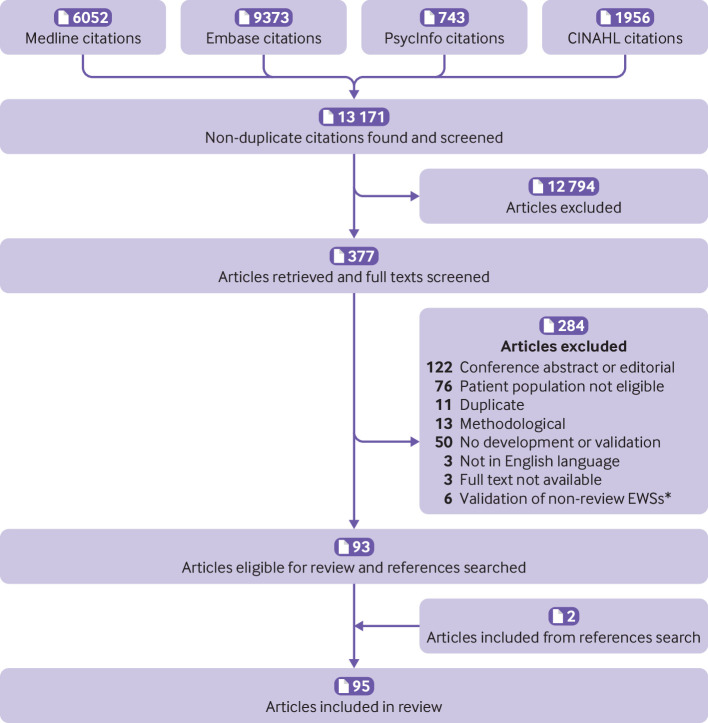
Fig. 1.Diagramma di flusso della selezione dell’articolo. *La convalida degli EWS non revisionati (punteggi di allarme rapido) si riferisce a studi esterni, che sono esclusi perché il corrispondente documento di sviluppo non era ammissibile o perché non è stato pubblicato alcun documento di sviluppo.
Fig. 1.Diagramma di flusso della selezione dell’articolo. *La convalida degli EWS non revisionati (punteggi di allarme rapido) si riferisce a studi esterni, che sono esclusi perché il corrispondente documento di sviluppo non era ammissibile o perché non è stato pubblicato alcun documento di sviluppo.
Studi che descrivono lo sviluppo dei SAR
Studio di progettazione
Dei 34 articoli che descrivono lo sviluppo di un nuovo SAR, 29 si basavano su metodi statistici, ovvero utilizzavano una qualche forma di approccio basato sui dati per creare il modello. Tre studi hanno sviluppato modelli basati sul consenso clinico, dove un gruppo di esperti ha scelto le variabili e i pesi associati che avrebbero costituito il modello. Due studi hanno sviluppato modelli modificando un punteggio esistente, sia modificando i pesi delle variabili, sia aggiungendo variabili binarie, per migliorare le prestazioni predittive (tabella 1), ma non è stato riportato il motivo per modificare un punteggio esistente.
| Riferimento | EWS | Tipo di sviluppo | Tipo di dati | Paese | Anni di dati | Età media o mediana | Maschio (%) |
|---|---|---|---|---|---|---|---|
| Albert 201131 | — | Sulla base del consenso clinico | NA | US | NA | NA | NA |
| Alvarez 201332 | — | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2009-10 | 51 | 56 |
| Badriyah 201433 | PASTI | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | REGNO UNITO | 2006-08 | 68 | 47 |
| Bleyer 201134 | Trio di segni vitali critici | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2009 | 57 | 51 |
| Churpek 20128 | CARRELLO | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2008-11 | 54 | 43 |
| Churpek 201435 | — | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2008-11 | 54 | 43 |
| Churpek 201436 | eCART | Utilizzo di metodi statistici (basati su dati) | Coorte/base dati retrospettiva | US | 2008-13 | 60 | 40 |
| Churpek 201637 | — | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2008-13 | 60 | 40 |
| Cuthbertson 201038 | — | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | REGNO UNITO | 2005 | 65 | 51 |
| Douw 20169 | DENWIS | Modifica del punteggio esistente | NA | Paesi Bassi | NA | NA | NA |
| Duckitt 200739 | Worthing PSS | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | REGNO UNITO | 2003-05 | 73 | 52 |
| Dziadzko 201840 | APPROVA | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2013 | 58 | 41 |
| Escobar 201241 | Modello basato su EMR | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2006-09 | 65 | 45 |
| Faisal 201842 | CARM | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | REGNO UNITO | 2014-15 | 67 | 50 |
| Ghosh 201843 | EDI | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2012-13 | 59 | Manca |
| Goldhill 200444 | — | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | REGNO UNITO | 2002 | 61 | Manca |
| Harrison 200645 | GMEWS | Modifica del punteggio esistente | NA | Australia | NA | NA | NA |
| Jones 201246 | NOTIZIE | Sulla base del consenso clinico | NA | REGNO UNITO | NA | NA | NA |
| Kellett 200647 | SCS | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Irlanda | 2000-04 | 62 | 52 |
| Kellett 200848 | HOTEL | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Irlanda | 2000-04 | 62 | 53 |
| Kipnis 201649 | AAM | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | US | 2010-13 | 65 | 46 |
| Kirkland 201350 | — | Utilizzo di metodi statistici (basati su dati) | Altro | US | 2008-09 | 72 | 62 |
| Kwon 201851 | DEWS | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Corea del Sud | 2010-17 | 57 | 52 |
| Kyriacos 201452 | MEWS* | Sulla base del consenso clinico | NA | Sudafrica | NA | NA | NA |
| Luis 201853 | Brevi notizie | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Portogallo | 2012 | Manca | 48 |
| Moore 201754 | UVA | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Gabon, Malawi, Sierra Leone, Tanzania, Uganda e Zambia | 2009-15 | 36 | 49 |
| Nichel 201655 | NOTIZIE e D-dimero | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Danimarca | 2008-11 | 62 | 45 |
| Perera 201156 | MEWS più biochimico | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | Sri Lanka | 2009 | 49 | 48 |
| Prytherch 201057 | ViEWS | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | REGNO UNITO | 2006-08 | 68 | 48 |
| Redfern 201858 | LDTEWS:NOTIZIE | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | REGNO UNITO | 2011-16 | 73 | 49 |
| Silke 201059 | MARS | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | Irlanda | 2002-07 | 50 | 48 |
| Tarassenko 201160 | CEWS | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | Regno Unito e Stati Uniti | 2004-08 | 60 | 57 |
| Watkinson 201861 | mCEWS | Utilizzo di metodi statistici (basati su dati) | Coorte retrospettiva/base dati | REGNO UNITO | 2014-15 | 63 | 51 |
| Wheeler 201362 | TOTALE | Utilizzo di metodi statistici (basati su dati) | Coorte prospettica | Malawi | 2012 | 40 | 51 |
La maggior parte dei 29 studi sviluppati con metodi statistici ha utilizzato dati di coorti retrospettive (n=21, 72%), mentre 7 (24%) hanno utilizzato dati di coorti raccolte in modo prospettico. I dati utilizzati per sviluppare i modelli sono stati raccolti tra il 2000 e il 2017. Dodici dei 29 studi (41%) non hanno descritto adeguatamente il loro dataset, mancando almeno una delle seguenti caratteristiche: età media, distribuzione di uomini e donne, numero di pazienti con e senza l’evento, e numero di set di osservazione con e senza l’evento (un paziente potrebbe contribuire con più di un set di osservazioni).
Ventitré dei 29 studi (79%) hanno utilizzato un approccio di modellazione predittiva (compresi i metodi di modellazione di regressione e di apprendimento automatico). Gli altri sei studi hanno utilizzato una varietà di metodi. La tabella C dell’appendice fornisce ulteriori dettagli.
Misure di risultato e orizzonti temporali
Abbiamo osservato una serie di misure primarie di risultato nei 23 studi di sviluppo che hanno utilizzato un approccio di modellazione predittiva (tabella supplementare A). Quasi tutti gli studi hanno utilizzato la morte, il ricovero in terapia intensiva, l’arresto cardiaco o un composto di questi. Le misure di esito primario più comuni sono state la morte (n=10, 44%) e l’arresto cardiaco (n=4, 17%). Sono stati utilizzati anche diversi orizzonti temporali di previsione; il più frequente è stato di 24 ore (n=8, 35%). Altri orizzonti comuni erano 12 ore (n=3, 13%), 30 giorni (n=3, 13%), o in ospedale (n=6, 26%). La Figura 2 mostra una ripartizione degli esiti e dei loro orizzonti temporali.
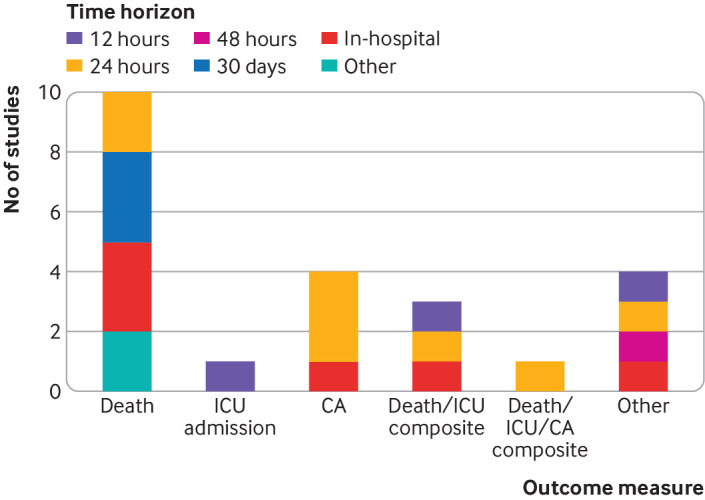
Fig. 2.Sintesi dei risultati di sviluppo e degli orizzonti temporali che appaiono in 23 studi che hanno utilizzato l’approccio della modellazione di regressione per sviluppare il punteggio di allerta precoce. CA=arresto cardiaco; TI=unità di terapia intensiva
Fig. 2.Sintesi dei risultati di sviluppo e degli orizzonti temporali che appaiono in 23 studi che hanno utilizzato l’approccio della modellazione di regressione per sviluppare il punteggio di allerta precoce. CA=arresto cardiaco; TI=unità di terapia intensiva
Predittori
Ventuno dei 23 (91%) studi di sviluppo che hanno utilizzato un approccio di modellazione predittiva hanno riportato quanti predittori candidati sono stati presi in considerazione per l’inclusione nel SAR, riportando insieme una mediana di 12 (range 4-45) predittori (tabella supplementare B). Il numero mediano di predittori inclusi nel modello finale era di sette (range 3-35). L’approccio più comune per la selezione delle variabili da includere è stato l’eliminazione a ritroso (n=9/23, 39%). Sei dei 23 modelli (26%) includevano tutte le variabili candidate e tre studi (13%) hanno effettuato uno screening univoco per ridurre il numero iniziale di variabili candidate.
Il predittore più frequentemente incluso nei 34 studi di sviluppo è stato la frequenza respiratoria (n=30, 88%), seguita da frequenza cardiaca (n=28, 83%), saturazione di ossigeno (n=24, 71%), temperatura (n=24, 71%), pressione sanguigna sistolica (n=24, 71%) e livello di coscienza (n=19, 56%). Tredici modelli includevano l’età (38%) e tre modelli includevano il sesso (9%).
Dimensione del campione (per 29 studi sviluppati con il metodo statistico)
La dimensione del campione negli studi EWS può essere complicata perché potrebbero esserci più set di osservazione per ogni paziente o ricovero in ospedale. Non è sempre stato chiaro se la dimensione del campione riportato si riferisse al numero di pazienti, ai ricoveri ospedalieri o ai set di osservazione (n=3; tabella supplementare C). La dimensione mediana del campione di pazienti o di ricoveri ospedalieri era di 10-712 (range 242-649-418). Undici dei 29 articoli (38%) hanno utilizzato più set di osservazione per ogni paziente, 15 (52%) hanno utilizzato un set di osservazione per ogni paziente e tre (10%) non erano chiari. Dei 15 studi che hanno utilizzato un solo set di osservazione per ogni paziente, la prima osservazione registrata è stata generalmente utilizzata (n=9, 60%).
Il numero mediano di eventi a livello di paziente è stato di 396 (range 18-19-153) e a livello di set di osservazione è stato di 284 (18-15-452). Un articolo non ha riportato il numero di eventi a livello di paziente e otto articoli non hanno riportato il numero di eventi a livello di osservazione. Questa differenza di denominatore spiega come il numero mediano di eventi possa essere maggiore a livello di paziente che a livello di set di osservazione.
Gli eventi per variabile è un indicatore chiave dell’adeguatezza delle dimensioni del campione negli studi di modellazione predittiva ed è definito come il numero di eventi diviso per il numero di variabili predittive candidate utilizzate. Venti articoli hanno utilizzato un approccio di modellazione predittiva e hanno fornito informazioni sufficienti per calcolare gli eventi a livello di paziente per variabile, con una mediana di 52 e un intervallo da 1 a 1288. Quindici studi hanno fornito informazioni sufficienti per calcolare gli eventi di livello di osservazione per variabile, con una mediana di 17 e un intervallo da 1 a 2693.
Metodi statistici
La maggior parte degli articoli che hanno utilizzato metodi statistici per sviluppare un SAR ha menzionato dati mancanti (n=25/29, 86%). La tabella supplementare C elenca i metodi per trattare i dati mancanti; l’analisi completa dei casi è stata l’approccio più comune (n=10/25, 40%). Nessuno degli studi inclusi ha utilizzato l’imputazione multipla per gestire i dati mancanti nello sviluppo di un EWS. Quattro articoli hanno menzionato i dati mancanti, ma non hanno indicato chiaramente quale metodo è stato utilizzato per gestirli.
La maggior parte dei 23 modelli sviluppati utilizzando un approccio di modellizzazione predittiva ha utilizzato la regressione logistica (n=15, 65%). Altri metodi includevano l’apprendimento automatico (n=4, 17%), la regressione proporzionale dei pericoli Cox, la regressione logistica multinomiale, la regressione logistica a tempo discreto e la classificazione ingenua di Bayes combinata con la regressione logistica (tutti n=1, 4%). I quattro studi di machine learning hanno utilizzato alberi decisionali (n=2), reti neurali artificiali (n=1) o foreste casuali (n=1).
Per la gestione dei predittori continui e l’uso dei termini di interazione, tutti i 23 modelli di previsione includevano almeno una variabile continua (tabella supplementare C). L’approccio più comune per la gestione di queste variabili è stato quello di categorizzare la variabile prima dell’analisi (n=7, 30%). Altri metodi comprendevano le spline (n=6, 26%), le relazioni lineari (n=4, 17%) e i polinomi frazionari (n=2, 9%). Quattro studi hanno utilizzato altri metodi.
Presentazione del modello
Nove dei 23 (39%) modelli sviluppati utilizzando un approccio di modellazione predittiva hanno riportato la formula di regressione completa, con tutti i coefficienti e l’intercettazione o il pericolo di base (tabella supplementare E). Dei rimanenti modelli, sette (30%) non hanno riportato alcun coefficiente, e sette (30%) hanno riportato i coefficienti predittivi ma non l’intercettazione o il pericolo di base.
Tredici degli studi (57%) hanno riportato informazioni sufficienti per il calcolo di previsioni di rischio individualizzate. Due articoli (9%) hanno riportato la costruzione di gruppi di rischio. Dieci articoli (44%) hanno creato un modello semplificato, anche se solo cinque hanno descritto come ciò è stato fatto. Questi modelli semplificati hanno tipicamente ridotto i coefficienti del modello a un sistema di punteggio basato sui punti, senza alcun metodo di calcolo dei rischi previsti.
Prestazioni predittive apparenti
Ventidue studi hanno valutato le prestazioni utilizzando gli stessi dati utilizzati nello sviluppo del modello, valutando così le prestazioni apparenti (tabella supplementare F). Diciotto di questi studi (82%) hanno valutato la discriminazione con l’indice C, con valori che vanno da 0,69 a 0,96. La calibrazione è stata valutata per otto modelli (36%); sette hanno utilizzato il test Hosmer-Lemeshow goodness-of-fit, e uno ha utilizzato un grafico di calibrazione. Tra le altre metriche di performance riportate vi sono la sensibilità e la specificità (n=8, 36%) e i valori predittivi positivi o negativi (n=4, 18%). Otto studi hanno presentato curve caratteristiche di funzionamento del ricevitore.
Convalida interna
La tabella supplementare G mostra il resoconto della convalida interna nei 34 studi di sviluppo. Diciannove modelli sono stati validati internamente. Si noti che due studi supplementari comprendevano una convalida esterna dei loro nuovi SAR, ma non una convalida interna. La maggior parte degli studi ha suddiviso i dati in dati di sviluppo e di convalida (n=13/19, 68%). Due articoli hanno utilizzato il bootstrapping e due la validazione incrociata (entrambi 11%). Gli altri due hanno valutato le prestazioni utilizzando i dati di derivazione combinati con dati aggiuntivi (11%). Tutti gli studi che hanno valutato la discriminazione hanno utilizzato l’indice C. La calibrazione è stata valutata in quattro studi, uno con un grafico di calibrazione e tre con il test Hosmer-Lemeshow. La sensibilità e la specificità sono state riportate in sei studi e otto studi hanno prodotto curve caratteristiche di funzionamento del ricevitore.
Studi che descrivono la validazione esterna dell’EWS
Abbiamo incluso 84 articoli che hanno validato esternamente un EWS (tabella 2). Ventitré di questi hanno anche descritto lo sviluppo di un EWS. Cinque hanno sviluppato un EWS e lo hanno validato esternamente in un set di dati esterno, e 18 hanno sviluppato un EWS e convalidato esternamente un diverso EWS utilizzando il set di dati di sviluppo.
| Riferimento | Tipo di set di dati | Paese | Anno | EWS convalidato | Età media | Maschio (%) |
|---|---|---|---|---|---|---|
| Abbott 201663 | Coorte prospettica | REGNO UNITO | 2013 | NOTIZIE | 63 | 48 |
| Abbott 201564 | Coorte prospettica | REGNO UNITO | 2013 | NOTIZIE | 61 | 46 |
| Alvarez 201332 | Coorte prospettica | US | 2009-10 | MEWS | 51 | 54 |
| Atmaca 201865 | Coorte prospettica | Turchia | 2014 | NOTIZIE | 57 | 55 |
| Badriyah 201433 | Coorte retrospettiva/base dati | REGNO UNITO | 2006-08 | NOTIZIE | 68 | 47 |
| Bartkowiak 201966 | Coorte retrospettiva/base dati | US | 2008-16 | eCART, NOTIZIE, MEWS | 54 | 43 |
| Beane 201867 | Coorte retrospettiva/base dati | Sri Lanka | 2015 | MEWS, NOTIZIE, CARRELLO, VIEWS | 43 | 41 |
| Bleyer 201134 | Coorte retrospettiva/base dati | US | 2008-09 | NOTIZIE, ViEWS | 57 | 51 |
| Brabrand 201768 | Coorte retrospettiva/base dati | Danimarca | 2012 | NOTIZIE, Worthing, Groarke, Goodacre | 67 | 50 |
| Brabrand 201869 | Coorte retrospettiva/base dati | Danimarca | Manca | NOTIZIE | 74 | 49 |
| Cei 200970 | Coorte prospettica | Italia | 2005-06 | MEWS | 79 | 44 |
| Churpek 201771 | Coorte retrospettiva/base dati | US | 2008-16 | eCART, NOTIZIE, MEWS | 57 | 46 |
| Churpek 201772 | Coorte retrospettiva/base dati | US | 2008-16 | NOTIZIE, MEWS | 57 | 48 |
| Churpek 201373 | Coorte retrospettiva/base dati | US | 2008-11 | CEWS, MEWS, ViEWS, CARRELLO | 55 | 44 |
| Churpek 201436 | Coorte retrospettiva/base dati | US | 2008-13 | MEWS | 60 | 40 |
| Churpek 201274 | Altro | US | 2008-11 | MEWS | 59 | 52 |
| Churpek 20128 | Coorte retrospettiva/base dati | US | 2008-11 | CARRELLO, MEWS | 54 | 43 |
| Churpek 201435 | Coorte retrospettiva/base dati | US | 2008-11 | ViEWS | 54 | 43 |
| Cooksley 201275 | Coorte retrospettiva/base dati | REGNO UNITO | 2009-11 | NOTIZIE, MEWS | 63 | 51 |
| Cuthbertson 201038 | Coorte prospettica | REGNO UNITO | 2005 | EWS, MEWS | 65 | 51 |
| De Meester 201376 | Coorte prospettica | Belgio | 2009-10 | MEWS | 59 | 60 |
| DeVoe 201677 | Coorte retrospettiva/base dati | US | 2007-13 | MEWS | 75 | 61 |
| Douw 201778 | Coorte retrospettiva/base dati | Paesi Bassi | 2013-14 | DENWIS | 60 | 47 |
| Duckitt 200739 | Coorte prospettica | REGNO UNITO | 2003-05 | EWS | 73 | 52 |
| Dziadzko 201840 | Coorte retrospettiva/base dati | US | 2017 | APPROVA, MIAGOLIO, NOTIZIE | 56 | 33 |
| Eccles 201479 | Coorte retrospettiva/base dati | REGNO UNITO | 2012 | NOTIZIE | 70 | 50 |
| Escobar 201241 | Coorte retrospettiva/base dati | US | 2006-09 | MEWS | 65 | 45 |
| Fairclough 200980 | Coorte prospettica | REGNO UNITO | 2004-06 | MEWS | 73 | 43 |
| Faisal 201842 | Coorte retrospettiva/base dati | REGNO UNITO | 2014-15 | CARM | 68 | 48 |
| Finlay 201481 | Coorte retrospettiva/base dati | US | 2009-10 | MEWS | 65 | NR |
| Forster 201882 | Coorte retrospettiva/base dati | REGNO UNITO | 2015-17 | NOTIZIE | 63 | 47 |
| Garcea 200683 | Coorte retrospettiva/base dati | REGNO UNITO | 2002-06 | EWS | 57 | NR |
| Gardner 200684 | Coorte prospettica | REGNO UNITO | 2003 | MEWS | 59 | 50 |
| Ghanem 201185 | Coorte prospettica | Israele | 2008-09 | MEWS | 75 | 52 |
| Ghosh 201843 | Coorte retrospettiva/base dati | US | 2012-13 | MEWS, NOTIZIE | 59 | NR |
| Verde 201886 | Coorte retrospettiva/base dati | US | 2008-13 | MEWS, NOTIZIE, eCART | 62 | 41 |
| Harrison 200645 | Coorte retrospettiva/base dati | Australia | 2000 | MEWS | NR | NR |
| Hodgson 201787 | Coorte retrospettiva/base dati | REGNO UNITO | 2012-14 | NOTIZIE | 74 | NR |
| Hydes 201888 | Coorte retrospettiva/base dati | REGNO UNITO | 2010-14 | NOTIZIE, EWS, MEWS, MEWS+age, Worthing | 57 | 61 |
| Jo 201689 | Coorte retrospettiva/base dati | Corea del Sud | 2013-14 | NOTIZIE | 70 | 63 |
| Kellett 201290 | Coorte retrospettiva/base dati | Canada | 2005-11 | ViEWS | 63 | 49 |
| Kellett 201691 | Coorte prospettica | Canada | 2005-16 | ViEWS | 65 | 49 |
| Kim 201892 | Coorte retrospettiva/base dati | Corea del Sud | 2014-15 | NOTIZIE | 65 | 70 |
| Kim 201793 | Coorte retrospettiva/base dati | Corea del Sud | 2008-15 | MEWS | 61 | 65 |
| Kipnis 201649 | Coorte retrospettiva/base dati | US | 2010-13 | eCART, NOTIZIE | 65 | 46 |
| Kovacs 201694 | Coorte retrospettiva/base dati | REGNO UNITO | 2011-13 | NOTIZIE | 57 | 47 |
| Kruisselbrink 201695 | Coorte prospettica | Uganda | 2013 | MEWS | 43 | 54 |
| Kwon 201851 | Coorte/base dati retrospettiva | Corea del Sud | 2017 | MEWS | 58 | 50 |
| LeLagadec 202096 | Controllo retrospettivo del caso | Australia | 2014-17 | NOTIZIE | 73 | 53 |
| Lee 201897 | Coorte retrospettiva/base dati | Corea del Sud | 2013-14 | NOTIZIE | 62 | 58 |
| Liljehult 201698 | Coorte retrospettiva/base dati | Danimarca | 2012 | NOTIZIE | 72 | 50 |
| Luis 201853 | Coorte retrospettiva/base dati | Portogallo | 2012 | NOTIZIE | NR | 48 |
| Moore 201754 | Coorte retrospettiva/base dati | Gabon, Malawi, Sierra Leone, Tanzania, Uganda e Zambia | 2009-15 | MEWS | 36 | 49 |
| Mulligan 201099 | Coorte prospettica | REGNO UNITO | 2007 | EWS | 48 | 85 |
| Öhman 2018100 | Coorte retrospettiva/base dati | Danimarca | 2008-10 | MARS | 65 | 50 |
| Opio 2013101 | Coorte retrospettiva/base dati | Uganda | 2012 | ViEWS | 45 | 42 |
| Opio 2013102 | Coorte prospettica | Irlanda | 2011-13 | TOTALE | 64 | 53 |
| Pedersen 2018103 | Coorte retrospettiva/base dati | Danimarca | 2014 | NOTIZIE | 74 | 42 |
| Perera 201156 | Coorte prospettica | Sri Lanka | 2009 | MEWS | 49 | 48 |
| Pimentel 2019104 | Coorte retrospettiva/base dati | REGNO UNITO | 2012-16 | NOTIZIE | 68 | 48 |
| Piastra 2018105 | Coorte retrospettiva/base dati | Paesi Bassi | 2014-16 | ViEWS | 61 | 65 |
| Prytherch 201057 | Coorte retrospettiva/base dati | REGNO UNITO | 2006-08 | EWS, Goldhill, MEWS, MEWS+age, Worthing | 68 | 48 |
| Redfern 2018106 | Coorte retrospettiva/base dati | REGNO UNITO | 2010-16 | NOTIZIE | 63 | 47 |
| Redfern 201858 | Coorte retrospettiva/base dati | REGNO UNITO | 2016 | LDTEWS:NOTIZIE, NOTIZIE, NOTIZIE | 73 | 50 |
| Roberts 2017107 | Coorte retrospettiva/base dati | Svezia | 2014-15 | NOTIZIE | NR | 60 |
| Romero 2017108 | Coorte retrospettiva/base dati | US | 2011 | GMEWS, Kirkland, MEWS, MEWS, NOTIZIE, ViEWS, Worthing | 59 | 49 |
| Romero 2014109 | Coorte retrospettiva/base dati | US | 2011 | MEWS, GMEWS, Worthing, ViEWS, NOTIZIE | 59 | 49 |
| Rylance 2009110 | Coorte prospettica | Tanzania | 2005 | MEWS | NR | 34 |
| Silke 201059 | Coorte retrospettiva/base dati | Irlanda | 2000-04 | MARS | 59 | 48 |
| Smith 2008111 | Coorte/base dati retrospettiva | REGNO UNITO | 2006 | EWS, Goldhill, MEWS, MEWS+age, Worthing | 68 | 48 |
| Smith 2013112 | Coorte retrospettiva/base dati | REGNO UNITO | 2006-08 | NOTIZIE, EWS, Goldhill, MEWS, MEWS+age, Worthing | 68 | 47 |
| Smith 2016113 | Coorte retrospettiva/base dati | REGNO UNITO | 2011-13 | NOTIZIE | 62 | 48 |
| Smith 2016114 | Coorte retrospettiva/base dati | US | 2014-15 | NOTIZIE | 53 | NR |
| Spagnolli 2017115 | Coorte prospettica | Italia | 2013-15 | NOTIZIE | 72 | 50 |
| Stark 2015116 | Coorte retrospettiva/base dati | US | 2013-14 | MEWS | 62 | 65 |
| Stræede 2014117 | Coorte retrospettiva/base dati | Danimarca | 2008-09 | SCS, HOTEL | 62 | 52 |
| Subbe 2001118 | Coorte retrospettiva/base dati | REGNO UNITO | 2000 | MEWS, MEWS+età | 63 | 45 |
| Suppiah 2014119 | Coorte prospettica | REGNO UNITO | 2010 | MEWS | 56 | 50 |
| Tirkkkonen 2014120 | Coorte prospettica | Finlandia | 2010 | NOTIZIE | 65 | 53 |
| Tirotta2017121 | Coorte prospettica | Italia | 2012 | MEZZI, TOTALE | 73 | 50 |
| Vaughn 2018122 | Coorte retrospettiva/base dati | US | 2011-15 | MEWS | 54 | NR |
| VonLilienfeld-Toal 2007123 | Coorte retrospettiva/base dati | Manca | 2002-04 | MEWS | 40 | 51 |
| Watkinson 201861 | Coorte retrospettiva/base dati | REGNO UNITO | 2015-17 | CART, CEWS, Goldhill, MEWS, MEWS+age, NOTIZIE | 68 | 49 |
| Wheeler 201362 | Coorte prospettica | Malawi | 2012 | MEWS, HOTEL | 40 | 51 |
Modelli convalidati
Ventidue modelli sono stati convalidati in tutti gli 84 studi (fig. 3). Il punteggio di allerta precoce modificato61 è stato convalidato con maggiore frequenza (n=43), seguito dal punteggio nazionale di allerta precoce (NEWS)44 (n=40). Il punteggio di allerta precoce VitalPAC,62 su cui si basava il NEWS, è stato convalidato 10 volte, mentre l’EWS5 originale è stato convalidato 8 volte.
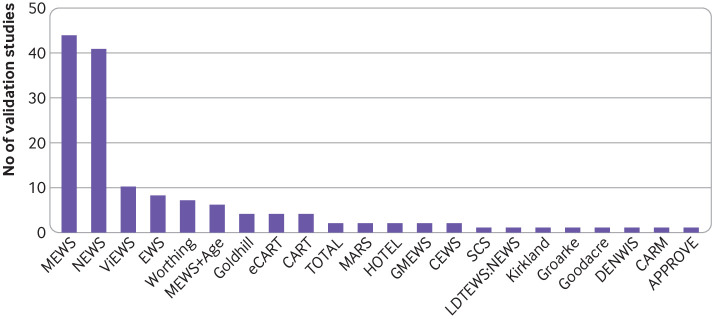
Fig. 3.Fig. 3. La frequenza della convalida del modello esterno tramite il punteggio di allerta precoce (EWS) in 84 comprendeva studi di convalida. Otto EWS non erano mai stati convalidati esternamente. APPROVE=predizione accurata della ventilazione prolungata; CARM=rischio di mortalità assistito dal computer; CART=triage del rischio di arresto cardiaco; CEWS=punteggio di allarme precoce gentile; DENWIS=punteggio dell’indicatore di preoccupazione infermieristico olandese; eCART=triage del rischio di arresto cardiaco elettronico; GMEWS=punteggio di allarme precoce globale modificato; HOTEL=ipotensione, saturazione di ossigeno, temperatura, anomalia dell’ECG [elettrocardiogramma], perdita di indipendenza; LDTEWS=punteggio di allarme precoce dell’albero decisionale del laboratorio; MARS=sistema di rischio per i ricoveri medici; MEWS=punteggio di allarme precoce modificato; NEWS=punteggio di allarme precoce nazionale; SCS=punteggio clinico minimo; TOTALE=tachipnea, saturazione di ossigeno, temperatura, allarme e perdita di indipendenza; ViEWS=punteggio di allarme precoce VitalPAC.
Fig. 3.Fig. 3. La frequenza della validazione del modello esterno tramite il punteggio di allerta precoce (EWS) in 84 studi di validazione inclusi. Otto EWS non erano mai stati convalidati esternamente. APPROVE=predizione accurata della ventilazione prolungata; CARM=rischio di mortalità assistito dal computer; CART=triage del rischio di arresto cardiaco; CEWS=punteggio di allerta precoce gentile; DENWIS=punteggio dell’indicatore di preoccupazione infermieristica olandese; eCART=triage del rischio di arresto cardiaco elettronico; GMEWS=punteggio di allerta precoce globale modificato; HOTEL=ipotensione, saturazione di ossigeno, temperatura, anormalità dell’ECG [elettrocardiogramma], perdita di indipendenza; LDTEWS=punteggio di allarme precoce dell’albero decisionale del laboratorio; MARS=sistema di rischio per i ricoveri medici; MEWS=punteggio di allarme precoce modificato; NEWS=punteggio di allarme precoce nazionale; SCS=punteggio clinico minimo; TOTALE=tachipnea, saturazione di ossigeno, temperatura, allarme e perdita di indipendenza; ViEWS=punteggio di allarme precoce VitalPAC.
Progettazione dello studio
La maggior parte degli articoli di validazione (n=58/84, 69%) ha utilizzato dati esistenti per validare esternamente un EWS (tabella 2). Venticinque (30%) hanno raccolto dati prospettici per la validazione esterna. I dati utilizzati per convalidare gli EWS sono stati tutti raccolti tra il 2000 e il 2017. Trentatre degli 84 studi (39%) non hanno descritto adeguatamente il loro set di dati, mancando almeno uno dei seguenti: età media, distribuzione di uomini e donne, numero di pazienti con o senza l’evento, e numero di set di osservazione con o senza l’evento.
Misure di risultato e tempi di orizzonte
I modelli sono stati validati a fronte di una serie di risultati (fig. 4, tabella supplementare H). Il più frequente è stato il decesso, che è stato incluso in 66 degli 84 articoli (79%), seguito da un ricovero in terapia intensiva non previsto (n=22, 26%), e un insieme di decessi e ricoveri non previsti in terapia intensiva (n=17, 20%). Sono stati utilizzati diversi orizzonti di previsione. In ospedale (cioè il resto della degenza) è stato il punto temporale più utilizzato (n=58, 69%), seguito da 24 ore (n=56, 67%). La Figura 4 mostra tutte le combinazioni di esito e di orizzonte temporale; il decesso in ospedale è stato il punto finale più comunemente convalidato (n=26, 31%).
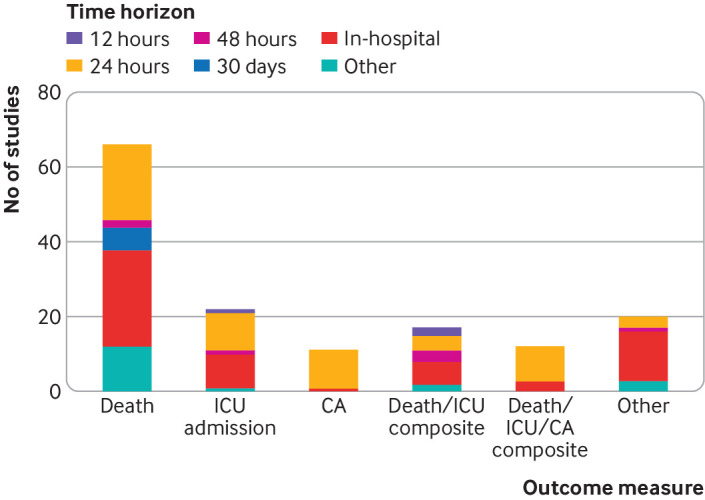
Fig. 4.Sintesi degli esiti e degli orizzonti temporali utilizzati in 84 studi che convalidano esternamente un punteggio di allarme precoce. CA=arresto cardiaco; TI=unità di terapia intensiva
Fig. 4.Sintesi dei risultati e degli orizzonti temporali utilizzati in 84 studi che convalidano esternamente un punteggio di allerta precoce. CA=arresto cardiaco; TI=unità di terapia intensiva
Dimensione del campione
La tabella supplementare I mostra le informazioni riportate sulle dimensioni del campione utilizzate in ogni convalida esterna. Il numero di pazienti e di set di osservazione non ha potuto essere identificato in otto studi e il numero di pazienti e di set di osservazione di eventi non ha potuto essere identificato in 25 studi. Per gli studi che hanno riportato questi dati, il numero mediano di pazienti inclusi negli articoli di validazione era 2806 (range 43-649-418) e il numero mediano di set di osservazione era 3160 (range 43-48-723248). Il numero mediano di pazienti affetti da eventi è stato di 126, da 6 a 19-153.
Sono stati utilizzati più set di osservazione per ogni paziente in 23 di 84 articoli (27%), mentre un set di osservazione per ogni paziente è stato utilizzato in 55 articoli (66%). Gli altri sei studi non hanno indicato chiaramente se sono stati utilizzati più set di osservazione. La maggior parte degli studi che hanno utilizzato un unico set di osservazione per ogni paziente ha utilizzato il primo set di osservazione (n=41/55, 75%).
Metodi statistici
Sessantatre degli 84 articoli di convalida (75%) menzionano dati mancanti (tabella supplementare J). L’approccio più comune per trattare i dati mancanti è stato l’analisi completa dei casi (n=36, 57%), seguita dall’utilizzo dell’ultima osservazione riportata (n=8, 13%). Per sette studi il metodo non era chiaro (11%). Due articoli hanno riferito di non avere dati mancanti (3%). Un articolo ha utilizzato l’imputazione multipla (2%).
Prestazioni predittive
Sessantanove degli 84 studi di validazione (82%) hanno valutato la discriminazione basata su modelli (tabella supplementare K). Tutti questi studi hanno utilizzato l’indice C, con valori compresi tra 0,55 e 0,96. La calibrazione del modello è stata valutata in 15 studi, più comunemente utilizzando il test Hosmer-Lemeshow (n=11, 73%). I grafici di calibrazione sono stati presentati in quattro studi (27%). Altre metriche di performance comunemente riportate includono sensibilità e specificità (n=49, 58%), e valori predittivi positivi o negativi (n=31, 37%). Le metriche di performance complessive, come il punteggio Brier e R2, non sono state riportate in nessuno degli studi.
A causa dell’eterogeneità dei risultati e degli orizzonti temporali utilizzati negli studi di validazione e della relativa mancanza di confronti testa a testa, non abbiamo sintetizzato quantitativamente le metriche di performance per specifici EWS.
PROBAST rischio di valutazione del bias
Abbiamo valutato il rischio di distorsione per ogni studio, concentrandoci sulla selezione dei partecipanti, sui predittori, sui risultati e sull’analisi (fig. 5). La selezione dei partecipanti era a basso rischio di distorsione nel 42% degli studi e ad alto rischio di distorsione nel 55%. Per gli altri studi, il rischio di distorsione non era chiaro. I predittori erano a basso rischio di distorsioni nel 91% degli studi e ad alto rischio nel 5%. I risultati sono stati a basso rischio di distorsione nel 31% degli studi e ad alto rischio nel 66%. I metodi di analisi erano ad alto rischio di distorsione in tutti gli studi tranne due (98%).
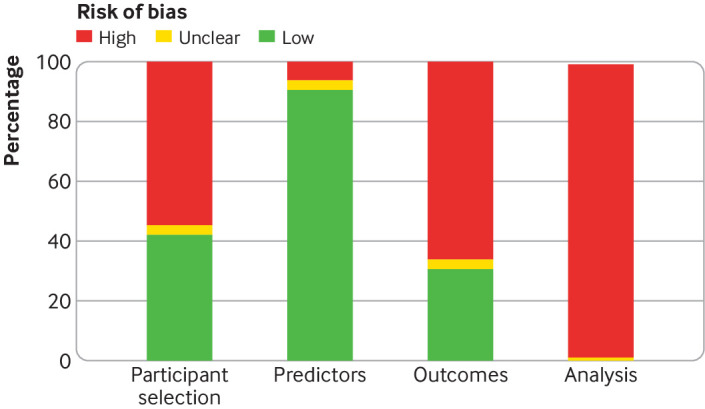
Fig. 5.Sintesi del rischio di distorsione in quattro settori di 95 studi che sviluppano o convalidano un punteggio di allerta precoce, valutato utilizzando PROBAST (strumento di valutazione del rischio di distorsione del modello di previsione)
Fig. 5.Sintesi del rischio di bias in quattro settori di 95 studi che sviluppano o convalidano un punteggio di allerta precoce, valutato con PROBAST (strumento di valutazione del rischio di bias del modello di previsione del rischio)
Discussione
La nostra revisione di 95 studi pubblicati ha trovato metodi scadenti e rapporti inadeguati nella maggior parte degli studi che hanno sviluppato o convalidato gli EWS. Sono stati osservati problemi in tutti gli aspetti della progettazione e dell’analisi degli studi. Abbiamo trovato che la gestione dei problemi statistici, come la mancanza di dati e gli approcci di modellizzazione della regressione, era inadeguata. Pochi studi hanno valutato la calibrazione, un aspetto essenziale delle prestazioni del modello, e nessuno studio ha valutato l’utilità clinica utilizzando approcci di net benefit. 124 Molti studi non hanno inoltre riportato dettagli importanti, come la dimensione del campione, il numero di eventi, le caratteristiche della popolazione e i dettagli dei metodi statistici. Diversi studi non sono riusciti a riportare il modello completo, impedendo la validazione esterna (indipendente) o l’implementazione del modello nella pratica.
Le SGA sviluppate con metodi inadeguati probabilmente porteranno a sistemi di punteggio poco efficienti che non sono in grado di prevedere il deterioramento. 125 Metodi inadeguati negli studi di validazione esterna potrebbero portare all’implementazione di sistemi di punteggio inferiori, con false rassicurazioni sulla loro capacità predittiva e generalizzabilità. Questi rapporti potrebbero spiegare perché le recenti revisioni sistematiche hanno trovato poche prove dell’efficacia clinica degli EWS. 24126 Sebbene sia necessaria una valutazione formale dei metodi e della qualità del reporting dei SAR, alcune revisioni hanno rilevato che gli studi che descrivono lo sviluppo o la validazione di un SAR erano di bassa qualità, utilizzavano metodi statistici scadenti ed erano ad alto rischio di distorsione. 23
24
Abbiamo valutato il rischio di distorsione utilizzando PROBAST30 e abbiamo riscontrato che la maggior parte degli studi inclusi erano a rischio di distorsione a causa della selezione dei partecipanti, delle definizioni dei risultati e delle analisi statistiche. L’unico settore per il quale la maggior parte degli studi era a basso rischio di distorsione è stato quello della selezione dei predittori. Nel complesso, tutti gli studi erano ad alto rischio di distorsione.
Il nostro studio comprendeva più studi di validazione esterna che non studi di sviluppo (11 studi di sviluppo, 61 studi di validazione e 23 studi che hanno entrambi sviluppato e validato un modello), il che differisce dalle revisioni condotte in altre aree cliniche. 1921 I nostri criteri di idoneità potrebbero in parte spiegare questa differenza. Abbiamo stabilito che uno studio di sviluppo non deve essere incluso se viene sviluppato un modello per una specifica sottopopolazione (ad esempio, pazienti con malattie respiratorie), ma uno studio di validazione esterno potrebbe essere incluso se un EWS sviluppato per una popolazione generale viene valutato in una specifica sottopopolazione. Un numero relativamente elevato di studi ha riportato l’uso di dati prospettici (24% studi di sviluppo e 30% studi di validazione). Poiché i dati richiesti per lo sviluppo e la validazione dei sistemi di allarme elettromagnetici sono comunemente raccolti di routine, alcuni autori potrebbero segnalare una decisione prospettica di utilizzare i dati acquisiti di routine piuttosto che l’implementazione di un processo di acquisizione di dati prospettici.
I sistemi EWS sono stati storicamente implementati come parte delle carte di osservazione cartacee. Poiché i punteggi erano calcolati manualmente, erano necessari semplici sistemi di punteggio. Questi sistemi spesso si basavano sull’assegnazione di punti ad ogni segno vitale, tipicamente tre punti, e sulla somma dei punti per ottenere un punteggio totale. Tuttavia, questi sistemi fanno l’improbabile supposizione che ogni segno vitale abbia lo stesso valore predittivo. 8 Il punteggio totale ha poco significato e non esiste una corrispondenza evidente con un rischio assoluto di un evento.
Le cartelle cliniche elettroniche sono sempre più utilizzate per registrare i segni vitali e calcolare i SAR. 127 Queste registrazioni consentono l’implementazione di EWS più sofisticati che sfruttano appieno i dati disponibili e possono essere integrati nel flusso di lavoro clinico degli operatori sanitari. Poiché l’adozione della registrazione digitale dei segni vitali porta inevitabilmente a ulteriori ricerche, è importante che queste ricerche siano della massima qualità, in particolare quando si è manifestato l’interesse per l’uso dell’apprendimento automatico o dell’intelligenza artificiale. I risultati della nostra revisione suggeriscono raccomandazioni per le ricerche future (riquadro 2).
Fornire i dettagli chiave della popolazione di analisi
Suggeriamo che gli articoli riportino la demografia della popolazione (ad esempio, età e sesso), la fonte dei dati (paese, ospedale e reparto), il numero di pazienti con e senza l’evento di interesse, e il numero di set di osservazione con e senza l’evento di interesse.
Utilizzare un campione di dimensioni sufficientemente grandi
La dimensione del campione dovrebbe essere sufficiente per rispondere in modo robusto alla domanda. Per gli studi di sviluppo del modello si consiglia di eseguire un calcolo della dimensione del campione specifico per il contesto. Per gli studi di validazione esterni suggeriamo di includere almeno 100 pazienti evento.
Descrivere la quantità di dati mancanti e utilizzare metodi statistici per tener conto dei dati mancanti
Descrivere la frequenza dei dati mancanti per ogni predittore e risultato. Raccomandiamo che l’imputazione multipla sia l’approccio migliore per la contabilizzazione dei dati mancanti nell’analisi.
Considerare attentamente le misure di esito e gli orizzonti temporali
Utilizzare una misura di esito clinicamente significativa (cioè una misura di esito che può essere prevenuta con un trattamento appropriato) e un orizzonte temporale in cui ci si può ragionevolmente aspettare che il deterioramento si verifichi, e quindi che sia previsto, che probabilmente è di pochi giorni al massimo.
Utilizzare i metodi statistici delle migliori pratiche e riportare il modello completo
Se si utilizza un approccio di modellazione della regressione per sviluppare un nuovo EWS, gli studi dovrebbero consentire relazioni non lineari tra predittori e risultati (ad esempio, polinomi frazionari) ed evitare di categorizzare i predittori prima dell’analisi. I termini di interazione dei predittori e gli approcci di rischio concorrenti dovrebbero essere presi in considerazione, se opportuno. I modelli di nuova concezione dovrebbero essere sempre descritti in modo completo per consentire una valutazione e un’implementazione indipendente.
Effettuare sempre la validazione interna dei nuovi modelli
La validazione interna è un modo importante per valutare quanto possano essere ottimistici i nuovi modelli sviluppati. La validazione a campione diviso dovrebbe essere evitata e si dovrebbe usare il bootstrap.
Testare tutti gli aspetti delle prestazioni del modello
Valutare sia la calibrazione che la discriminazione degli EWS. Si consiglia inoltre di utilizzare l’analisi delle curve di decisione per valutare l’utilità clinica.
Raccomandazioni per la futura pratica di ricerca
Molte delle raccomandazioni sono coperte dalla dichiarazione TRIPOD (reporting trasparente di un modello di previsione multivariabile per la prognosi o la diagnosi individuale), che è una linea guida di reporting per gli studi che sviluppano o convalidano modelli prognostici (o diagnostici).
Descrivere i dati
Abbiamo scoperto che spesso i set di dati non sono stati descritti in modo sufficientemente dettagliato per capire in chi il modello era destinato all’uso o in chi era stato valutato. Questi dettagli sono cruciali quando si interpreta un articolo che descrive un EWS. Raccomandiamo che tutti gli studi riportino diversi fattori critici: il numero di pazienti con e senza l’evento di interesse; se vengono utilizzati più set di osservazione per paziente – se così fosse, il numero totale di set di osservazione con e senza un evento associato; la fonte dei dati (ad esempio, paese, ospedale e reparti); le caratteristiche del paziente (ad esempio, età, sesso e metodo di ammissione).
Utilizzare un campione di dimensioni sufficientemente grandi
Anche se molti degli studi della nostra recensione hanno utilizzato un grande campione acquisito da cartelle cliniche elettroniche, alcuni hanno utilizzato un campione troppo piccolo. Ad esempio, un quarto degli studi di sviluppo del modello aveva meno di sei eventi per ogni variabile a livello di paziente e quattro a livello di osservazione. Un quarto degli studi di validazione esterna ha incluso meno di 460 pazienti, e un quarto degli studi ha incluso meno di 35 pazienti con eventi. Poiché i risultati utilizzati negli studi EWS sono di solito rari (~1-2%) e il numero di eventi è un fattore critico, sono spesso necessarie grandi dimensioni del campione. Le linee guida suggeriscono che gli studi di validazione esterna richiedono un minimo di 100 pazienti con eventi, e preferibilmente più di 200.128 Pertanto, con i loro bassi tassi di eventi, gli studi EWS richiedono dati di molte migliaia di pazienti. Sebbene la definizione della dimensione del campione necessaria per gli studi di sviluppo del modello sia più complessa, sono disponibili nuove linee guida, che dovrebbero essere prese in considerazione prima di intraprendere nuovi studi EWS. 129130 I metodi di selezione variabile guidata dai dati aumentano la possibilità di un overfitting e quindi dovrebbero essere evitati, se possibile.
Tenere conto dei dati mancanti
La maggior parte degli studi inclusi ha menzionato dati mancanti (86% degli studi di sviluppo e 75% degli studi di validazione), anche se la maggior parte di questi studi ha utilizzato un’analisi completa del caso per trattare i dati mancanti. I dati non sono di solito mancanti a caso, ma vengono utilizzati in modo selettivo, ad esempio in base alle caratteristiche del paziente o alla gravità della malattia. Pertanto, l’esclusione di record con dati sui predittori o sugli esiti incompleti può portare a gravi distorsioni131132; ad esempio, gonfiando le associazioni tra predittori ed esiti.
Raccomandiamo che ogni studio descriva come sono stati gestiti i dati mancanti (ad esempio, utilizzando l’analisi completa del caso, l’imputazione singola o l’imputazione multipla). Gli studi dovrebbero anche descrivere la quantità di dati mancanti nel complesso, e per ogni variabile di predittore e risultato. Si raccomanda di evitare l’analisi completa dei casi. Dovrebbero invece essere presi in considerazione approcci di imputazione, con l’imputazione dei dati mancanti sulla base di altre informazioni note. Questi approcci sono ora facili da implementare in tutti i pacchetti software standard. L’imputazione multipla è ampiamente considerata l’approccio migliore. 133134135 Questo metodo consente di tener conto dell’incertezza sui dati mancanti creando set di dati imputati multipli, combinando poi in modo appropriato i risultati di ogni set di dati. Prima di implementare l’imputazione multipla si dovrebbe considerare attentamente il probabile meccanismo dei dati mancanti. Se l’imputazione è appropriata, anche l’impostazione del modello di imputazione dovrebbe essere attentamente considerata (ad esempio, la gestione delle variabili categoriali e delle variabili oblique), e riportata in modo completo. 136
Utilizzare misure di risultato e orizzonti temporali adeguati
Gli studi inclusi hanno utilizzato una varietà di misure di risultato e di orizzonti temporali per sviluppare e convalidare i SAR. Sia gli studi di sviluppo che quelli di validazione hanno utilizzato frequentemente la morte e l’ammissione imprevista in terapia intensiva, insieme a una varietà di risultati compositi che includevano questi risultati. Esiste un certo dibattito su quale sia la misura di outcome più appropriata. 27
Abbiamo scoperto che il 39% degli studi di sviluppo e il 52% degli studi di validazione includevano un orizzonte temporale che era in ospedale o di 30 giorni. Questi orizzonti a lungo termine non porteranno a modelli che diano un preavviso precoce di deterioramento. 24 I modelli che ne derivano, invece, identificheranno i pazienti generalmente malati che hanno maggiori probabilità di morire o di essere ricoverati in terapia intensiva. Raccomandiamo che l’orizzonte temporale sia limitato a pochi giorni al massimo, poiché qualsiasi segno di deterioramento legato ad un risultato osservato non sarà probabilmente visibile per un periodo più lungo di questo periodo.
Utilizzare approcci statistici basati sulle migliori pratiche e riportare il modello completo
Abbiamo osservato che molti articoli riportavano approcci di modellizzazione della regressione che erano metodologicamente deboli. Le relazioni non lineari tra predittori e risultati sono state incluse solo nel 23% degli studi di sviluppo. Tuttavia, questa è un’area di ricerca in cui tali relazioni potrebbero facilmente esistere. Ad esempio, sia i tassi respiratori bassi che quelli elevati possono indicare un aumento del rischio. Analogamente, le interazioni tra predittori sono state considerate solo nel 22% degli studi. I modelli per prevedere i risultati individuali del ricovero in terapia intensiva o dell’arresto cardiaco sono stati relativamente frequenti, ma pochi studi hanno considerato il decesso come un rischio concorrente (il ricovero in terapia intensiva o l’arresto cardiaco non è possibile se il decesso si è verificato). La mancata contabilizzazione del decesso come rischio concorrente potrebbe portare a un modello parziale e a previsioni imprecise. 137 Si raccomanda che il lavoro futuro tenga conto dei rischi concorrenti nello sviluppo del modello utilizzando i modelli Fine e Gray, causando pericoli specifici o la regressione del rischio assoluto138139140141 piuttosto che i modelli di regressione dei pericoli logistici e proporzionali Cox. La validazione esterna di tali modelli richiede anche che si tenga conto del potenziale dei rischi concorrenti. 142143 Abbiamo anche osservato che il modello completo (tutti i coefficienti di regressione e un’intercettazione o una sopravvivenza di base) è stato scarsamente riportato, con solo il 39% degli studi che riportavano informazioni sufficienti per consentire una validazione o un’implementazione indipendente.
Raccomandiamo che i futuri studi di sviluppo utilizzino metodi statistici basati sulle migliori pratiche, tra cui l’esame di termini di interazione plausibili (che dovrebbero essere scelti a priori e non basati sui dati), l’esame delle relazioni non lineari, l’eliminazione di metodi di selezione univariabili e la segnalazione di tutti i coefficienti di modellizzazione della regressione. I metodi utilizzati dovrebbero essere descritti in modo esaustivo nella pubblicazione e seguire le raccomandazioni contenute nella dichiarazione TRIPOD. 17
Utilizzare la validazione interna per i nuovi modelli
Le prestazioni apparenti di un modello di recente sviluppo sui suoi dati di sviluppo sono probabilmente ottimistiche e migliori delle sue prestazioni se applicate a dati esterni. Questo ottimismo può essere guidato da una piccola dimensione del campione, da molti predittori, o dalla categorizzazione di variabili continue. La validazione interna quantifica l’ottimismo e regola le prestazioni apparenti, e può essere usata per ridurre i coefficienti di regressione. 144145 Sebbene molti studi dividano casualmente il loro set di dati in due parti, una per lo sviluppo del modello e una per la validazione, questo approccio è debole e inefficiente. 144 Abbiamo scoperto che 16 dei nostri 34 articoli includevano studi di sviluppo che convalidavano internamente il loro EWS. Tuttavia, 11 hanno usato un approccio a campione diviso.
La validazione incrociata e il bootstrapping sono due approcci preferiti per la validazione interna. 146 Questi metodi utilizzano l’intero set di dati per sviluppare e convalidare il modello. Essi correggono anche l’overfitting nelle prestazioni del modello. Noi preferiamo il bootstrapping perché può spiegare l’ottimismo associato all’intero processo di costruzione del modello (per esempio, metodi di selezione delle variabili), e può anche fornire un meccanismo per ridurre i coefficienti di regressione per compensare l’overfitting. 144
147
Si consiglia di convalidare internamente i nuovi EWS, utilizzando, se possibile, il bootstrapping. Tuttavia, riconosciamo che i grandi set di dati stanno diventando sempre più presenti. In questo contesto il bootstrapping può richiedere molto tempo ed essere meno utile quando si utilizzano grandi dataset, perché in questi casi è meno probabile che si verifichi un overfitting. Raccomandiamo di adottare una forma di approccio a campione frazionato con grandi set di dati, in cui il set di dati non viene frazionato in modo casuale, ma secondo il tempo, la posizione o il centro. 29
Valutare tutti gli aspetti delle prestazioni del modello
Due aspetti chiave caratterizzano le prestazioni di un modello di previsione, la discriminazione e la calibrazione. 17148 La discriminazione si riferisce alla capacità di un modello di previsione di differenziare tra coloro che sviluppano un risultato e coloro che non lo sviluppano. Un modello dovrebbe prevedere rischi più elevati per coloro che sviluppano l’esito. La calibrazione riflette il livello di accordo tra gli esiti osservati e le previsioni del modello. Negli studi di sviluppo l’enfasi principale sarà posta sulla discriminazione perché il modello sarà, per definizione, ben calibrato. Tuttavia, negli studi di validazione esterna, sia la discriminazione che la calibrazione sono importanti. La maggior parte dei nostri studi inclusi ha valutato le prestazioni del modello utilizzando l’indice C, che è stato osservato in altre revisioni di modelli di previsione. 1821149150 Per esempio, sebbene l’82% degli articoli di validazione esterna abbia riportato una misura di discriminazione, solo il 18% ha riportato una valutazione della calibrazione. Quelli che hanno valutato la calibrazione hanno usato metodi deboli che non sono raccomandati. Solo quattro articoli (5%) hanno presentato l’approccio preferito per valutare la taratura, il diagramma di taratura.
Si consiglia di valutare sia la discriminazione che la calibrazione in studi di validazione esterni, in linea con le raccomandazioni TRIPOD. La calibrazione dovrebbe essere valutata con un grafico che metta a confronto i rischi previsti e osservati, con una curva levigata tracciata utilizzando LOESS (lisciatura del grafico a dispersione stimata localmente) o metodi simili, come polinomi frazionari o spline cubiche ristrette. 151 Devono essere riportate anche altre metriche di calibrazione, come l’intercettazione e la pendenza. 152 Molti EWS sono attualmente basati su un sistema di punteggio intero. Per esempio, le NEWS vanno da 0 a 20 punti. La taratura di un sistema di punteggio intero non può essere valutata perché si basa sul modello che produce le probabilità previste. Dovrebbero essere considerate anche le misure di prestazione complessiva, che combinano la discriminazione e la calibrazione, come R2 e il punteggio Brier. 152 Si raccomanda anche l’approccio più clinicamente significativo dell’analisi della curva di decisione (o del beneficio netto). 124
Punti deboli dello studio
Abbiamo valutato 34 studi di sviluppo, forse meno del previsto rispetto alle precedenti revisioni sistematiche. 111 Abbiamo escluso diversi EWS esistenti che non sono stati pubblicati su riviste accademiche peer reviewed. Tuttavia, prevediamo che i metodi alla base di questi EWS esclusi saranno di uno standard simile, e forse anche peggiore, rispetto a quelli inclusi nella nostra revisione.
I nostri criteri di ammissibilità stabiliscono che gli studi di validazione esterni saranno inclusi solo se verrà incluso anche lo studio di sviluppo. Tuttavia, abbiamo scelto di fare un’eccezione per gli studi che descrivono la convalida esterna dell’EWS originale di Morgan del 1997 e il punteggio di allarme precoce modificato di Subbe. Altrimenti questo criterio di ammissibilità escludeva pochi articoli.
Alcuni altri dettagli che non sono stati raccolti potrebbero essere interessanti per indagini future. Ad esempio, la ricerca potrebbe comprendere la motivazione della scelta della misura di esito e l’orizzonte temporale di previsione, e se i SAR sono stati sviluppati o convalidati utilizzando e contabilizzando dati multicentrici o raggruppati. 153
Punti di forza dello studio
Questa revisione sistematica ha valutato formalmente i metodi e gli standard di reporting degli studi EWS. Abbiamo effettuato una valutazione approfondita di aspetti importanti dello sviluppo e della validazione sulla base della checklist CHARMS,29 e di altri importanti argomenti specifici. Abbiamo anche valutato il rischio di distorsioni utilizzando lo strumento PROBAST. 30
Conclusione
Nella nostra recensione abbiamo incluso 95 articoli che hanno sviluppato o convalidato esternamente i SAR. Abbiamo trovato molte carenze metodologiche e di segnalazione. Pertanto, gli EWS di uso comune potrebbero avere prestazioni più scadenti di quelle riportate, con effetti potenzialmente dannosi per la cura del paziente. Le risposte cliniche a punteggi elevati hanno un forte impatto sul carico di lavoro,154 e le debolezze degli EWS influiscono sul carico di lavoro risultante. Pertanto, gli operatori sanitari e i responsabili politici devono essere consapevoli di questi punti deboli quando raccomandano particolari strategie di risposta.
Il nostro studio non cerca di raccomandare un particolare EWS, tuttavia NEWS è attualmente obbligatorio per l’uso in tutto il Servizio Sanitario Nazionale nel Regno Unito. 155 Questo sistema è stato sviluppato per consenso clinico piuttosto che applicando metodi statistici, che è il metodo abituale per sviluppare modelli di previsione. Le affermazioni di un’ampia convalida12 potrebbero essere fuorvianti, poiché abbiamo trovato che la metodologia alla base degli studi di convalida dell’EWS è generalmente scadente. In realtà, i clinici possono avere poca conoscenza di come tali punteggi si svolgeranno nel loro ambiente clinico. Pertanto, i medici dovrebbero essere cauti nell’affidarsi a questi punteggi per identificare il deterioramento clinico dei pazienti.
Il passaggio all’implementazione elettronica degli EWS rappresenta un’opportunità per introdurre sistemi di punteggio migliori, in particolare con il crescente interesse per i moderni approcci di costruzione di modelli, come l’apprendimento automatico e l’intelligenza artificiale. Tuttavia, se non si migliorano gli standard metodologici e di reporting, questo potenziale potrebbe non essere mai raggiunto.
Ciò che è già noto su questo argomento
- I punteggi di allerta precoce sono ampiamente utilizzati negli ospedali per identificare il deterioramento clinico dei pazienti, ad esempio il punteggio di allerta precoce modificato e il punteggio nazionale di allerta precoce
- I punteggi di preallarme sono comunemente implementati utilizzando sistemi elettronici
- Mancava una visione d’insieme sistematica degli studi che sviluppano e convalidano esternamente questi sistemi
Cosa aggiunge questo studio
- Un’abbondanza di articoli descrive lo sviluppo o la convalida dei punteggi di allerta precoce
- Nella maggior parte degli studi sono stati riscontrati metodi scadenti e rapporti inadeguati, e tutti gli studi erano a rischio di parzialità.
- I problemi metodologici potrebbero portare a sistemi di punteggio che non funzionano bene nella pratica clinica, il che potrebbe avere effetti negativi sulla cura del paziente
References
- Brennan TA, Leape LL, Laird NM. Incidence of adverse events and negligence in hospitalized patients. Results of the Harvard Medical Practice Study I. N Engl J Med. 1991; 324:370-6. DOI | PubMed
- Vincent C, Neale G, Woloshynowych M. Adverse events in British hospitals: preliminary retrospective record review. BMJ. 2001; 322:517-9. DOI | PubMed
- Hillman KM, Bristow PJ, Chey T. Duration of life-threatening antecedents prior to intensive care admission. Intensive Care Med. 2002; 28:1629-34. DOI | PubMed
- Publisher Full Text
- Prince Charles Hospital. Modified Early Warning Score (MEWS), Escalation and ISBAR, The Prince Charles Hospital Procedure TPCHS10085.
- Publisher Full Text
- Churpek MM, Yuen TC, Park SY, Meltzer DO, Hall JB, Edelson DP. Derivation of a cardiac arrest prediction model using ward vital signs. Crit Care Med. 2012; 40:2102-8. DOI | PubMed
- Douw G, Huisman-de Waal G, van Zanten AR, van der Hoeven JG, Schoonhoven L. Nurses’ ‘worry’ as predictor of deteriorating surgical ward patients: a prospective cohort study of the Dutch-Early-Nurse-Worry-Indicator-Score. Int J Nurs Stud. 2016; 59:134-40. DOI | PubMed
- Publisher Full Text
- Gerry S, Birks J, Bonnici T, Watkinson PJ, Kirtley S, Collins GS. Early warning scores for detecting deterioration in adult hospital patients: a systematic review protocol. BMJ Open. 2017; 7DOI | PubMed
- Royal College of Physicians. Royal College of Physicians National Early Warning Score (NEWS) 2: Standardising the assessment of acute-illness severity in the NHS. Updated report of a working party.. RCP; 2017.
- Silcock DJ, Corfield AR, Gowens PA, Rooney KD. Validation of the National Early Warning Score in the prehospital setting. Resuscitation. 2015; 89:31-5. DOI | PubMed
- Corfield AR, Lees F, Zealley I, Scottish Trauma Audit Group Sepsis Steering Group. Utility of a single early warning score in patients with sepsis in the emergency department. Emerg Med J. 2014; 31:482-7. DOI | PubMed
- Brangan E, Banks J, Brant H, Pullyblank A, Le Roux H, Redwood S. Using the National Early Warning Score (NEWS) outside acute hospital settings: a qualitative study of staff experiences in the West of England. BMJ Open. 2018; 8DOI | PubMed
- Inada-Kim M, Nsutebu E. NEWS 2: an opportunity to standardise the management of deterioration and sepsis. BMJ. 2018; 360:k1260. DOI | PubMed
- Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med. 2015; 162:55-63. DOI | PubMed
- Christodoulou E, Ma J, Collins GS, Steyerberg EW, Verbakel JY, Van Calster B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J Clin Epidemiol. 2019; 110:12-22. DOI | PubMed
- Damen JAAG, Hooft L, Schuit E. Prediction models for cardiovascular disease risk in the general population: systematic review. BMJ. 2016; 353:i2416. DOI | PubMed
- Collins GS, Mallett S, Omar O, Yu LM. Developing risk prediction models for type 2 diabetes: a systematic review of methodology and reporting. BMC Med. 2011; 9:103. DOI | PubMed
- Bouwmeester W, Zuithoff NPA, Mallett S. Reporting and methods in clinical prediction research: a systematic review. PLoS Med. 2012; 9:1-12. DOI | PubMed
- Collins GS, Omar O, Shanyinde M, Yu LM. A systematic review finds prediction models for chronic kidney disease were poorly reported and often developed using inappropriate methods. J Clin Epidemiol. 2013; 66:268-77. DOI | PubMed
- Gao H, McDonnell A, Harrison DA. Systematic review and evaluation of physiological track and trigger warning systems for identifying at-risk patients on the ward. Intensive Care Med. 2007; 33:667-79. DOI | PubMed
- Smith MEB, Chiovaro JC, O’Neil M. Early warning system scores for clinical deterioration in hospitalized patients: a systematic review. Ann Am Thorac Soc. 2014; 11:1454-65. DOI | PubMed
- Goldstein BA, Navar AM, Pencina MJ, Ioannidis JPA. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J Am Med Inform Assoc. 2017; 24:198-208. DOI | PubMed
- Goldstein BA, Pomann GM, Winkelmayer WC, Pencina MJ. A comparison of risk prediction methods using repeated observations: an application to electronic health records for hemodialysis. Stat Med. 2017; 36:2750-63. DOI | PubMed
- Churpek MM, Yuen TC, Edelson DP. Predicting clinical deterioration in the hospital: the impact of outcome selection. Resuscitation. 2013; 84:564-8. DOI | PubMed
- Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG. Research electronic data capture (REDCap)–a metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009; 42:377-81. DOI | PubMed
- Moons KGM, de Groot JAH, Bouwmeester W. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLoS Med. 2014; 11DOI | PubMed
- Wolff RF, Moons KGM, Riley RD, PROBAST Group†. PROBAST: a tool to assess the risk of bias and applicability of prediction model studies. Ann Intern Med. 2019; 170:51-8. DOI | PubMed
- Albert BL, Huesman L. Development of a modified early warning score using the electronic medical record. Dimens Crit Care Nurs. 2011; 30:283-92. DOI | PubMed
- Alvarez CA, Clark CA, Zhang S. Predicting out of intensive care unit cardiopulmonary arrest or death using electronic medical record data. BMC Med Inform Decis Mak. 2013; 13:28. DOI | PubMed
- Badriyah T, Briggs JS, Meredith P. Decision-tree early warning score (DTEWS) validates the design of the National Early Warning Score (NEWS). Resuscitation. 2014; 85:418-23. DOI | PubMed
- Bleyer AJ, Vidya S, Russell GB. Longitudinal analysis of one million vital signs in patients in an academic medical center. Resuscitation. 2011; 82:1387-92. DOI | PubMed
- Churpek MM, Yuen TC, Park SY, Gibbons R, Edelson DP. Using electronic health record data to develop and validate a prediction model for adverse outcomes in the wards*. Crit Care Med. 2014; 42:841-8. DOI | PubMed
- Churpek MM, Yuen TC, Winslow C. Multicenter development and validation of a risk stratification tool for ward patients. Am J Respir Crit Care Med. 2014; 190:649-55. DOI | PubMed
- Churpek MM, Adhikari R, Edelson DP. The value of vital sign trends for detecting clinical deterioration on the wards. Resuscitation. 2016; 102:1-5. DOI | PubMed
- Cuthbertson BH, Boroujerdi M, Prescott G. The use of combined physiological parameters in the early recognition of the deteriorating acute medical patient. J R Coll Physicians Edinb. 2010; 40:19-25. DOI | PubMed
- Duckitt RW, Buxton-Thomas R, Walker J. Worthing physiological scoring system: derivation and validation of a physiological early-warning system for medical admissions. An observational, population-based single-centre study. Br J Anaesth. 2007; 98:769-74. DOI | PubMed
- Dziadzko MA, Novotny PJ, Sloan J. Multicenter derivation and validation of an early warning score for acute respiratory failure or death in the hospital. Crit Care. 2018; 22:286. DOI | PubMed
- Escobar GJ, LaGuardia JC, Turk BJ, Ragins A, Kipnis P, Draper D. Early detection of impending physiologic deterioration among patients who are not in intensive care: development of predictive models using data from an automated electronic medical record. J Hosp Med. 2012; 7:388-95. DOI | PubMed
- Faisal M, Scally AJ, Jackson N. Development and validation of a novel computer-aided score to predict the risk of in-hospital mortality for acutely ill medical admissions in two acute hospitals using their first electronically recorded blood test results and vital signs: a cross-sectional study. BMJ Open. 2018; 8DOI | PubMed
- Ghosh E, Eshelman L, Yang L, Carlson E, Lord B. Early Deterioration Indicator: Data-driven approach to detecting deterioration in general ward. Resuscitation. 2018; 122:99-105. DOI | PubMed
- Goldhill DR, McNarry AF. Physiological abnormalities in early warning scores are related to mortality in adult inpatients. Br J Anaesth. 2004; 92:882-4. DOI | PubMed
- Harrison GA, Jacques T, McLaws ML, Kilborn G. Combinations of early signs of critical illness predict in-hospital death-the SOCCER study (signs of critical conditions and emergency responses). Resuscitation. 2006; 71:327-34. DOI | PubMed
- Jones M. NEWSDIG: The National Early Warning Score Development and Implementation Group. Clin Med (Lond). 2012; 12:501-3. DOI | PubMed
- Kellett J, Deane B. The Simple Clinical Score predicts mortality for 30 days after admission to an acute medical unit. QJM. 2006; 99:771-81. DOI | PubMed
- Kellett J, Deane B, Gleeson M. Derivation and validation of a score based on Hypotension, Oxygen saturation, low Temperature, ECG changes and Loss of independence (HOTEL) that predicts early mortality between 15 min and 24 h after admission to an acute medical unit. Resuscitation. 2008; 78:52-8. DOI | PubMed
- Kipnis P, Turk BJ, Wulf DA. Development and validation of an electronic medical record-based alert score for detection of inpatient deterioration outside the ICU. J Biomed Inform. 2016; 64:10-9. DOI | PubMed
- Kirkland LL, Malinchoc M, O’Byrne M. A clinical deterioration prediction tool for internal medicine patients. Am J Med Qual. 2013; 28:135-42. DOI | PubMed
- Kwon JM, Lee Y, Lee Y, Lee S, Park J. An algorithm based on deep learning for predicting in-hospital cardiac arrest. J Am Heart Assoc. 2018; 7:26. DOI | PubMed
- Kyriacos U, Jelsma J, James M, Jordan S. Monitoring vital signs: development of a modified early warning scoring (MEWS) system for general wards in a developing country. PLoS One. 2014; 9DOI | PubMed
- Luís L, Nunes C. Short National Early Warning Score—developing a modified early warning score. Aust Crit Care. 2018; 31:376-81. DOI | PubMed
- Moore CC, Hazard R, Saulters KJ. Derivation and validation of a universal vital assessment (UVA) score: a tool for predicting mortality in adult hospitalised patients in sub-Saharan Africa. BMJ Glob Health. 2017; 2DOI | PubMed
- Nickel CH, Kellett J, Cooksley T, Bingisser R, Henriksen DP, Brabrand M. Combined use of the National Early Warning Score and D-dimer levels to predict 30-day and 365-day mortality in medical patients. Resuscitation. 2016; 106:49-52. DOI | PubMed
- Perera YS, Ranasinghe P, Adikari AM. The value of the Modified Early Warning Score and biochemical parameters as predictors of patient outcome in acute medical admissions a prospective study. Acute Med. 2011; 10:126-32. PubMed
- Prytherch DR, Smith GB, Schmidt PE, Featherstone PI. ViEWS–Towards a national early warning score for detecting adult inpatient deterioration. Resuscitation. 2010; 81:932-7. DOI | PubMed
- Redfern OC, Pimentel MAF, Prytherch D. Predicting in-hospital mortality and unanticipated admissions to the intensive care unit using routinely collected blood tests and vital signs: Development and validation of a multivariable model. Resuscitation. 2018; 133:75-81. DOI | PubMed
- Silke B, Kellett J, Rooney T, Bennett K, O’Riordan D. An improved medical admissions risk system using multivariable fractional polynomial logistic regression modelling. QJM. 2010; 103:23-32. DOI | PubMed
- Tarassenko L, Clifton DA, Pinsky MR, Hravnak MT, Woods JR, Watkinson PJ. Centile-based early warning scores derived from statistical distributions of vital signs. Resuscitation. 2011; 82:1013-8. DOI | PubMed
- Watkinson PJ, Pimentel MAF, Clifton DA, Tarassenko L. Manual centile-based early warning scores derived from statistical distributions of observational vital-sign data. Resuscitation. 2018; 129:55-60. DOI | PubMed
- Wheeler I, Price C, Sitch A. Early warning scores generated in developed healthcare settings are not sufficient at predicting early mortality in Blantyre, Malawi: a prospective cohort study [correction: PLoS One 2014;9:e91623]. PLoS One. 2013; 8DOI | PubMed
- Abbott TEF, Torrance HDT, Cron N, Vaid N, Emmanuel J. A single-centre cohort study of National Early Warning Score (NEWS) and near patient testing in acute medical admissions. Eur J Intern Med. 2016; 35:78-82. DOI | PubMed
- Abbott TE, Vaid N, Ip D. A single-centre observational cohort study of admission National Early Warning Score (NEWS). Resuscitation. 2015; 92:89-93. DOI | PubMed
- Atmaca Ö, Turan C, Güven P, Arıkan H, Eryüksel SE, Karakurt S. Usage of NEWS for prediction of mortality and in-hospital cardiac arrest rates in a Turkish university hospital. Turk J Med Sci. 2018; 48:1087-91. DOI | PubMed
- Bartkowiak B, Snyder AM, Benjamin A. Validating the Electronic Cardiac Arrest Risk Triage (eCART) score for risk stratification of surgical inpatients in the postoperative setting: retrospective cohort study. Ann Surg. 2019; 269:1059-63. DOI | PubMed
- Beane A, De Silva AP, De Silva N. Evaluation of the feasibility and performance of early warning scores to identify patients at risk of adverse outcomes in a low-middle income country setting. BMJ Open. 2018; 8DOI | PubMed
- Brabrand M, Hallas P, Hansen SN, Jensen KM, Madsen JLB, Posth S. Using scores to identify patients at risk of short term mortality at arrival to the acute medical unit: A validation study of six existing scores. Eur J Intern Med. 2017; 45:32-6. DOI | PubMed
- Brabrand M, Henriksen DP. CURB-65 score is equal to NEWS for identifying mortality risk of pneumonia patients: An observational study. Lung. 2018; 196:359-61. DOI | PubMed
- Cei M, Bartolomei C, Mumoli N. In-hospital mortality and morbidity of elderly medical patients can be predicted at admission by the Modified Early Warning Score: a prospective study. Int J Clin Pract. 2009; 63:591-5. DOI | PubMed
- Churpek MM, Snyder A, Sokol S, Pettit NN, Edelson DP. Investigating the impact of different suspicion of infection criteria on the accuracy of quick sepsis-related organ failure assessment, systemic inflammatory response syndrome, and early warning scores. Crit Care Med. 2017; 45:1805-12. DOI | PubMed
- Churpek MM, Snyder A, Han X. Quick sepsis-related organ failure assessment, systemic inflammatory response syndrome, and early warning scores for detecting clinical deterioration in infected patients outside the intensive care unit. Am J Respir Crit Care Med. 2017; 195:906-11. DOI | PubMed
- Churpek MM, Yuen TC, Edelson DP. Risk stratification of hospitalized patients on the wards. Chest. 2013; 143:1758-65. DOI | PubMed
- Churpek MM, Yuen TC, Huber MT, Park SY, Hall JB, Edelson DP. Predicting cardiac arrest on the wards: a nested case-control study. Chest. 2012; 141:1170-6. DOI | PubMed
- Cooksley T, Kitlowski E, Haji-Michael P. Effectiveness of Modified Early Warning Score in predicting outcomes in oncology patients. QJM. 2012; 105:1083-8. DOI | PubMed
- De Meester K, Das T, Hellemans K. Impact of a standardized nurse observation protocol including MEWS after Intensive Care Unit discharge. Resuscitation. 2013; 84:184-8. DOI | PubMed
- DeVoe B, Roth A, Maurer G. Correlation of the predictive ability of early warning metrics and mortality for cardiac arrest patients receiving in-hospital Advanced Cardiovascular Life Support. Heart Lung. 2016; 45:497-502. DOI | PubMed
- Douw G, Huisman-de Waal G, van Zanten ARH, van der Hoeven JG, Schoonhoven L. Capturing early signs of deterioration: the dutch-early-nurse-worry-indicator-score and its value in the Rapid Response System. J Clin Nurs. 2017; 26:2605-13. DOI | PubMed
- Eccles SR, Subbe C, Hancock D, Thomson N. CREWS: improving specificity whilst maintaining sensitivity of the National Early Warning Score in patients with chronic hypoxaemia. Resuscitation. 2014; 85:109-11. DOI | PubMed
- Fairclough E, Cairns E, Hamilton J, Kelly C. Evaluation of a modified early warning system for acute medical admissions and comparison with C-reactive protein/albumin ratio as a predictor of patient outcome. Clin Med (Lond). 2009; 9:30-3. DOI | PubMed
- Finlay GD, Rothman MJ, Smith RA. Measuring the modified early warning score and the Rothman index: advantages of utilizing the electronic medical record in an early warning system. J Hosp Med. 2014; 9:116-9. DOI | PubMed
- Forster S, Housley G, McKeever TM, Shaw DE. Investigating the discriminative value of Early Warning Scores in patients with respiratory disease using a retrospective cohort analysis of admissions to Nottingham University Hospitals Trust over a 2-year period. BMJ Open. 2018; 8DOI | PubMed
- Garcea G, Jackson B, Pattenden CJ. Early warning scores predict outcome in acute pancreatitis. J Gastrointest Surg. 2006; 10:1008-15. DOI | PubMed
- Gardner-Thorpe J, Love N, Wrightson J, Walsh S, Keeling N. The value of Modified Early Warning Score (MEWS) in surgical in-patients: a prospective observational study. Ann R Coll Surg Engl. 2006; 88:571-5. DOI | PubMed
- Ghanem-Zoubi NO, Vardi M, Laor A, Weber G, Bitterman H. Assessment of disease-severity scoring systems for patients with sepsis in general internal medicine departments. Crit Care. 2011; 15:R95. DOI | PubMed
- Green M, Lander H, Snyder A, Hudson P, Churpek M, Edelson D. Comparison of the Between the Flags calling criteria to the MEWS, NEWS and the electronic Cardiac Arrest Risk Triage (eCART) score for the identification of deteriorating ward patients. Resuscitation. 2018; 123:86-91. DOI | PubMed
- Hodgson LE, Dimitrov BD, Congleton J, Venn R, Forni LG, Roderick PJ. A validation of the National Early Warning Score to predict outcome in patients with COPD exacerbation. Thorax. 2017; 72:23-30. DOI | PubMed
- Hydes TJ, Meredith P, Schmidt PE, Smith GB, Prytherch DR, Aspinall RJ. National Early Warning Score accurately discriminates the risk of serious adverse events in patients with liver disease. Clin Gastroenterol Hepatol. 2018; 16:1657-1666.e10. DOI | PubMed
- Jo S, Jeong T, Lee JB, Jin Y, Yoon J, Park B. Validation of modified early warning score using serum lactate level in community-acquired pneumonia patients. The National Early Warning Score-Lactate score. Am J Emerg Med. 2016; 34:536-41. DOI | PubMed
- Kellett J, Kim A. Validation of an abbreviated Vitalpac™ Early Warning Score (ViEWS) in 75,419 consecutive admissions to a Canadian regional hospital. Resuscitation. 2012; 83:297-302. DOI | PubMed
- Kellett J, Murray A. Should predictive scores based on vital signs be used in the same way as those based on laboratory data? A hypothesis generating retrospective evaluation of in-hospital mortality by four different scoring systems. Resuscitation. 2016; 102:94-7. DOI | PubMed
- Kim D, Jo S, Lee JB. Comparison of the National Early Warning Score+Lactate score with the pre-endoscopic Rockall, Glasgow-Blatchford, and AIMS65 scores in patients with upper gastrointestinal bleeding. Clin Exp Emerg Med. 2018; 5:219-29. DOI | PubMed
- Kim WY, Lee J, Lee JR. A risk scoring model based on vital signs and laboratory data predicting transfer to the intensive care unit of patients admitted to gastroenterology wards. J Crit Care. 2017; 40:213-7. DOI | PubMed
- Kovacs C, Jarvis SW, Prytherch DR. Comparison of the National Early Warning Score in non-elective medical and surgical patients. Br J Surg. 2016; 103:1385-93. DOI | PubMed
- Kruisselbrink R, Kwizera A, Crowther M. Modified Early Warning Score (MEWS) identifies critical illness among ward patients in a resource restricted setting in Kampala, Uganda: A prospective observational study. PLoS One. 2016; 11DOI | PubMed
- Le Lagadec MD, Dwyer T, Browne M. The efficacy of twelve early warning systems for potential use in regional medical facilities in Queensland, Australia. Aust Crit Care. 2020; 33:47-53. DOI | PubMed
- Lee YS, Choi JW, Park YH. Evaluation of the efficacy of the National Early Warning Score in predicting in-hospital mortality via the risk stratification. J Crit Care. 2018; 47:222-6. DOI | PubMed
- Liljehult J, Christensen T. Early warning score predicts acute mortality in stroke patients. Acta Neurol Scand. 2016; 133:261-7. DOI | PubMed
- Mulligan A. Validation of a physiological track and trigger score to identify developing critical illness in haematology patients. Intensive Crit Care Nurs. 2010; 26:196-206. DOI | PubMed
- Öhman MC, Atkins TEH, Cooksley T, Brabrand M. Validation of the MARS: a combined physiological and laboratory risk prediction tool for 5- to 7-day in-hospital mortality. QJM. 2018; 111:385-8. DOI | PubMed
- Opio MO, Nansubuga G, Kellett J. Validation of the VitalPAC™ Early Warning Score (ViEWS) in acutely ill medical patients attending a resource-poor hospital in sub-Saharan Africa. Resuscitation. 2013; 84:743-6. DOI | PubMed
- Opio MO, Nansubuga G, Kellett J, Clifford M, Murray A. Performance of TOTAL, in medical patients attending a resource-poor hospital in sub-Saharan Africa and a small Irish rural hospital. Acute Med. 2013; 12:135-40. PubMed
- Pedersen NE, Rasmussen LS, Petersen JA, Gerds TA, Østergaard D, Lippert A. Modifications of the National Early Warning Score for patients with chronic respiratory disease. Acta Anaesthesiol Scand. 2018; 62:242-52. DOI | PubMed
- Pimentel MAF, Redfern OC, Gerry S. A comparison of the ability of the National Early Warning Score and the National Early Warning Score 2 to identify patients at risk of in-hospital mortality: A multi-centre database study. Resuscitation. 2019; 134:147-56. DOI | PubMed
- Plate JD, Peelen LM, Leenen LP, Hietbrink F. Validation of the VitalPAC early warning score at the intermediate care unit. World J Crit Care Med. 2018; 7:39-45. DOI | PubMed
- Redfern OC, Smith GB, Prytherch DR, Meredith P, Inada-Kim M, Schmidt PE. A comparison of the Quick Sequential (sepsis-related) Organ Failure Assessment score and the National Early Warning Score in non-ICU patients with/without infection. Crit Care Med. 2018; 46:1923-33. DOI | PubMed
- Roberts D, Djärv T. Preceding national early warnings scores among in-hospital cardiac arrests and their impact on survival. Am J Emerg Med. 2017; 35:1601-6. DOI | PubMed
- Romero-Brufau S, Morlan BW, Johnson M. Evaluating automated rules for rapid response system alarm triggers in medical and surgical patients. J Hosp Med. 2017; 12:217-23. DOI | PubMed
- Romero-Brufau S, Huddleston JM, Naessens JM. Widely used track and trigger scores: are they ready for automation in practice?. Resuscitation. 2014; 85:549-52. DOI | PubMed
- Rylance J, Baker T, Mushi E, Mashaga D. Use of an early warning score and ability to walk predicts mortality in medical patients admitted to hospitals in Tanzania. Trans R Soc Trop Med Hyg. 2009; 103:790-4. DOI | PubMed
- Smith GB, Prytherch DR, Schmidt PE, Featherstone PI. Review and performance evaluation of aggregate weighted ‘track and trigger’ systems. Resuscitation. 2008; 77:170-9. DOI | PubMed
- Smith GB, Prytherch DR, Meredith P, Schmidt PE, Featherstone PI. The ability of the National Early Warning Score (NEWS) to discriminate patients at risk of early cardiac arrest, unanticipated intensive care unit admission, and death. Resuscitation. 2013; 84:465-70. DOI | PubMed
- Smith GB, Prytherch DR, Jarvis S. A comparison of the ability of the physiologic components of medical emergency team criteria and the U.K. National Early Warning Score to discriminate patients at risk of a range of adverse clinical outcomes. Crit Care Med. 2016; 44:2171-81. DOI | PubMed
- Smith HJ, Pasko DN, Haygood CLW, Boone JD, Harper LM, Straughn JM. Early warning score: An indicator of adverse outcomes in postoperative patients on a gynecologic oncology service. Gynecol Oncol. 2016; 143:105-8. DOI | PubMed
- Spagnolli W, Rigoni M, Torri E, Cozzio S, Vettorato E, Nollo G. Application of the National Early Warning Score (NEWS) as a stratification tool on admission in an Italian acute medical ward: A perspective study. Int J Clin Pract. 2017; 71DOI | PubMed
- Stark AP, Maciel RC, Sheppard W, Sacks G, Hines OJ. An early warning score predicts risk of death after inhospital cardiopulmonary arrest in surgical patients. Am Surg. 2015; 81:916-21. PubMed
- Stræde M, Brabrand M. External validation of the simple clinical score and the HOTEL score, two scores for predicting short-term mortality after admission to an acute medical unit. PLoS One. 2014; 9DOI | PubMed
- Subbe CP, Kruger M, Rutherford P, Gemmel L. Validation of a modified Early Warning Score in medical admissions. QJM. 2001; 94:521-6. DOI | PubMed
- Suppiah A, Malde D, Arab T. The Modified Early Warning Score (MEWS): an instant physiological prognostic indicator of poor outcome in acute pancreatitis. JOP. 2014; 15:569-76. DOI | PubMed
- Tirkkonen J, Olkkola KT, Huhtala H, Tenhunen J, Hoppu S. Medical emergency team activation: performance of conventional dichotomised criteria versus national early warning score. Acta Anaesthesiol Scand. 2014; 58:411-9. DOI | PubMed
- Tirotta D, Gambacorta M, La Regina M. Evaluation of the threshold value for the modified early warning score (MEWS) in medical septic patients: a secondary analysis of an Italian multicentric prospective cohort (SNOOPII study). QJM. 2017; 110:369-73. DOI | PubMed
- Vaughn JL, Kline D, Denlinger NM, Andritsos LA, Exline MC, Walker AR. Predictive performance of early warning scores in acute leukemia patients receiving induction chemotherapy. Leuk Lymphoma. 2018; 59:1498-500. DOI | PubMed
- von Lilienfeld-Toal M, Midgley K, Lieberbach S. Observation-based early warning scores to detect impending critical illness predict in-hospital and overall survival in patients undergoing allogeneic stem cell transplantation. Biol Blood Marrow Transplant. 2007; 13:568-76. DOI | PubMed
- Van Calster B, Wynants L, Verbeek JFM. Reporting and interpreting decision curve analysis: A guide for investigators. Eur Urol. 2018; 74:796-804. DOI | PubMed
- McGaughey J, Alderdice F, Fowler R, Kapila A, Mayhew A, Moutray M. Outreach and Early Warning Systems (EWS) for the prevention of intensive care admission and death of critically ill adult patients on general hospital wards. Cochrane Database Syst Rev. 2007; 3DOI | PubMed
- Alam N, Hobbelink EL, van Tienhoven AJ, van de Ven PM, Jansma EP, Nanayakkara PWB. The impact of the use of the Early Warning Score (EWS) on patient outcomes: a systematic review. Resuscitation. 2014; 85:587-94. DOI | PubMed
- Wong D, Bonnici T, Knight J, Morgan L, Coombes P, Watkinson P. SEND: a system for electronic notification and documentation of vital sign observations. BMC Med Inform Decis Mak. 2015; 15:68. DOI | PubMed
- Collins GS, Ogundimu EO, Altman DG. Sample size considerations for the external validation of a multivariable prognostic model: a resampling study. Stat Med. 2016; 35:214-26. DOI | PubMed
- Riley RD, Snell KI, Ensor J. Minimum sample size for developing a multivariable prediction model: PART II – binary and time-to-event outcomes [correction in: Stat Med 2019;38:5672]. Stat Med. 2019; 38:1276-96. DOI | PubMed
- van Smeden M, Moons KGM, de Groot JAH. Sample size for binary logistic prediction models: Beyond events per variable criteria. Stat Methods Med Res. 2019; 28:2455-74. DOI | PubMed
- Little RJA. Regression with missing X’s: a review. J Am Stat Assoc. 1992; 87:1227. DOI
- Janssen KJ, Donders ART, Harrell FE. Missing covariate data in medical research: to impute is better than to ignore. J Clin Epidemiol. 2010; 63:721-7. DOI | PubMed
- Ambler G, Omar RZ, Royston P. A comparison of imputation techniques for handling missing predictor values in a risk model with a binary outcome. Stat Methods Med Res. 2007; 16:277-98. DOI | PubMed
- Little RJA, Rubin DB. Statistical analysis with missing data.. John Wiley & Sons, Inc; 2002. DOI
- Vergouwe Y, Royston P, Moons KG, Altman DG. Development and validation of a prediction model with missing predictor data: a practical approach. J Clin Epidemiol. 2010; 63:205-14. DOI | PubMed
- White IR, Royston P, Wood AM. Multiple imputation using chained equations: Issues and guidance for practice. Stat Med. 2011; 30:377-99. DOI | PubMed
- Wolbers M, Koller MT, Witteman JCM, Steyerberg EW. Prognostic models with competing risks: methods and application to coronary risk prediction. Epidemiology. 2009; 20:555-61. DOI | PubMed
- Gerds TA, Scheike TH, Andersen PK. Absolute risk regression for competing risks: interpretation, link functions, and prediction. Stat Med. 2012; 31:3921-30. DOI | PubMed
- Wolbers M, Koller MT, Stel VS. Competing risks analyses: objectives and approaches. Eur Heart J. 2014; 35:2936-41. DOI | PubMed
- Austin PC, Lee DS, Fine JP. Introduction to the analysis of survival data in the presence of competing risks. Circulation. 2016; 133:601-9. DOI | PubMed
- Blanche P, Dartigues J-F, Jacqmin-Gadda H. Estimating and comparing time-dependent areas under receiver operating characteristic curves for censored event times with competing risks. Stat Med. 2013; 32:5381-97. DOI | PubMed
- Austin PC, Lee DS, D’Agostino RB, Fine JP. Developing points-based risk-scoring systems in the presence of competing risks [correction in: Stat Med 2018;37:1405]. Stat Med. 2016; 35:4056-72. DOI | PubMed
- Gerds TA, Andersen PK, Kattan MW. Calibration plots for risk prediction models in the presence of competing risks. Stat Med. 2014; 33:3191-203. DOI | PubMed
- Steyerberg EW, Harrell FE, Borsboom GJ, Eijkemans MJC, Vergouwe Y, Habbema JDF. Internal validation of predictive models: efficiency of some procedures for logistic regression analysis. J Clin Epidemiol. 2001; 54:774-81. DOI | PubMed
- Moons KG, Altman DG, Reitsma JB. Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015; 162:W1-73. DOI | PubMed
- Harrell FE, Lee KL, Mark DB. Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med. 1996; 15:361-87. DOI | PubMed
- Steyerberg EW, Borsboom GJJM, van Houwelingen HC, Eijkemans MJC, Habbema JDF. Validation and updating of predictive logistic regression models: a study on sample size and shrinkage. Stat Med. 2004; 23:2567-86. DOI | PubMed
- Van Calster B, Nieboer D, Vergouwe Y, De Cock B, Pencina MJ, Steyerberg EW. A calibration hierarchy for risk models was defined: from utopia to empirical data. J Clin Epidemiol. 2016; 74:167-76. DOI | PubMed
- Perel P, Edwards P, Wentz R, Roberts I. Systematic review of prognostic models in traumatic brain injury. BMC Med Inform Decis Mak. 2006; 6:38. DOI | PubMed
- Meads C, Ahmed I, Riley RD. A systematic review of breast cancer incidence risk prediction models with meta-analysis of their performance. Breast Cancer Res Treat. 2012; 132:365-77. DOI | PubMed
- Austin PC, Steyerberg EW. Graphical assessment of internal and external calibration of logistic regression models by using loess smoothers. Stat Med. 2014; 33:517-35. DOI | PubMed
- Steyerberg EW, Vickers AJ, Cook NR. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology. 2010; 21:128-38. DOI | PubMed
- Wynants L, Kent DM, Timmerman D, Lundquist CM, Van Calster B. Untapped potential of multicenter studies: a review of cardiovascular risk prediction models revealed inappropriate analyses and wide variation in reporting. Diagn Progn Res. 2019; 3:6. DOI | PubMed
- Linnen DT, Escobar GJ, Hu X, Scruth E, Liu V, Stephens C. Statistical modeling and aggregate-weighted scoring systems in prediction of mortality and ICU transfer: a systematic review. J Hosp Med. 2019; 14:161-9. DOI | PubMed
- Publisher Full Text
Fonte
Gerry S, Bonnici T, Birks J, Kirtley S, Virdee PS, et al. (2020) Early warning scores for detecting deterioration in adult hospital patients: systematic review and critical appraisal of methodology. The BMJ 369m1501. https://doi.org/10.1136/bmj.m1501




