
Background
La medicina basata sull’evidenza (EBM) si basa sull’idea di sfruttare l’insieme delle prove disponibili per informare la cura del paziente. Purtroppo, questo è un obiettivo impegnativo da realizzare nella pratica, per alcuni motivi. In primo luogo, le prove rilevanti sono diffuse principalmente in articoli non strutturati e in linguaggio naturale che descrivono la condotta e i risultati degli studi clinici. In secondo luogo, l’insieme di tali articoli è già massiccio e continua ad espandersi rapidamente[1].
Una stima ormai superata del 1999 suggerisce che la conduzione di una singola revisione richiede più di 1000 ore di lavoro manuale (altamente qualificato) [2]. Stime di lavoro più recenti stimano che la conduzione di una revisione richiede attualmente, in media, 67 settimane dalla registrazione alla pubblicazione [3]. Chiaramente, i processi esistenti non sono sostenibili: le revisioni delle prove attuali non possono essere prodotte in modo efficiente[4] e in ogni caso spesso si esauriscono rapidamente una volta pubblicate. Il problema fondamentale è che gli attuali metodi EBM, pur essendo rigorosi, semplicemente non sono in grado di soddisfare le richieste imposte dalla voluminosa scala della base di prove (non strutturata). Questo problema è stato discusso a lungo altrove[5-8].
La ricerca sui metodi per le revisioni sistematiche semiautomatiche attraverso l’apprendimento automatico e l’elaborazione del linguaggio naturale costituisce ora un proprio (piccolo) sottocampo, con un lavoro di accompagnamento. In questa indagine, il nostro obiettivo è quello di fornire un’introduzione delicata alle tecnologie di automazione per gli scienziati non informatici. Descriviamo lo stato attuale della scienza e forniamo una guida pratica su quali metodi riteniamo siano pronti per l’uso. Discutiamo anche di come un team di revisione sistematica potrebbe utilizzarli, e dei punti di forza e dei limiti di ciascuno di essi. Non tentiamo una revisione esaustiva della ricerca in questo campo in piena espansione. Forse non sorprende che esistano già diverse revisioni sistematiche di tali sforzi[9, 10].
Abbiamo invece identificato i sistemi di machine learning che sono disponibili per l’uso pratico al momento della scrittura, attraverso lo screening manuale delle registrazioni in SR Toolbox1 del 3 gennaio 2019, per identificare tutti gli strumenti di revisione sistematica che incorporano il machine learning[11]. SR Toolbox è un catalogo online di strumenti software disponibili al pubblico per aiutare la produzione di revisioni sistematiche ed è regolarmente aggiornato attraverso la regolare sorveglianza della letteratura e la presentazione diretta da parte degli sviluppatori di strumenti e attraverso i social media. Non abbiamo descritto i metodi di machine learning da documenti accademici a meno che non sia stato messo a disposizione un sistema per metterli in pratica; allo stesso modo non abbiamo descritto (il grandissimo numero di) strumenti software per facilitare le revisioni sistematiche a meno che non facciano uso di machine learning.
Box 1 Glossario dei termini usati nella revisione sistematica automationMachinelearning: algoritmi informatici che ‘imparano’ ad eseguire un compito specifico attraverso la modellazione statistica di (tipicamente grandi quantità di) dati Elaborazione del linguaggio naturale: metodi di calcolo per l’elaborazione e l’analisi automatica del ‘naturale’ (ad es. Testi in lingua umana) testiTesto classificazione: categorizzazione automatica dei documenti in gruppi di interesse Estrazione dei dati: il compito di identificare i bit chiave di informazioni strutturate dai testiCrowd-sourcing: scomposizione del lavoro in microcompiti da eseguire da parte di lavoratori distribuitiMicro-compiti: unità di lavoro discrete che insieme completano una più grande impresaSemi-automazione: Utilizzo dell’apprendimento automatico per accelerare i compiti, piuttosto che completarliUomo nel ciclo: flussi di lavoro in cui gli esseri umani rimangono coinvolti, piuttosto che essere sostituitiApprendimento supervisionato: stima dei parametri del modello utilizzando dati etichettati manualmenteDistintamente supervisionato: apprendimento da pseudo, rumorose “etichette” derivate automaticamente applicando regole a database esistenti o altri dati strutturatiUnsupervisionato: apprendimento senza alcuna etichetta (e.g. dati di clustering)
Apprendimento automatico e metodi di elaborazione del linguaggio naturale: un’introduzione
Classificazione del testo ed estrazione dei dati: i compiti principali per i revisori
Le tecnologie di base per l’elaborazione del linguaggio naturale (PNL) utilizzate nelle revisioni sistematiche sono la classificazione dei testi e l’estrazione dei dati. La classificazione del testo riguarda modelli che possono ordinare automaticamente i documenti (in questo caso, abstract di articoli, testi completi o parti di testo all’interno di questi) in categorie di interesse predefinite (ad es. rapporto di RCT vs. non). I modelli di estrazione dei dati cercano di identificare frammenti di testo o singole parole/numeri che corrispondono a una particolare variabile di interesse (ad esempio, estraendo il numero di persone randomizzate da un rapporto di uno studio clinico).
L’esempio più importante di classificazione del testo nella pipeline di revisione è lo screening astratto: determinare se i singoli articoli all’interno di un insieme di candidati soddisfano i criteri di inclusione per una particolare revisione sulla base dei loro abstract (e successivamente dei testi completi). In pratica, molti sistemi di machine learning possono inoltre stimare la probabilità che un documento venga incluso (piuttosto che una decisione di inclusione/esclusione binaria). Queste probabilità possono essere utilizzate per classificare automaticamente i documenti dalla maggior parte a quelli meno rilevanti, permettendo così potenzialmente al revisore umano di identificare gli studi da includere molto prima nel processo di screening.
Dopo lo screening, i revisori estraggono gli elementi di dati che sono rilevanti per la loro revisione. Questi sono naturalmente considerati come attività di estrazione di dati individuali. I dati di interesse possono includere dati numerici come le dimensioni del campione di studio e i rapporti di probabilità, così come dati testuali, ad esempio frammenti di testo che descrivono la procedura di randomizzazione dello studio o la popolazione dello studio.
Ilrischio di valutazionedel bias è interessante in quanto comporta sia un compito di estrazione dei dati (identificazione di frammenti di testo nell’articolo come rilevanti per la valutazione del bias) sia una classificazione finale di un articolo come ad alto o basso rischio per ogni tipo di bias valutato[12].
Metodi all’avanguardia sia per la classificazione del testo che per l’estrazione dei dati utilizzano tecniche di machine learning (ML), piuttosto che, ad esempio, metodi basati su regole. In ML, si scrivono programmi che specificano modelli parametrizzati per eseguire particolari compiti; questi parametri sono poi stimati usando set di dati (idealmente grandi). In pratica, i metodi ML assomigliano ai modelli statistici utilizzati nella ricerca epidemiologica (ad esempio, la regressione logistica è un metodo comune in entrambe le discipline).
Mostriamo un semplice esempio di come l’apprendimento meccanico potrebbe essere utilizzato per automatizzare la classificazione degli articoli come RCT o meno nella Fig. 1. In primo luogo, si ottiene un insieme di documenti di formazione. Questo set sarà etichettato manualmente per la variabile di interesse (ad esempio come ‘studio incluso’ o ‘studio escluso’).Fig. 1Classificare il testo usando il machine learning, in questo esempio regressione logistica con una rappresentazione ‘borsa di parole’ dei testi. Il sistema è ‘addestrato’, imparando un coefficiente (o peso) per ogni singola parola in un insieme di documenti etichettati manualmente (tipicamente negli anni 1000). In uso, i coefficienti appresi sono utilizzati per prevedere una probabilità per un documento sconosciuto
Successivamente, i documenti vengono vettorializzati, cioè trasformati in punti ad alta dimensione che sono rappresentati da sequenze di numeri. Una rappresentazione semplice e comune è nota come sacchetto di parole (vedi Fig. 2). In questo approccio, viene costruita una matrice in cui le righe sono documenti e ogni colonna corrisponde ad una parola unica. I documenti possono quindi essere rappresentati nelle righe da 1 e 0, indicando rispettivamente la presenza o l’assenza di ogni parola.2 La matrice risultante sarà rada (cioè costituita per lo più da 0 e relativamente pochi 1), in quanto ogni singolo documento conterrà una piccola frazione del vocabolario completo.3Fig. 2Bag di modellizzazione delle parole per la classificazione degli RCT. In alto a sinistra: Esempio di sacchetto di parole per tre articoli. Ogni colonna rappresenta una parola unica nel corpus (un esempio reale conterrebbe probabilmente colonne per 10.000 parole). In alto a destra: Etichette del documento, dove 1 = rilevante e 0 = irrilevante. In basso: I coefficienti (o pesi) sono stimati per ogni parola (in questo esempio usando la regressione logistica). In questo esempio, pesi alti +ve aumenteranno la probabilità prevista che un articolo non visto sia un RCT dove contiene le parole “casuale” o “randomizzato”. La presenza della parola “sistematico” (con un grande peso negativo) ridurrebbe la probabilità prevista che un documento non visto sia un RCT
Successivamente, i pesi (o coefficienti) per ogni parola sono “appresi” (stimati) dal set di allenamento. Intuitivamente per questo compito, vogliamo imparare quali parole rendono un documento più o meno probabile che sia un RCT. Le parole che riducono la probabilità di essere un RCT dovrebbero avere pesi negativi; quelle che aumentano la probabilità (come “casuale” o “a caso”) dovrebbero avere pesi positivi. Nel nostro esempio corrente, i coefficienti del modello corrispondono ai parametri di un modello di regressione logistica. Questi sono tipicamente stimati (“appresi”) attraverso metodi basati sulla discesa a gradiente.
Una volta che i coefficienti sono appresi, possono essere facilmente applicati ad un nuovo documento non etichettato per prevedere l’etichetta. Il nuovo documento è vettorizzato in modo identico ai documenti di formazione. Il vettore del documento viene poi moltiplicato4 per i coefficienti precedentemente appresi e trasformato in una probabilità attraverso la funzione sigmoide.
Molti sistemi all’avanguardia utilizzano modelli più complessi della regressione logistica (e in particolare metodi più sofisticati per rappresentare i documenti[13], ottenere coefficienti[14], o entrambi[15]). Gli approcci basati sulle reti neurali, in particolare, sono riemersi come classe di modelli dominante. Tali modelli sono composti da più livelli, ciascuno con il proprio set di parametri. Non descriviamo qui in dettaglio questimetodi5 , ma il principio generale è lo stesso: i modelli sono appresi da rappresentazioni numeriche di documenti con etichette note, e poi, questi modelli possono essere applicati a nuovi documenti per prevedere l’etichetta. In generale, questi metodi più complessi ottengono miglioramenti (spesso modesti) nella precisione predittiva rispetto alla regressione logistica, a scapito della complessità computazionale e metodologica.
I metodi per l’estrazione automatica (o semi-automatica) dei dati sono stati ben esplorati, ma per l’uso pratico rimangono meno maturi delle tecnologie di screening automatizzato. Tali sistemi tipicamente operano sia su abstract che su articoli a testo completo e mirano ad estrarre un insieme definito di variabili dal documento.
Nella sua accezione più elementare, l’estrazione dei dati può essere vista come un tipo di problema di classificazione del testo, in cui le singole parole (note come token) sono classificate come rilevanti o meno all’interno di un documento. Piuttosto che tradurre l’intero documento in un vettore, un sistema di estrazione dati potrebbe codificare la parola stessa, più informazioni contestuali aggiuntive (per esempio, parole circostanti e posizione nel documento).
Data una tale rappresentazione vettoriale della parola nella posizione t nel documento x ( annotata come xt), un sistema di estrazione dovrebbe emettere un’etichetta che indichi se questa parola appartiene o meno ad un tipo di dati di interesse (cioè qualcosa da estrarre). Per esempio, potremmo voler estrarre le dimensioni del campione di studio. Ciò può comportare la conversione di numeri scritti in inglese in numeri e quindi l’etichettatura (o “tagging”) di tutti i numeri sulla base di vettori di caratteristiche che codificano proprietà che potrebbero essere utili per fare questa previsione (ad esempio il valore del numero, le parole che lo precedono e lo seguono, e così via). Questo è rappresentato nella Fig. 3. Qui, il token ‘target’ (‘100’) è etichettato come 1, ed altri come 0.Fig. 3Schemamatic di un tipico processo di estrazione dati. L’illustrazione di cui sopra riguarda il compito di esempio di estrazione della dimensione del campione di studio. In generale, questi compiti comportano l’etichettatura di singole parole. La parola (o ‘token’) nella posizione t è rappresentata da un vettore. Questa rappresentazione può codificare quale parola si trova in questa posizione e probabilmente comunica anche caratteristiche aggiuntive, ad esempio se la parola è maiuscola o se la parola è (si deduce che sia) un sostantivo. I modelli per questo tipo di attività tentano di assegnare le etichette a tutte le parole T in un documento e per alcune attività tenteranno di massimizzare la probabilità congiunta di queste etichette di mettere in maiuscolo le correlazioni tra etichette adiacenti
Un tale approccio di classificazione “gettone per gettone” spesso non riesce a capitalizzare la natura intrinsecamente strutturata del linguaggio e dei documenti. Per esempio, si consideri un modello per l’estrazione di frammenti di testo che descrivono rispettivamente la popolazione dello studio, gli interventi/comparatori e i risultati (cioè gli elementi PICO). Etichettare le parole indipendentemente l’una dall’altra non terrebbe conto dell’osservazione che le parole adiacenti avranno la tendenza a condividere le designazioni: se la parola nella posizione t fa parte di una descrizione della popolazione dello studio, ciò aumenta sostanzialmente le probabilità che anche la parola nella posizione t + 1 lo sia.
Nella nomenclatura ML, questo è indicato come un problema di classificazione strutturato. Più precisamente, l’assegnazione delle parole in un testo alle categorie è un’istanza di etichettatura in sequenza. Sono stati sviluppati molti modelli per problemi con questa struttura. Il campo casuale condizionale (CRF) è tra i più importanti di questi[18]. Gli attuali modelli allo stato dell’arte sono basati su reti neurali, e in particolare su reti neurali ricorrenti, o RNN. Le reti a memoria lunga a breve termine (LSTM)[19] combinate con le CRF (LSTM-CRF)[19- 21] hanno in particolare mostrato prestazioni convincenti su tali compiti in generale, per l’estrazione di dati da RCT in particolare [22,23].
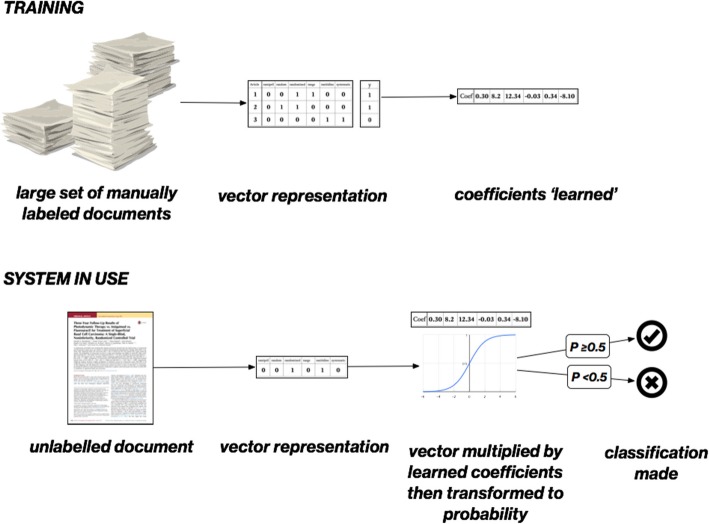
Fig. 1.Fig. 1. Classificazione dei testi mediante l’apprendimento automatico, in questo esempio regressione logistica con una rappresentazione “a sacchetto di parole” dei testi. Il sistema è ‘addestrato’, imparando un coefficiente (o peso) per ogni singola parola in un insieme di documenti etichettati manualmente (tipicamente negli anni 1000). In uso, i coefficienti appresi sono utilizzati per prevedere una probabilità per un documento sconosciuto

Fig. 2.Sacchetto di parole di modellazione per la classificazione degli RCT. In alto a sinistra: Esempio di sacchetto di parole per tre articoli. Ogni colonna rappresenta una parola unica nel corpus (un esempio reale conterrebbe probabilmente colonne per 10.000 parole). In alto a destra: Etichette del documento, dove 1 = rilevante e 0 = irrilevante. In basso: I coefficienti (o pesi) sono stimati per ogni parola (in questo esempio usando la regressione logistica). In questo esempio, pesi alti +ve aumenteranno la probabilità prevista che un articolo non visto sia un RCT dove contiene le parole “casuale” o “randomizzato”. La presenza della parola “sistematico” (con un grande peso negativo) ridurrebbe la probabilità prevista che un documento non visto sia un RCT
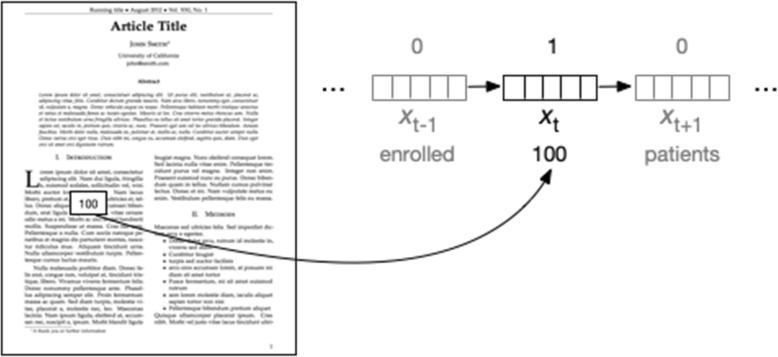
Fig. 3.Schema di un tipico processo di estrazione dati. L’illustrazione di cui sopra riguarda il compito di esempio dell’estrazione della dimensione del campione di studio. In generale, questi compiti comportano l’etichettatura di singole parole. La parola (o ‘token’) nella posizione t è rappresentata da un vettore. Questa rappresentazione può codificare quale parola si trova in questa posizione e probabilmente comunica anche caratteristiche aggiuntive, ad esempio se la parola è maiuscola o se la parola è (si deduce che sia) un sostantivo. I modelli per questo tipo di attività tentano di assegnare le etichette a tutte le parole T in un documento e per alcune attività tenteranno di massimizzare la probabilità congiunta di queste etichette di mettere in maiuscolo le correlazioni tra etichette adiacenti
Strumenti per l’apprendimento della macchina disponibili per l’uso pratico
Ricerca
La letteratura biomedica in rapida espansione ha reso la ricerca un obiettivo interessante per l’automazione. Finora sono stati studiati due settori chiave: il filtraggio degli articoli in base alla progettazione dello studio e la ricerca automatica di articoli rilevanti per argomento. I sistemi di classificazione testuale per l’identificazione degli RCT sono i più maturi e li consideriamo pronti per l’uso nella pratica. L’apprendimento automatico per l’identificazione degli RCT è già stato implementato in Cochrane; gli autori Cochrane possono accedere a questa tecnologia attraverso il Cochrane Register of Studies[24].6
Due sistemi convalidati sono liberamente disponibili per uso generale[16, 25]. Cohen e colleghi hanno rilasciato RCT tagger,7 un sistema che stima la probabilità che gli articoli PubMed siano RCT[25]. Il team ha convalidato le prestazioni su una porzione trattenuta dello stesso set di dati, trovando il sistema discriminato accuratamente tra RCT e non RCT (area sotto la curva delle caratteristiche operative del ricevitore (AUROC) = 0,973). Un portale di ricerca è disponibile gratuitamente sul loro sito web, che permette all’utente di selezionare una soglia di confidenza per la sua ricerca.
Il nostro team ha prodotto RobotSearch8, che mira a sostituire il filtraggio degli studi basati sulle parole chiave. Il sistema utilizza reti neurali e macchine vettoriali di supporto, ed è stato addestrato su un ampio set di articoli con etichette provenienti dalla folla da parte di Cochrane Crowd[16]. Il sistema è stato validato su e ha raggiunto lo stato dell’arte delle prestazioni discriminanti (AUROC = 0,987), riducendo il numero di articoli irrilevanti recuperati di circa la metà rispetto alla Cochrane Highly Sensitive Search Strategy basata su parole chiave, senza perdere alcun RCT aggiuntivo. Il sistema può essere utilizzato liberamente caricando un file RIS sul nostro sito web; viene poi restituito un file filtrato contenente solo gli RCT.
La classificazione del design dello studio è interessante per l’apprendimento automatico perché è un compito unico e generalizzabile: il filtraggio degli RCT è comune in molte revisioni sistematiche. Tuttavia, trovare articoli che soddisfino altri criteri di inclusione specifici per l’argomento è specifico per la revisione e quindi molto più difficile – si consideri che è improbabile che una revisione sistematica con criteri di inclusione identici sia stata eseguita prima, e anche dove lo è stata, potrebbe produrre fino a diverse dozzine di articoli per utilizzare un dato di formazione, rispetto alle migliaia necessarie in un tipico sistema di machine learning. Discutiamo di come una piccola serie di articoli rilevanti (tipicamente ottenuti attraverso lo screening di una parte degli abstract recuperati da una particolare ricerca) possa seminare un sistema di machine learning per identificare altri articoli rilevanti qui di seguito.
Un’ulteriore applicazione del machine learning nella ricerca è come metodo per produrre un motore di ricerca semantico, cioè uno in cui l’utente può cercare per concetto piuttosto che per parola chiave. Un tale sistema è simile alla ricerca PubMed per termini MeSH (termini indice di un vocabolario standardizzato, che sono stati tradizionalmente applicati manualmente dal personale PubMed). Tuttavia, un tale approccio manuale ha l’ovvio inconveniente di richiedere un ampio e continuo sforzo di annotazione manuale, soprattutto alla luce del volume esponenzialmente crescente di articoli da indicizzare. Anche mettendo da parte i costi, l’annotazione manuale ritarda il processo di indicizzazione, il che significa che gli articoli più recenti potrebbero non essere recuperabili. Thalia è un sistema di apprendimento automatico (basato sui CRF, rivisto sopra) che indicizza automaticamente i nuovi articoli PubMed quotidianamente per le sostanze chimiche, le malattie, i farmaci, i geni, i metaboliti, le proteine, le specie e le entità anatomiche. Questo permette di aggiornare quotidianamente gli indici e fornisce un’interfaccia utente per interagire con i concetti individuati[26].
Infatti, a partire dall’ottobre 2018, PubMed stessa ha adottato un approccio ibrido, in cui ad alcuni articoli vengono assegnati automaticamente i termini MeSH utilizzando il sistema Medical Text Indexer (MTI)[27], che utilizza una combinazione di apprendimento automatico e regole create manualmente per assegnare i termini senza l’intervento umano[28].
Screening
I sistemi di apprendimento a macchina per lo screening astratto hanno raggiunto la maturità; diversi sistemi di questo tipo con alti livelli di precisione sono disponibili per i revisori. In tutti i sistemi disponibili, i revisori umani devono prima esaminare una serie di abstract e poi rivedere le raccomandazioni del sistema. Tali sistemi sono quindi semi-automatici, cioè mantengono gli esseri umani “in loop”. Mostriamo un tipico flusso di lavoro in Fig. 4.Fig. 4Il flusso di lavoro tipico per lo screening astratto semi-automatico. L’asterisco indica che con il campionamento di incertezza, gli articoli che sono previsti con meno certezza sono presentati per primi. Ciò mira a migliorare l’accuratezza del modello in modo più efficiente
Dopo aver effettuato una ricerca convenzionale, gli abstract recuperati vengono caricati nel sistema (ad esempio utilizzando il comune formato di citazione RIS). Successivamente, un revisore umano analizza manualmente un campione (spesso casuale) dell’insieme recuperato. Ciò continua fino a quando non viene identificato un numero “sufficiente” di articoli rilevanti, in modo da poter formare un classificatore di testo. (Esattamente quanti esempi positivi saranno sufficienti per ottenere una buona performance predittiva è una questione empirica, ma un euristico conservativo è circa la metà del set recuperato). Il sistema usa questo classificatore per prevedere la rilevanza di tutti gli abstract non schermati, e questi sono riordinati per rango. Il revisore umano viene quindi presentato per primo con gli articoli più rilevanti. Questo ciclo continua poi, con i documenti che vengono ripetutamente ri-assegnati come abstract aggiuntivi che vengono controllati manualmente, fino a quando il revisore umano non si accerta che non vengano controllati altri articoli rilevanti.
Questa è una variante dell’apprendimento attivo (AL)[29]. Negli approcci AL, il modello seleziona quali istanze devono essere etichettate successivamente, con l’obiettivo di massimizzare il rendimento predittivo con una supervisione umana minima. Qui abbiamo delineato un criterio di AL basato sulla certezza, in cui il modello dà priorità alle citazioni di etichettatura che ritiene rilevanti (secondo i suoi attuali parametri del modello). Questo approccio di AL è appropriato per lo scenario di revisione sistematica, alla luce del numero relativamente piccolo di abstract rilevanti che esisteranno in un dato set in esame. Tuttavia, un approccio più standard e generale è il campionamento dell’incertezza, in cui il modello chiede all’essere umano di etichettare le istanze di cui è meno certo.
Il limite fondamentale dello screening astratto automatizzato è che non è chiaro a che punto sia “sicuro” per il revisore interrompere lo screening manuale. Inoltre, questo punto varia da una recensione all’altra. I sistemi di screening tendono a classificare gli articoli in base alla probabilità di rilevanza, piuttosto che fornire semplicemente classificazioni definitive e dicotomizzate. Tuttavia, anche gli articoli con una classificazione bassa hanno una probabilità non nulla di essere rilevanti, e rimane la possibilità di perdere un articolo rilevante fermandosi troppo presto. (Vale la pena notare che tutte le citazioni non recuperate attraverso qualsiasi strategia di ricerca iniziale vengano utilizzate per recuperare il pool di articoli candidati implicitamente assegnano una probabilità pari a zero a tutti gli altri abstract; questa ipotesi forte e probabilmente ingiustificata viene spesso trascurata). Gli studi empirici hanno trovato che il punto di arresto ottimale può variare sostanzialmente tra le diverse revisioni; sfortunatamente, il punto di arresto ottimale può essere determinato definitivamente solo in retrospettiva, una volta che tutti gli abstract sono stati vagliati. I sistemi attualmente disponibili includono Abstrackr[30], SWIFT-Review,9 EPPI reviewer[31], e RobotAnalyst[32] (vedi Tabella 1).Tabella 1 Esempi di sistemi di machine learning disponibili per l’uso in revisioni sistematicheEsempio di strumentiCommentiRicercaRicerca RCTsRobotSearch(https://robotsearch.vortext.systems)Cochrane Register of Studies(https://community.cochrane.org/help/tools-and-software/crs-cochrane-register-studies)RCT tagger (http://arrowsmith.psych.uic.edu/cgi-bin/arrowsmith_uic/RCT_Tagger.cgi)- Filtri convalidati di machine learning disponibili per l’identificazione degli RCT e adatti all’uso completamente automatico- Strategia convenzionale di ricerca per parole chiave specifiche per argomento ancora necessaria- Non ci sono strumenti ampiamente disponibili per la progettazione non RCT attualmenteSearch-literature explorationThalia(http://nactem-copious.man.ac.uk/Thalia/)Consente la ricerca di PubMed per concetti (es. sostanze chimiche, malattie, farmaci, geni, metaboliti, proteine, specie ed entità anatomiche)ScreeningAbstrackr(http://abstrackr.cebm.brown.edu)[30]EPPI reviewer (https://eppi.ioe.ac.uk/cms/er4)[31]RobotAnalyst (http://www.nactem.ac.uk/robotanalyst/)[32]SWIFT-Review(https://www.sciome.com/swift-review/)Colandr(https://www.colandrapp.com)Rayyan(https://rayyan.qcri.org)- I sistemi di screening ordinano automaticamente una ricerca in base alla rilevanza – RobotAnalyst eSWIFT-Review consentono anche la modellazione degli argomenti, dove gli abstract relativi ad argomenti simili sono raggruppati automaticamente, permettendo all’utente di esplorare la ricerca.sistemi)NaCTeM text mining tools per l’estrazione automatica di concetti relativi a geni e proteine (NEMine), metaboliti del lievito (Yeast MetaboliNER) ed entità anatomiche (AnatomyTagger)(http://www.nactem.ac.uk/software.php)- Questi sistemi prototipo estraggono automaticamente elementi di dati (ad es. dimensioni del campione, descrizioni di elementi PICO) da testi liberi.Bias assessmentRobotReviewer(https://robotreviewer.vortext.systems)- Valutazione automatica dei pregiudizi nei rapporti di RCTs- Sistema raccomandato per l’uso semi-automatico ( cioè con revisore umano che controlla e corregge i suggerimenti ML)
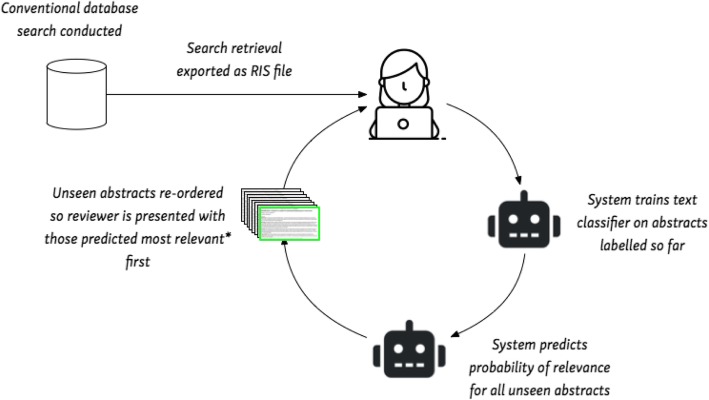
Fig. 4.Tipico flusso di lavoro per la vagliatura astratta semiautomatica. L’asterisco indica che con il campionamento ad incertezza, gli articoli che sono previsti con meno certezza vengono presentati per primi. Ciò mira a migliorare l’accuratezza del modello in modo più efficiente
Estrazione dei dati
Ci sono state ora molte applicazioni di estrazione di dati a supporto delle revisioni sistematiche; per un’indagine relativamente recente su queste, si veda[9]. Tuttavia, nonostante i progressi, le tecnologie di estrazione rimangono in fase di formazione e non sono facilmente accessibili ai professionisti. Per le revisioni sistematiche degli RCT, esistono solo poche piattaforme prototipo che rendono disponibili tali tecnologie (ExaCT[33] e RobotReviewer[12, 34, 35] sono tra queste). Per le revisioni sistematiche nelle scienze di base, il National Centre for Text Mining del Regno Unito (NaCTeM) ha creato una serie di sistemi che utilizzano modelli strutturati per estrarre automaticamente concetti che includono geni e proteine, lieviti ed entità anatomiche [36],tra gli altri strumenti di text mining basati su ML.10
ExaCT e RobotReviewer funzionano in modo simile. I sistemi sono addestrati su articoli a testo completo, con frasi etichettate manualmente11 come pertinenti (o meno) alle caratteristiche degli studi. In pratica, entrambi i sistemi sovra-rilevano le frasi dei candidati (ad esempio, ExaCT recupera le cinque frasi previste più probabilmente, quando le informazioni rilevanti risiedono generalmente in una sola di esse). Lo scopo di questo comportamento è quello di massimizzare la probabilità che almeno una delle frasi sia rilevante. Così, in pratica, entrambi i sistemi sarebbero probabilmente utilizzati in modo semiautomatico da un revisore umano. Il revisore leggerà le frasi candidate, sceglierà quelle rilevanti o consulterà il testo integrale nel caso in cui non sia stato identificato alcun testo rilevante.
ExaCT utilizza i rapporti RCT in formato HTML ed è progettato per recuperare 21 caratteristiche relative alla progettazione dello studio e ai rapporti sulla base dei criteri CONSORT. ExaCT contiene inoltre una serie di regole per identificare le parole o le frasi all’interno di una frase che descrivono la caratteristica di interesse. Nella loro valutazione, il team di ExaCT ha trovato che il loro sistema aveva un richiamo molto elevato (dal 72% al 100% per le diverse variabili raccolte) quando sono state recuperate le 5 frasi più probabili.
RobotReviewer prende i rapporti RCT in formato PDF e recupera automaticamente le frasi che descrivono il PICO (la popolazione, l’intervento, il comparatore e gli esiti), e anche il testo che descrive la condotta di prova rilevante per i pregiudizi (compresa l’adeguatezza della generazione di sequenze casuali, l’occultamento dell’assegnazione e l’accecamento, utilizzando i domini dello strumento Cochrane Risk of Bias). RobotReviewer classifica inoltre l’articolo come se sia a ‘basso’ rischio di bias o meno per ogni dominio di bias.
Gli studi di convalida di RobotReviewer hanno rilevato che le classificazioni di bias dell’articolo (cioè “basso” contro “alto/non chiaro” rischio di bias) sono ragionevoli ma meno accurate di quelle delle recensioni Cochrane pubblicate [12, 15]. Tuttavia, le frasi identificate sono risultate altrettanto rilevanti per le decisioni di bias come quelle contenute nelle recensioni Cochrane[12]. Si raccomanda pertanto di utilizzare il sistema con input manuale; che l’output sia trattato come un suggerimento piuttosto che come una valutazione finale del bias. È disponibile uno strumento web che mette in evidenza il testo che descrive i pregiudizi e suggerisce una decisione sui pregiudizi che mira ad accelerare il processo rispetto alla valutazione dei pregiudizi completamente manuale.
Un ostacolo a modelli migliori per l’estrazione dei dati è stata la mancanza di dati di formazione per il compito. Richiamo dall’alto i sistemi ML si basano su etichette manuali per stimare i parametri del modello. Ottenere etichette su singole parole all’interno dei documenti per addestrare i modelli di estrazione è un esercizio costoso. EXaCT, per esempio, è stato addestrato su un piccolo set (132 in totale) di articoli full-text. RobotReviewer è stato addestrato utilizzando un set di dati molto più grande, ma le ‘etichette’ sono state indotte in modo semi-automatico, utilizzando una strategia nota come ‘supervisione a distanza’ [35]. Ciò significa che le annotazioni usate per l’addestramento erano imperfette, introducendo così il rumore nel modello. Recentemente, Nye et al. hanno rilasciato il dataset EBM-NLP[23], che comprende circa 5000 abstract di rapporti RCT annotati manualmente in dettaglio. Questo può fornire dati di formazione utili per far avanzare i modelli di estrazione automatizzata.
Sintesi
Sebbene esistano da tempo strumenti software che supportano la componente di sintesi dei dati delle revisioni (soprattutto per l’esecuzione di meta-analisi), i metodi per automatizzarla vanno oltre le capacità degli strumenti ML e NLP attualmente disponibili. Ciononostante, la ricerca in queste aree continua rapidamente e i metodi di calcolo possono consentire nuove forme di sintesi non realizzabili manualmente, in particolare per quanto riguarda la visualizzazione[37, 38] e la sintesi automatica[39, 40] di grandi volumi di prove di ricerca.
Conclusioni
Il torrenziale volume di prove pubblicate non strutturate ha reso gli approcci esistenti (rigorosi, ma manuali) alla sintesi delle prove sempre più costosi e poco pratici. Di conseguenza, i ricercatori hanno sviluppato metodi che mirano a semiautomatizzare diversi passaggi della pipeline di sintesi delle prove attraverso l’apprendimento automatico. Questa rimane un’importante direzione di ricerca e ha il potenziale per ridurre drasticamente il tempo necessario per produrre prodotti standard di sintesi delle prove.
Al momento della stesura della presente relazione, la ricerca sull’apprendimento automatico per le revisioni sistematiche ha iniziato a maturare, ma rimangono ancora molti ostacoli al suo uso pratico. Le revisioni sistematiche richiedono una precisione molto elevata nei loro metodi, che può essere difficile da raggiungere per l’automazione. Tuttavia l’accuratezza non è l’unico ostacolo alla completa automazione. In aree con un certo grado di soggettività (per esempio, determinare se una prova è a rischio di distorsioni), i lettori sono più propensi a essere rassicurati dall’opinione soggettiva ma considerata di un esperto umano rispetto ad una macchina. Per queste ragioni, l’automazione completa rimane attualmente un obiettivo lontano. La maggior parte degli strumenti che presentiamo sono progettati come sistemi “umani in loop”: Le loro interfacce utente permettono ai revisori umani di avere l’ultima parola.
La maggior parte degli strumenti che abbiamo incontrato sono stati scritti da gruppi accademici coinvolti nella ricerca sulla sintesi delle prove e sull’apprendimento automatico. Molto spesso, questi gruppi hanno prodotto prototipi di software per dimostrare un metodo. Tuttavia, tali prototipi non invecchiano bene: ci siamo imbattuti comunemente in link web rotti, interfacce utente difficili da capire e lente, ed errori del server.
Per il campo della ricerca, il passaggio dai prototipi di ricerca attualmente disponibili (ad esempio RobotReviewer, ExaCT) a piattaforme con manutenzione professionale rimane un problema importante da superare. Nella nostra esperienza come team accademico in questo settore, le risorse necessarie per la manutenzione di software di livello professionale (comprese le correzioni di bug, la manutenzione dei server e la fornitura di supporto tecnico) sono difficili da ottenere da finanziamenti accademici a tempo determinato, e la durata del software è in genere molte volte più lunga di un periodo di finanziamento a fondo perduto. Tuttavia, è improbabile che le aziende di software commerciali dedichino le proprie risorse all’adozione di questi metodi di apprendimento automatico, a meno che non vi sia una sostanziale richiesta da parte degli utenti.
Tuttavia, per il pionieristico team di revisione sistematica, molti dei metodi descritti possono essere utilizzati ora. Gli utenti dovrebbero aspettarsi di rimanere pienamente coinvolti in ogni fase della revisione e di affrontare alcuni spigoli del software. Le tecnologie di ricerca che accelerano il reperimento di articoli rilevanti (ad esempio schermando i non-RCT) sono i modelli ML qui recensiti in modo più completo e sono più accurati dei filtri di ricerca convenzionali. Gli strumenti per lo screening sono accessibili tramite piattaforme software utilizzabili (Abstrackr, RobotAnalyst e EPPI reviewer) e potrebbero essere usati in modo sicuro ora come secondo screener[31] o per dare priorità agli abstract per la revisione manuale. Gli strumenti per l’estrazione dei dati sono progettati per assistere il processo manuale, ad esempio per attirare l’attenzione dell’utente su testi rilevanti o per dare suggerimenti all’ utente affinché li convalidi o li modifichi, se necessario. Il pilotaggio di alcune di queste tecnologie da parte dei primi utilizzatori (con la dovuta cautela metodologica) è probabilmente il prossimo passo fondamentale per ottenere l’accettazione da parte della comunità.
References
- Bastian H, Glasziou P, Chalmers I. Seventy-five trials and eleven systematic reviews a day: how will we ever keep up?. PLoS Med.. 2010; 7:e1000326. DOI | PubMed
- Allen IE, Olkin I. Estimating time to conduct a meta-analysis from number of citations retrieved. JAMA.. 1999; 282:634-635. DOI | PubMed
- Borah R, Brown AW, Capers PL, Kaiser KA. Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ Open.. 2017; 7:e012545. DOI
- Johnston E. How quickly do systematic reviews go out of date? A survival analysis. J Emerg Med.. 2008; 34:231. DOI
- Tsafnat G., Dunn A., Glasziou P., Coiera E.. The automation of systematic reviews. BMJ. 2013; 346(jan10 1):f139-f139. DOI | PubMed
- O’Connor AM, Tsafnat G, Gilbert SB, Thayer KA, Wolfe MS. Moving toward the automation of the systematic review process: a summary of discussions at the second meeting of International Collaboration for the Automation of Systematic Reviews (ICASR). Syst Rev.. 2018; 7:3. DOI | PubMed
- Thomas J, Noel-Storr A, Marshall I, Wallace B, McDonald S, Mavergames C. Living systematic reviews: 2. Combining human and machine effort. J Clin Epidemiol.. 2017; 91:31-37. DOI | PubMed
- Wallace BC, Dahabreh IJ, Schmid CH, Lau J, Trikalinos TA. Modernizing evidence synthesis for evidence-based medicine. Clinical Decision Support. 2014.
- Jonnalagadda SR, Goyal P, Huffman MD. Automating data extraction in systematic reviews: a systematic review. Syst Rev.. 2015; 4:78. DOI | PubMed
- O’Mara-Eves A, Thomas J, McNaught J, Miwa M, Ananiadou S. Using text mining for study identification in systematic reviews: a systematic review of current approaches. Syst Rev.. 2015; 4:5. DOI | PubMed
- Marshall C, Brereton P. Systematic review toolbox: a catalogue of tools to support systematic reviews. In: Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering: ACM; 2015. p. 23.
- Marshall IJ, Kuiper J, Wallace BC. RobotReviewer: evaluation of a system for automatically assessing bias in clinical trials. J Am Med Inform Assoc.. 2016; 23:193-201. DOI | PubMed
- Goldberg Y, Levy O. word2vec explained: deriving Mikolov et al.’s negative-sampling word-embedding method. 2014.
- Joachims T. Machine learning: ECML-98. Springer Berlin Heidelberg: Berlin, Heidelberg; 1998.
- Zhang Y, Marshall I, Wallace BC. Rationale-augmented convolutional neural networks for text classification. Proc Conf Empir Methods Nat Lang Process.. 2016; 2016:795-804. PubMed
- Marshall Iain J., Noel-Storr Anna, Kuiper Joël, Thomas James, Wallace Byron C.. Machine learning for identifying Randomized Controlled Trials: An evaluation and practitioner’s guide. Research Synthesis Methods. 2018; 9(4):602-614. DOI | PubMed
- Bishop CM. Pattern recognition and machine learning. Springer New York; 2016.
- Sutton C, McCallum A. An introduction to conditional random fields: Now Pub; 2012.
- Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput.. 1997; 9:1735-1780. DOI | PubMed
- Ma X, Hovy E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. Available from: http://dx.doi.org/10.18653/v1/p16-1101
- Lample G, Ballesteros M, Subramanian S, Kawakami K, Dyer C. Neural architectures for named entity recognition. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. Available from: http://dx.doi.org/10.18653/v1/n16-1030
- Patel R, Yang Y, Marshall I, Nenkova A, Wallace BC. Syntactic patterns improve information extraction for medical search. Proc Conf.. 2018; 2018:371-377. PubMed
- Nye B, Jessy Li J, Patel R, Yang Y, Marshall IJ, Nenkova A. A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature. Proc Conf Assoc Comput Linguist Meet.. 2018; 2018:197-207. PubMed
- Wallace BC, Noel-Storr A, Marshall IJ, Cohen AM, Smalheiser NR, Thomas J. Identifying reports of randomized controlled trials (RCTs) via a hybrid machine learning and crowdsourcing approach. J Am Med Inform Assoc.. 2017; 24:1165-1168. DOI | PubMed
- Cohen AM, Smalheiser NR, McDonagh MS, Yu C, Adams CE, Davis JM. Automated confidence ranked classification of randomized controlled trial articles: an aid to evidence-based medicine. J Am Med Inform Assoc.. 2015; 22:707-717. DOI | PubMed
- Soto Axel J, Przybyła Piotr, Ananiadou Sophia. Thalia: semantic search engine for biomedical abstracts. Bioinformatics. 2018; 35(10):1799-1801. DOI
- Incorporating Values for Indexing Method in MEDLINE/PubMed XML. NLM Technical Bulletin. U.S. National Library of Medicine; 2018 [cited 2019 Jan 18]; Available from:Publisher Full Text
- Mork J, Aronson A, Demner-Fushman D. 12 years on – is the NLM medical text indexer still useful and relevant?. J Biomed Semantics.. 2017; 8:8. DOI | PubMed
- Settles Burr. Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. 2012; 6(1):1-114. DOI
- Wallace BC, Small K, Brodley CE, Lau J, Trikalinos TA. Deploying an interactive machine learning system in an evidence-based practice center: Abstrackr. Proceedings of the 2Nd ACM SIGHIT International Health Informatics Symposium. ACM: New York; 2012.
- Shemilt I, Khan N, Park S, Thomas J. Use of cost-effectiveness analysis to compare the efficiency of study identification methods in systematic reviews. Syst Rev.. 2016; 5:140. DOI | PubMed
- Przybyła P, Brockmeier AJ, Kontonatsios G, Le Pogam M-A, McNaught J, von Elm E. Prioritising references for systematic reviews with RobotAnalyst: a user study. Res Synth Methods.. 2018; 9:470-488. PubMed
- Kiritchenko S, de Bruijn B, Carini S, Martin J, Sim I. ExaCT: automatic extraction of clinical trial characteristics from journal publications. BMC Med Inform Decis Mak.. 2010; 10:56. DOI | PubMed
- Marshall IJ, Kuiper J, Banner E, Wallace BC. Automating biomedical evidence synthesis: RobotReviewer. Proc Conf Assoc Comput Linguist Meet.. 2017; 2017:7-12. PubMed
- Wallace BC, Kuiper J, Sharma A, Zhu MB, Marshall IJ. Extracting PICO sentences from clinical trial reports using supervised distant supervision. J Mach Learn Res.. 2016; 17:1-25.
- Pyysalo S, Ananiadou S. Anatomical entity mention recognition at literature scale. Bioinformatics.. 2014; 30:868-875. DOI | PubMed
- Mo Y, Kontonatsios G, Ananiadou S. Supporting systematic reviews using LDA-based document representations. Syst Rev.. 2015; 4:172. DOI | PubMed
- Mu T, Goulermas YJ, Ananiadou S. Data visualization with structural control of global cohort and local data neighborhoods. IEEE Trans Pattern Anal Mach Intell. 2017; Available from: http://dx.doi.org/10.1109/TPAMI.2017.2715806
- Sarker A, Mollá D, Paris C. Query-oriented evidence extraction to support evidence-based medicine practice. J Biomed Inform.. 2016; 59:169-184. DOI | PubMed
- Mollá D, Santiago-Martínez ME. Creation of a corpus for evidence based medicine summarisation. Australas Med J.. 2012; 5:503-506. DOI | PubMed
Fonte
Marshall IJ, Wallace BC (2019) Toward systematic review automation: a practical guide to using machine learning tools in research synthesis. Systematic Reviews 8163. https://doi.org/10.1186/s13643-019-1074-9




